前言:
实时计算必将在越来越多的业务场景下得以应用,故而有意学习一番。主要参考《Storm分布式 实时计算模式》一书第1章节《分布式单词记数》。
一、要做的事
像mapreduce程序练手时常常用会word count 来演示,这里也用这个需求来演示storm实时计算。即是说,有一个消息源会源源不断地产生一些句子,然后最终的输出结果是所有句子中每个单词的词频统计。
本文中,我们开发一个本地模式的storm程序,并在IDE中编译运行,以形成对storm结构、主要思想的领会。
二、storm程序的框架
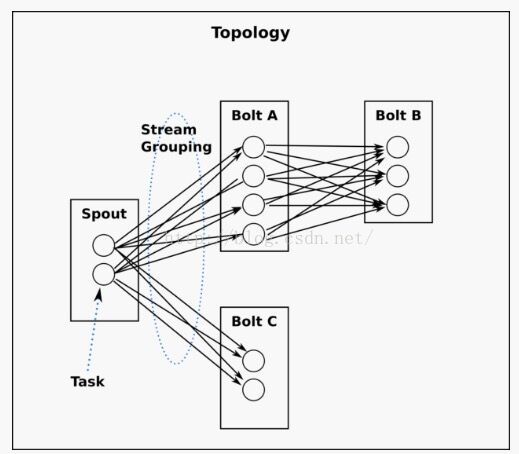
这张图就是精髓了! 我们的storm程序中,将会依次包含上述几种对象,spout是消息产生源头,会源源不断地发送消息给出bolt. 每个bolt对象可以定义若干计算逻辑,就相当于spark中的一种算子一样。在下面的案例程序中,每个对象都将对应有一个类文件。
要实现本文目标,我们的思路是: 产生句子(由spout实现) -> 分词(由bolt实现) -> 词频统计(由bolt实现) -> 报告数据(由bolt实现)
三、开发环境搭建
笔者使用Intellij IDEA作为集成开发工具。通过创建maven工程,配置以下依赖来导入所需的storm JAR包。
groupId: org.apache.storm
artifactId: storm-core
version: 1.0.1此外,为了最终在IDEA中直接运行程序,笔者还从官网(http://storm.apache.org/downloads.html)下载了storm 1.0.1 的已编译文件。并将其中lib目录下的jar包全部导入IDEA中(注意在运行时,可能提示有些配置存在多重配置源,按提示删除相应的jar包即可)

四、案例代码开发
先上图说明下笔者的IDE中工程的样子:

各个类的代码如下:
SentenceSpout.java
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.Map;
public class SentenceSpout extends BaseRichSpout{
private SpoutOutputCollector collector;
private String[] sentences = {
"this is line one",
"this is line two",
"tencent is the greatest company in China",
"qq is the most amazing software in the market"
};
private int index = 0;
public void declareOutputFields(OutputFieldsDeclarer declarer){
declarer.declare(new Fields("sentence"));
}
public void open(Map config, TopologyContext context, SpoutOutputCollector collector){
this.collector = collector;
}
public void nextTuple(){
this.collector.emit(new Values(sentences[index]));
index++;
if(index >= sentences.length){
index = 0;
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}SplitSentenceBolt.java
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Map;
public class SplitSentenceBolt extends BaseRichBolt{
private OutputCollector collector;
public void prepare(Map config, TopologyContext context, OutputCollector collector){
this.collector = collector;
}
public void execute(Tuple tuple){
String sentence = tuple.getStringByField("sentence");
String[] words = sentence.split(" ");
for(String word:words){
this.collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer){
declarer.declare(new Fields("word"));
}
}WordCountBolt.java
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
public class WordCountBolt extends BaseRichBolt {
private OutputCollector collector;
private HashMap<String, Long> counts = null;
public void prepare(Map config, TopologyContext context, OutputCollector collector){
this.collector = collector;
this.counts = new HashMap<String, Long>();
}
public void execute(Tuple tuple){
String word = tuple.getStringByField("word");
Long count = this.counts.get(word);
if(count == null){
count = 0L;
}
count ++;
this.counts.put(word,count);
this.collector.emit(new Values(word, count));
}
public void declareOutputFields(OutputFieldsDeclarer declarer){
declarer.declare(new Fields("word","count"));
}
}ReportBolt.java
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.util.*;
public class ReportBolt extends BaseRichBolt {
private HashMap<String, Long> counts = null;
public void prepare(Map config, TopologyContext context, OutputCollector collector){
this.counts = new HashMap<String, Long>();
}
public void execute(Tuple tuple){
String word = tuple.getStringByField("word");
Long count = tuple.getLongByField("count");
this.counts.put(word,count);
}
public void declareOutputFields(OutputFieldsDeclarer declarer){
//this bolt does not emit anything
}
public void cleanup(){
System.out.println("--- FINAL COUNTS ---");
List<String> keys = new ArrayList<String>();
keys.addAll(this.counts.keySet());
Collections.sort(keys);
for(String key: keys){
System.out.println(key + ":" + this.counts.get(key));
}
System.out.println("-------------------");
}
}WordCountTypology.java
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class WordCountTypology {
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main(String[] args) throws InterruptedException {
// 定义typology的组成部分
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(SENTENCE_SPOUT_ID, spout);
builder.setBolt(SPLIT_BOLT_ID,splitBolt).shuffleGrouping(SENTENCE_SPOUT_ID);
builder.setBolt(COUNT_BOLT_ID, countBolt).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLT_ID);
Config config = new Config();
config.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
// waitForSeconds(60);
try {
Thread.sleep(1000*5);
} catch (InterruptedException e) {
e.printStackTrace();
}
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
}
}最终的输出如下图所示:

到此, 我们算是上手了第一个storm程序,初步认识了一下这玩意是怎么个结构,为今后深入学习打下基础。