requests是一个强大的网络请求库,简单易用-让 HTTP 服务人类。可以参考这个网站的介绍:http://cn.python-requests.org/zh_CN/latest/index.html
直接使用pip install requests安装此模块之后,开始吧。
一、网络请求和响应
常用的请求方式有以下几种:
- GET请求获取URL位置的资源
- HEAD请求获取URL位置的资源的头部信息
- POST请求想URL位置的资源后附加新的数据
- PUT覆盖原URL位置的资源
- PATCH请求局部更新URL位置的资源,即改变该处资源的部分内容
- DELETE请求删除该URL位置的资源
这些方式在python的requests库中提供了全面的支持。
1、get
基本的get请求:
# encoding=utf-8
import requests
r = requests.get('https://github.com/timeline.json')
print(r.text)同理我们可以得到其他方式的请求:
r2 = requests.post("http://httpbin.org/post")
r3 = requests.delete("http://httpbin.org/delete")
r4 = requests.head("http://httpbin.org/get")
r5 = requests.options("http://httpbin.org/get")任何时候调用
requests.*()你都在做两件主要的事情。其一,你在构建一个 Request 对象, 该对象将被发送到某个服务器请求或查询一些资源。其二,一旦 requests 得到一个从 服务器返回的响应就会产生一个 Response 对象。该响应对象包含服务器返回的所有信息, 也包含你原来创建的 Request 对象。
带参数的get请求:
# encoding=utf-8
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get("http://httpbin.org/get", params=payload)
print(r.text)这里通过一个字典,向请求的网址中传参。可以通过print(r.url)确认网址已被正确的编码为http://httpbin.org/get?key1=value1&key2=value2
requests库的两个重要对象:request(请求)、response(响应)。
上面我们用的是request对象的get方法,及带参数的get方法。获取了响应内容之后,就可以调用response对象的一些方法来获取响应的相关信息了。
r #response对象
r.status_code #状态码
r.text #请求返回的正文
r.url #请求的URL
r.content #二进制响应内容
r.apparent_encoding #从响应中分析出来的编码格式
r.json() #内置的json解析器,将响应解析成json# encoding=utf-8
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get("http://httpbin.org/get", params=payload)
print(r.json())上面代码演示了json解析返回的内容,可以看到返回为:{'args': {'key1': 'value1', 'key2': 'value2'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Connection': 'close', ...(省略)
HTTP状态码:
2xx 用来表示请求成功
206 部分内容 (Partial Content),如果一个应用只请求某范围之内的文件,那么就会返回206.
3xx来表示重定向
如,301 表示Moved Permanently,This and all future requests should be directed to the given URI
4xx用来表示客户端请求出现问题
403 Forbidden,404 Not Found等等
5xx 用来表示服务器出现问题
如,503 Service Unavailable,服务端过载、维护中等等……
从这里可以获取到更详细的信息:https://en.wikipedia.org/wiki/List_of_HTTP_status_codes
2、定制请求头
如果你想为请求添加 HTTP 头部,只要简单地传递一个 dict 给 headers 参数就可以了。HTTP Headers是HTTP请求和相应的核心,它承载了关于客户端浏览器,请求页面,服务器等相关的信息。可以通过Chrome的开发者工具来查看header信息:
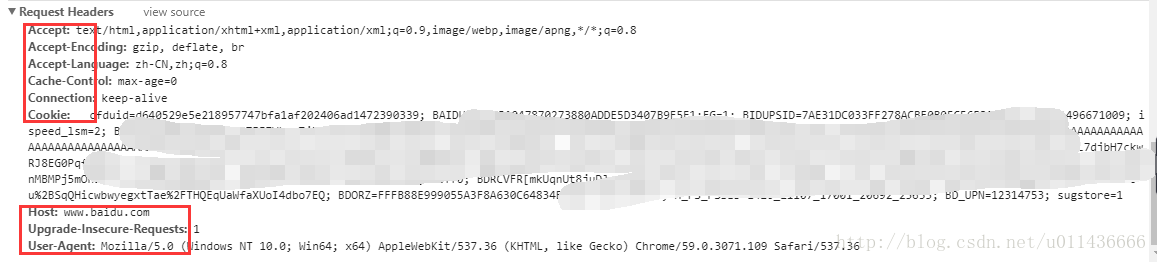

User-Agent:
携带如下几条信息:浏览器名和版本号、操作系统名和版本号、默认语言;是某些网站用来收集访客信息的一般手段。如上图中的Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36。
Accept-Language:
如上面的Accept-Language: zh-CN,zh;q=0.8,说明用户的默认语言设置。如果网站有不同的语言版本,那么就可以通过这个信息来重定向用户的浏览器。它可以通过逗号分割来携带多国语言。第一个会是首选的语言,其它语言会携带一个“q”值,来表示用户对该语言的喜好程度(0~1)。
Cookie:
会发送你浏览器中存储的Cookie信息给服务器,内容中用分号来分割一组键值对。
在requests中使用headers也很简单,如下构造了一个简单的headers:
headers = {'user-agent': 'my-app/0.0.1'}
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get("http://httpbin.org/get", params=payload, headers=headers)使用 r.headers来访问返回的服务器响应头:
#返回的是字典形式的headers
print(r.headers)
>>>{'Connection': 'keep-alive', 'Server': 'meinheld/0.6.1', 'Date': 'Fri, 30 Jun 2017 08:13:17 GMT', 'Content-Type': 'application/json', 'Access-Control-Allow-Origin': '*', ...(省略)同时我们可以访问其中的某一项信息,可以用以下两种方式:
print(r.headers.get("Date")) #获取date信息
print(r.headers["Server"]) #获取Server信息
#输出如下:
#Fri, 30 Jun 2017 08:15:40 GMT
#meinheld/0.6.13、会话对象
会话对象让你能够跨请求保持某些参数。它也会在同一个 Session 实例发出的所有请求之间保持 cookie,期间使用 urllib3 的 connection pooling 功能。所以如果你向同一主机发送多个请求,底层的 TCP 连接将会被重用,从而带来显著的性能提升。
看下面一个简单示例:
import requests
#构造会话对象
s = requests.Session()
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
#注意这里更换了请求
r = s.get("http://httpbin.org/cookies")
print(r.text)
#打印出的仍然是我们在第一个请求里面写入的cookies
#'{"cookies": {"sessioncookie": "123456789"}}'会话级别的参数和方法级别的参数:
这里要区分一下上面两个概念,我们直接通过会话对象的属性设置的参数叫做会话级别的参数,如可以设置s.headers、s.cookies等等;而通过方法(如get方法中设置headers等)设置的参数叫做方法级别的参数。
- 方法层的参数覆盖会话的参数。
- 就算使用了会话,方法级别的参数也不会被跨请求保持。
看看下面这个简单的例子:
# encoding=utf-8
import requests
s = requests.Session()
r = s.get('http://httpbin.org/cookies', cookies={'from-my': 'browser'})
print(r.text)
r = s.get('http://httpbin.org/cookies')
print(r.text)输出为:
{
"cookies": {
"from-my": "browser"
}
}
{
"cookies": {}
}可以看见,方法级别的参数没有被跨请求保持!