为了得到一致假设而使假设变得过度复杂称为过拟合(overfitting),过拟合表现在训练好的模型在训练集上效果很好,但是在测试集上效果差。也就是说模型的泛化能力弱。在很多问题中,我们费心费力收集到的数据集并不能穷尽所有的状态,而且一般训练得到的模型被用来预测未知数据的结果,模型虽然在训练集上效果很好,但是在实际应用中效果差,就说明这个模型训练的并不是很成功,还需要改进。就譬如下方的图像中,左边黑色直线在一定程度拟合数据排列,而蓝紫色的曲线就是照顾到每一个样本点,曲线弯弯折折,属于过拟合;右边黑色的曲线就能把红蓝两种数据点进行很好的分类,过拟合的绿色虽然在此数据上能完美分开两类数据点,可是对于一个新的数据集,其适应能力远不如黑色的曲线。

下面皮一下,下面的图就生动形象地展示了过拟合问题。

过拟合和机器学习面临的关键障碍,各类学习算法都必然带有一些针对过拟合的措施;然而必须认识到,过拟合是无法彻底避免的,我们所做的只是“缓解”,或者说减少其风险。那么如何解决过拟合?下面介绍几种方法。
1. 数据集扩增(Data Augmentation)
众所周知,更多的数据往往胜过一个更好的模型。就好比盲人摸象,不足够的数据让每个人对大象的认识都不同,学习太过片面。更多的数据能够让模型学习的更加全面,然而,在现实世界中,由于条件的限制,而不能够收集到更多的数据。所以,往往在这个时候,就需要采用一些计算的方式与策略在原有数据集上进行手脚,以获得更多的数据。数据集扩增就是要得到更多符合要求的数据。
在物体分类(object recognition)问题中,数据扩增已经成为一项特殊的有效的技术。物体在图像中的位置、姿态、尺度,整体图片敏感度等都不会影响分类结果,所以我们就可以通过图像平移、翻转、缩放、切割等手段将数据库成倍扩充。或者在语音识别(speech recognition)中,加入噪音也被看做是一种数据扩增方式。
2. 改进模型
过拟合主要有两个原因造成的,数据太少和模型太复杂,数据扩增增加数据量,下面我们通过使用合适复杂度的模型来防止过拟合问题,让其能够学习到真正的规则。对于模型复杂,最简单暴力的做法就是减少网络的层数和神经元的个数,但是一般不是很提倡这种做法,是因为人为并不能很好掌控删减的程度,因此下面介绍几种高效的方法。
2.1 Early Stopping
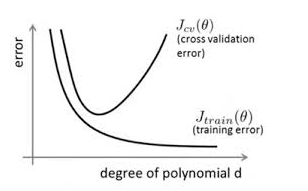
如下图所示,在对模型训练的时候,模型在训练集上的训练误差(training error)随着时间会一直减少,然而模型在验证集上的验证误差会减少到一定程度后逐步上升,形成一个非对称的U型曲线。对模型进行训练的过程即是对模型的参数进行更新的过程,参数更新会用到一些优化算法,为了能够得到最低测试误差时的参数,Early Stopping的做法就是运行优化方法直到若干次在验证集上的验证误差没有提升时候停止。
一般做法是,在训练的过程中,记录到目前为止最好的验证正确率(validation accuracy),当连续10次Epoch,validation accuracy没有达到最佳Accuracy,则认为accuracy不再有所提升,此时就可以停止迭代了。
2.2 正则化(regularization)
损失函数分为经验风险损失函数和结构风险损失函数,结构风险损失函数就是经验损失函数+表示模型复杂度的正则化,正则项通常选择L1或者L2正则化。结构风险损失函数能够有效地防止过拟合。
- L1正则化是指权值向量
中各个元素的绝对值之和,通常表示为
,L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择,一定程度上,L1也可以反之过拟合
- L2化是指权值向量
,L2正则化可以防止模型过拟合
那L1和L2正则化是如何防止过拟合呢?首先我们先明白稀疏参数和更小参数的好处。
稀疏参数(L1):参数的稀疏,在一定程度实现了特征的选择。稀疏矩阵指有很多元素为0,少数参数为非零值。一般而言,只有少部分特征对模型有贡献,大部分特征对模型没有贡献或者贡献很小,稀疏参数的引入,使得一些特征对应的参数是0,所以就可以剔除可以将那些没有用的特征,从而实现特征选择。
更小参数(L2):越复杂的模型,越是尝试对所有样本进行拟合,那么就会造成在较小的区间中产生较大的波动,这个较大的波动反映出在这个区间内的导数就越大。只有越大的参数才可能产生较大的导数。试想一下,参数大的模型,数据只要偏移一点点,就会对结果造成很大的影响,但是如果参数比较小,数据的偏移对结果的影响力就不会有什么影响,那么模型也就能够适应不同的数据集,也就是泛化能力强,所以一定程度上避免过拟合。2.2 正则化(regularization)
假设带有L1正则化的损失函数为:,当我们在
后添加L1正则化项时,相当于对
做了一个约束。此时我们的任务就变成在L1正则化约束下求出
取最小值的解。考虑二维的情况,在有两个权值
和
的情况下,此时L1为
,对于梯度下降方法,求解
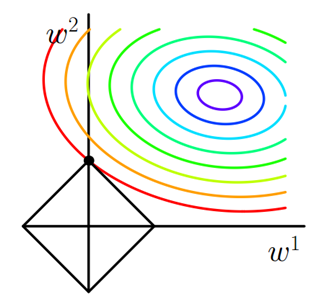
的过程用等值线表示,如下图所示。黑色方形是L1正则化的图形,五彩斑斓的等值线是
的等值线。在图中,
等值线与黑色方形首次相交的地方就是最优解。因为黑色方形棱角分明(二维情况下四个,多维情况下更多),
与这些棱角接触的几率要远大于其他部位接触的概率,而在这些棱角上,会有很多权值为0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
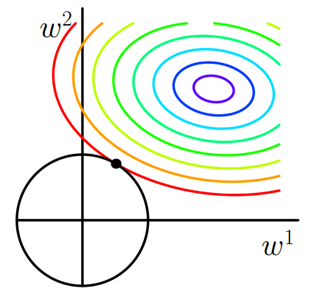
假设带有L2正则化的损失函数为:,类似地,可以得到下图在二维平面上的图形。因为二维L2正则化函数是个圆,与L1的方形相比,圆滑了好多,因此
和L2相交于棱角的几率比较小,而是更多权值取值更小。
2.3 Dropout
在神经网络中,Dropout方法通过修改隐藏层神经元的个数来防止网络的过拟合,也就是通过修改深度网络本身。对于下图中左边的神经网络,在训练过程中按照给定的概率随机删除一些隐藏层的神经元,同时保证输入层和输出层的神经元不变。便能得到左边的神经网络,从而简化复杂的网络。
在每一批次数据被训练时,Dropout按照给定的概率P随机剔除一些神经元,只有没有被剔除也就是被保留下来的神经元的参数被更新。每一批次数据,由于随机性剔除神经元,使得网络具有一定的稀疏性,从而能减轻了不同特征之间的协同效应。而且由于每次被剔除的神经元不同,所以整个网络神经元的参数也只是部分被更新,消除减弱了神经元间的联合适应性,增强了神经网络的泛化能力和鲁棒性。Dropout只在训练时使用,作为一个超参数,然而在测试集时,并不能使用。

当前Dropout被广泛应用于全连接网络,而在卷积层,因为卷积层本身的稀疏性和ReLU激活函数的使用,Dropout在卷积隐藏层中使用较少。
2.4 多任务学习
深度学习中两种多任务学习模式:隐层参数的硬共享和软共享
- 硬共享机制是指在所有任务中共享隐藏层,同时保留几个特定任务的输出层来实现。硬共享机制降低了过拟合的风险。多个任务同时学习,模型就越能捕捉到多个任务的同一表示,从而导致模型在原始任务上的过拟合风险越小。
- 软共享机制是指每个任务有自己的模型,自己的参数。模型参数之间的距离是正则化的,以便保障参数相似性。
