把本程序改造为一个输入一个起始URL及其参数之后就可以下载此URL及其参数所指定的WEB页面以及此WEB页面中HTML语言超级链接所指向的所有WEB页面(只下载一级即可)。
主要需要利用Pattern类方法和正则表达式来获取超链接
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
class HtmlParser1 {
String htmlUrl;
ArrayList<String> hrefList = new ArrayList();
String charSet;
public HtmlParser1(String htmlUrl) {
// TODO 自动生成的构造函数存根
this.htmlUrl = htmlUrl;
}
public ArrayList<String> parser() throws IOException { //获得该网页下的超链接
URL url = new URL(htmlUrl); //创建URL对象,建立连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setDoOutput(true);
String contenttype = connection.getContentType();
charSet = getCharset(contenttype);
InputStreamReader isr = new InputStreamReader(connection.getInputStream(), "gb2312"); //创建输入流
BufferedReader br = new BufferedReader(isr);
String str = null, rs = null;
while ((str = br.readLine()) != null) {
Pattern pattern = Pattern.compile("<a href=(.*?)>"); //识别这一行是否符合网页的格式
Matcher matcher = pattern.matcher(str);
while (matcher.find()) {
Pattern pattern1 = Pattern.compile("\"(.*?)\"");
Matcher matcher1 = pattern1.matcher(matcher.group(1));
if (matcher1.find()) {
rs = matcher1.group(1); //将本行引号中的内容截取出来
}
if (rs.indexOf("http") != -1) { //带http的为URL
if (rs != null)
hrefList.add(rs);
}
}
}
return hrefList;
}
public void getURL() throws IOException { //获得每个超链接对应的web网页
ArrayList<String> URLList = parser();
for (int i = 0; i < URLList.size(); i++) {
URL url = new URL(URLList.get(i)); //读取每个截取的URL
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setDoOutput(true);
InputStreamReader isr = new InputStreamReader(connection.getInputStream(),"gb2312");
BufferedReader br = new BufferedReader(isr);
String str = null;
File dest = new File("wangye/"+i+".html"); //按数字顺序命名保存
dest.createNewFile();
FileOutputStream fileOutputStream = new FileOutputStream(dest);
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(fileOutputStream, "gb2312");
while ((str = br.readLine()) != null) {
outputStreamWriter.write(str); //输出流写入
}
}
}
private String getCharset(String str) { //获取网页编码方式,有些网页没有提供,所以暂时不使用
Pattern pattern = Pattern.compile("charset=.*");
Matcher matcher = pattern.matcher(str);
if (matcher.find())
return matcher.group(0).split("charset=")[1];
return null;
}
}
public class sp312{
public static void main(String[] arg) throws IOException { //主方法
HtmlParser1 HP = new HtmlParser1("https://news.163.com/");
ArrayList<String> hrefList = HP.parser();
for (int i = 0; i < hrefList.size(); i++)
System.out.println(hrefList.get(i));
HP.getURL();
}
}
结果:
截取的超链接
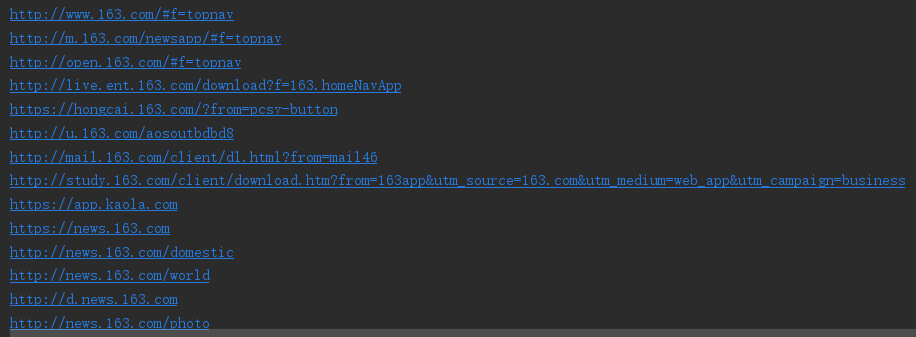
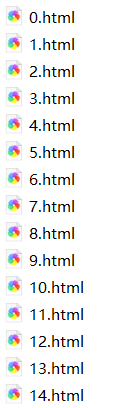
获取的超链接的HTML网页:
