用久了scikitlearn,突然换回weka各种不适应
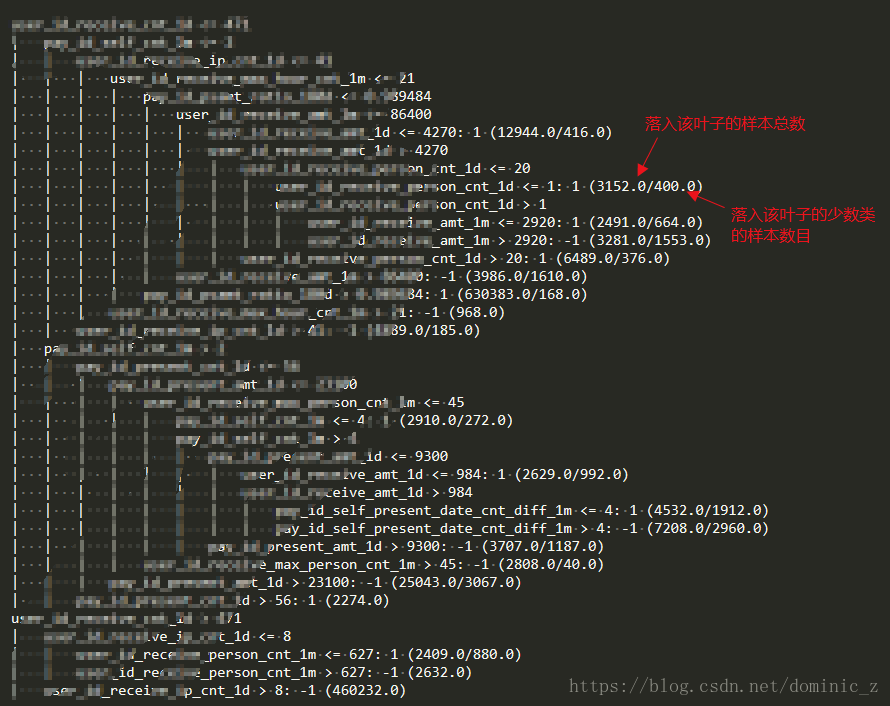
weka的tree分类器输出的树后面的括号的含义
调用API对样本进行分类
在分类问题中,当调用如下代码对testInstance进行分类,输出的是一个double,预测的结果是一个index,假设预测结果为0.0
double index = classifier.classifyInstance(testInstance)
假如训练arff文件中的label字段是如下
@attribute label {1,-1}
那么index=0.0的意思就是:模型预测结果为1
又假如训练arff文件中的label字段是如下
@attribute label {-1,1}
那么index=0.0的意思就是:模型预测结果为-1
distributionForInstance函数同理,输出的double[]代表后验概率,与训练集中的类标签顺序是一一对应的
虽然这两个函数的输出不会受到测试数据集的影响,但假如你的训练数据中的label字段是如下
@attribute label {1,-1}
而测试数据的Instances对象的label字段是如下
@attribute label {-1,1}
并且假如此时index=0.0,也就是说模型预测的类为1
double index = classifier.classifyInstance(testInstance)
但是下面的代码并不会把testInstance的类设置为1,而是会设置为-1,因为下面的代码会受到Instances对象的label字段的顺序影响
testInstance.setClassValue(classifier.classifyInstance(testInstance))