一:四个特性介绍
原子性(Atomicity)
整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性(Consistency)
在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
隔离性(Isolation,又称独立性)
两个事务的执行是互不干扰的,一个事务不可能看到其他事务运行时,中间某一时刻的数据。
持久性(Durability)
在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
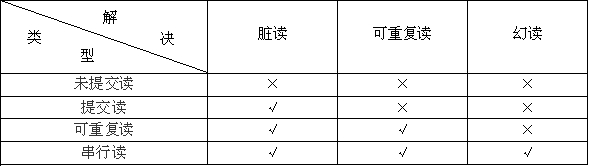
二:理解隔离性相关概念
1)脏读(Dirty Reads):
所谓脏读就是对脏数据(Drity Data)的读取,而脏数据所指的就是未提交的数据。也就是说,一个事务正在对一条记录做修改,在这个事务完成并提交之前,这条数据是处于待定状态的(可能提交也可能回滚),这时,第二个事务来读取这条没有提交的数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被称为脏读。
2)不可重复读(Non-Repeatable Reads):
一个事务先后读取同一条记录,但两次读取的数据不同,我们称之为不可重复读。也就是说,这个事务在两次读取之间该数据被其它事务所修改。
3)幻读(Phantom Reads):
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为幻读。
三:疑问
1.原子性和一致性的区别是什么?如果能够保证原子性,是否就满足了一致性?
当然当然是否定的,如果是这样的,那么其实就没有必要定义一致性的概念了。
小组内也讨论了下:
还是以转账为例,A转给B 1000,假设A原来有1000块,B也有1000块,则A=A-1000; B=B+1000;如果A账户为0之后,此刻读到B为1000,突然B取走了1000,我们还在做操作B=B+1000 B的状态被设置为2000,但是实际B的状态应该为1000,这样也就出现了一致性问题。
网上搜索了很久感觉一个比较靠谱的答案:
数据一致性的一个典型实例为外键约束。例如,在外键约束时,首先更新父表中的主键,如果在子表中有数据与该父表记录相关联,那么父表的更新将被终止。同样地,如果试图更新子表的外键列,也会造成更新失败。因为这两个动作都破坏了数据的一致性。无论哪种操作,如果成功执行,都会使数据库中的数据处于逻辑上的不可接受状态。此时的数据一致性的保持,是在出现在语句级,即每条DML语句都会进行校验。 而事务可以包含多条语句,并可以在事务开始执行时将约束设置为延迟校验。以外键约束为例,可以成功避开无法更新父表主键和子表外键的尴尬。但是,提交时,延迟校验将生效,以保持数据一致性。