1.员工的重要性
难度:简单
给定一个保存员工信息的数据结构,它包含了员工唯一的id,重要度 和 直系下属的id。
比如,员工1是员工2的领导,员工2是员工3的领导。他们相应的重要度为15, 10, 5。那么员工1的数据结构是[1, 15, [2]],员工2的数据结构是[2, 10, [3]],员工3的数据结构是[3, 5, []]。注意虽然员工3也是员工1的一个下属,但是由于并不是直系下属,因此没有体现在员工1的数据结构中。
现在输入一个公司的所有员工信息,以及单个员工id,返回这个员工和他所有下属的重要度之和。
示例 1:
输入: [[1, 5, [2, 3]], [2, 3, []], [3, 3, []]], 1
输出: 11
解释:
员工1自身的重要度是5,他有两个直系下属2和3,而且2和3的重要度均为3。因此员工1的总重要度是 5 + 3 + 3 = 11。
注意:
一个员工最多有一个直系领导,但是可以有多个直系下属
员工数量不超过2000。
思路:很明显,该题用深度优先搜索可以解决,即员工的重要性取决于他本身和下属员工的重要性,那么只需要知道下属员工的重要度即可,利用递归很容易求解。
/*
// Employee info
class Employee {
public:
// It's the unique ID of each node.
// unique id of this employee
int id;
// the importance value of this employee
int importance;
// the id of direct subordinates
vector<int> subordinates;
};
*/
class Solution {
public:
int getImportance(vector<Employee*> employees, int id) {
int totalDegree=0;
totalDegree=getImpDegree(employees,id,totalDegree);
return totalDegree;
}
int getImpDegree(vector<Employee*> employees,int id,int &totalDegree){
Employee* targetEmployee;
for(int j=0;j<employees.size();j++){
if(employees[j]->id==id){ //从容器中搜索对应id的Employee的数组
targetEmployee=employees[j];
}
}
totalDegree+=targetEmployee->importance;
if(targetEmployee->subordinates.size()==0) return targetEmployee->importance; //递归的边界条件
for(int i=0;i<targetEmployee->subordinates.size();i++){
int impDegree=getImpDegree(employees,targetEmployee->subordinates[i],totalDegree); //依次得到下属员工的重要度
}
return totalDegree;
}
};
2. N叉树的最大深度
难度:简单
给定一个 N 叉树,找到其最大深度。
最大深度是指从根节点到最远叶子节点的最长路径上的节点总数。
例如,给定一个 3叉树 :
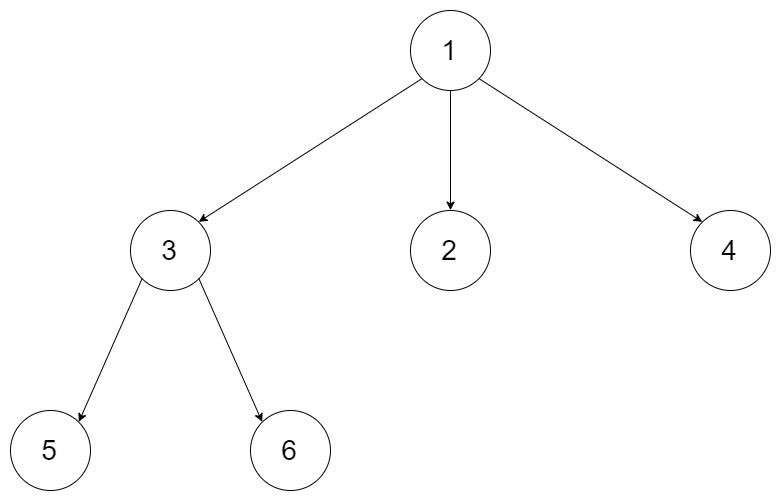
说明:
树的深度不会超过 1000。
树的节点总不会超过 5000。
思路:其实该题跟获得二叉树的最大深度类似,用递归实现深度优先搜索,注意边界条件。
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
class Solution {
public:
int maxDepth(Node* root) {
if(root==NULL) return 0;
int maxDepth=getMaxDepth(root);
return maxDepth;
}
int getMaxDepth(Node* root){
if(root->children.size()==0) {return 1;}
int MaxDepth=0;
for(int i=0;i<root->children.size();i++){
int tempDepth=getMaxDepth(root->children[i]);
if(MaxDepth<tempDepth+1){
MaxDepth=tempDepth+1;
}
}
return MaxDepth;
}
};
3. 叶子相似的树
难度:简单
请考虑一颗二叉树上所有的叶子,这些叶子的值按从左到右的顺序排列形成一个 叶值序列 。
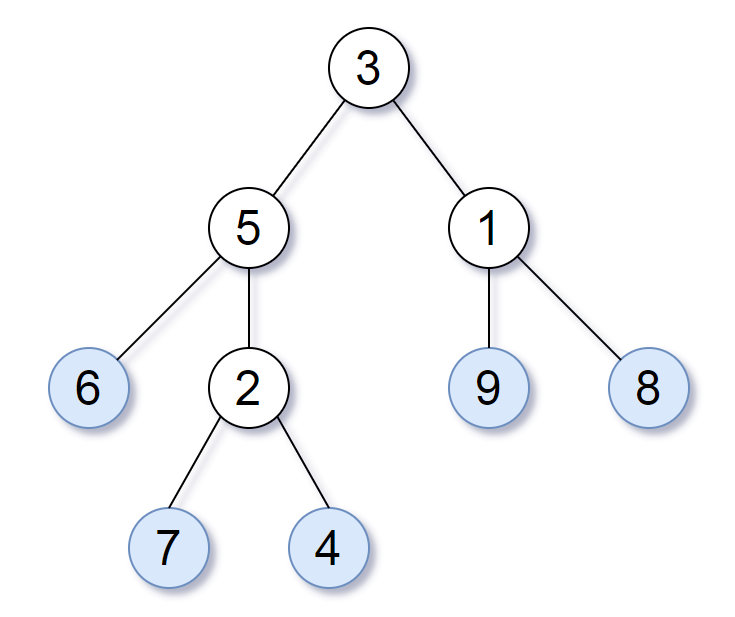
举个例子,如上图所示,给定一颗叶值序列为 (6, 7, 4, 9, 8) 的树。
如果有两颗二叉树的叶值序列是相同,那么我们就认为它们是 叶相似 的。
如果给定的两个头结点分别为 root1 和 root2 的树是叶相似的,则返回 true;否则返回 false 。
提示:
给定的两颗树可能会有 1 到 100 个结点。
思路:用俩个容器存储俩颗树中的叶子值,然后对比俩个容器是否相等即可,该题主要考深度优先搜索和树。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool leafSimilar(TreeNode* root1, TreeNode* root2) {
vector<int> root1Leaf=getLeaf(root1);
vector<int> root2Leaf=getLeaf(root2);
return root1Leaf==root2Leaf;
}
vector<int> getLeaf(TreeNode* root){
vector<int> allLeaf;
stack<TreeNode*> stack;
while(root!=NULL || !stack.empty()){
while(root){
stack.push(root);
if(root->left==NULL && root->right==NULL){
allLeaf.push_back(root->val);
}
root=root->left;
}
if(!stack.empty()){
root=stack.top()->right;
stack.pop();
}
}
return allLeaf;
}
};