1.为什么非阻塞网络编程中应用层buffer是必须的
非阻塞I/O(在这里可以理解为非阻塞I/O加T/O复用)的核心思想就是避免将当前线程阻塞在I/O系统调用上,这样可以使我们的I/O线程只阻塞在I/O复用函数上(epoll_wait或poll,select)使其能够服务更多的连接socket那么如何才能做到这一点呢?这里我们就需要实现应用层的输入输出buffer
(1)什么情况下用到output buffer?
假设我们要通过TCP连接来发送100k的数据,在执行write()时,操作系统受某些因素的影响只接受了70k数据,那么由于还剩20k我们该如何处理?是等待内核腾出空间来接受余下的20k?那如果等很久杂么办?难道我们的事件循要在你的等待时间内什么都做不成么?针对以上的问题我们就可以用一个应用层的write buffer来解决,把那些暂时内核无法接受的数据先存在buffer中,然后注册POLLOUT事件,一单该socket可写了,我们就把缓存中的数据写进去,如果下次还写不完那么就继续注册POLLOUT事件下次继续写,如果buffer中的数据还没写完,程序又来了数据,那么此时的数据就应该直追加到buffer数据尾部中。有了应用层的write buffer后我们的程序就完全不用关心数据到底一次能不能发完,这些都有网络库来操心
(2)什么 情况下用到input buffer?
我们在处理socket可读事件时,必须一次把socket数据读完,否则就会反复触发POLLIN事件(这里所述针对epoll的LT模式),造成主循环busy-loop,但是话又说回来,我们如果一次把socket的数据都读完,就没法保证具体某条消息的完整性了。那么我们的网络库该杂么做呢?我们的网络库因该先把读到的内容存在input buffer中,等input buffer中有完整的消息了,在通知业务程序,这样就可提高速度
2.buffer 的功能设计
(1)muduo buffer的设计要点
.对外表现为一块连续的内存
.其大小可自动增长,以适应不断增长的消息,它不能是固定大小的buffer
.内部以std::vector来保存数据,并提供相应的访问函数
.input buffer,是程序从socket中读取数据然后写入input buffer,客户代码从input buffer读取数据
.output buffer,客户代码会把数据写入output buffer中,然后再从output buffer中读取数据并写入socket中
muduo buffer类的主要数据成员
//vector用来保存数据
std::vector<char> buffer_;
//读位置的下标
size_t readerIndex_;
//写位置的下标
size_t writerIndex_;上述数据成员作用注释的也挺清楚的,唯一值得说明的是,之所以将读写下标设为size_t类型,是因为如果把它们设为指针类型,那么当vector进行插入删除时都有可能让其失效。
muduo buffer类的主要对外接口
//当前buffer中可读的字节数
readableBytes();
//向buffer中添加数据
append();
交换俩个buffer;
//swap();
//从套接字读取数据到buffer
readFd();(2)buffer的初始值该如何设定呢?
设计这样一个buffer我们应该给它多少初始值大小呢?一方面我们希望减少系统调用,一次读的数据越多越好,这种情况下我们的buffer应该给的越大越好。另一方面我们希望我们可以尽量减少内存的占用,如果把buffer设的很大的话,当连接数很大时,将会占用很大的空间,所以针对这种情况,我们设计的buffer当然应该越小越好?
那么我们究竟该如何在上述俩种矛盾的需求中寻找一种好的折中办法呢?
muduo库的buffer的初始大小方面可以说用了一个非常巧妙的方法,其具体代码是read_Fd函数,具体如下
在栈中开辟一个65536字节的extrabuf,然后利用readv这个系统调用来读取数据,readv的iovec有俩块,第一块指向buffer(buffer初始大小为1024)中的可写字节段,另一块指向栈上的extrabuf,根据readv的特性可知,当读入的数据小于buffer的可写字节时,数据将全部存在buffer中,否则buffer满了之后,extrabuf保存剩下的部分,然后在将其中的数据append到buffer中(增大了buffer大小),之后readFd函数结束,extrabuf的栈空间也就被释放了
大家可能读到这时会有一定的疑问,extrabuf的数据随即就要加入到buffer中,这和直接把buffer设大又有什么区别呢?你可以这样想,我们在读socket时的时候是并不知道数据的大小的,所以我们才不好设值buffer的大小,因此我们征用了栈(零时空间)帮助我们完成socket读操作之后我们就明确知道了有多少数据了,所以在需要多大空间我们就给buffer加多少空间,之后栈的零时空间就会随着readFd函数的结束而销毁。
ps:一定要抓住buffer是堆空间,而extrabuf只是暂时存在的栈空间来理解这里的设计思想
readFd函数内容如下
ssize_t Buffer::readFd(int fd,int *savedErrno)
{
//栈额外空间,用于从套接字往出来读时,当buffer暂时不够用时暂存数据,待buffer重新分配足够空间后,在把数据交换给buffer
char extrabuf[65536];
struct iovec vec[2];
const size_t writable = writableBytes();
vec[0].iov_base = begin() + ::writerIndex_;
vec[0].iov_len = writable;
vec[1].iov_base = extrabuf;
vec[1].iov_len = sizeof(extrabuf);
//当vector够用时不用栈空间
const int iovcnt = (writable < sizeof(extrabuf)) ? 2 : 1;
const ssize_t n = sockets::readv(fd,vec,iovcnt);
if(n < 0)
{
*savedErrno = errno;
}
else if(implicit_cast<size_t>(n) <= writable)
{
writerIndex_ += n;
}
else
{
writerIndex_ = buffer_.size();
//将额外空间的部分加到buffer中去
append(extrabuf,n - writable);
}
return n;
}3.buffer的数据结构
(1)buffer中各变量的含义及简单操作
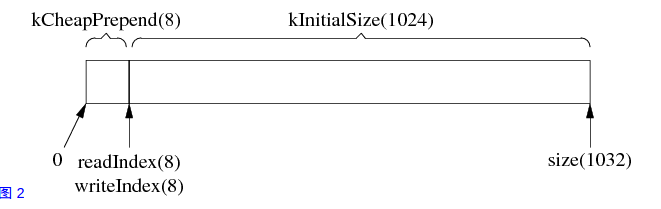
muduo的buffer结构初始时如下图
图片来源与陈硕博客
如上图所示,在初始化的1024空间中,第0到8个字节(kCheapPrepend所示区域)为预留空间,它可以让我们以很低的代价在程序的前面添加几个字节,剩下的部分为读写区域,
其中readIndex指向可读区域的起始位置,writeIndex指向可写区域的起始位置,它俩的初始位置都在预留空间之后即8之后,当我们向该buffer中添加200数据时,如下图
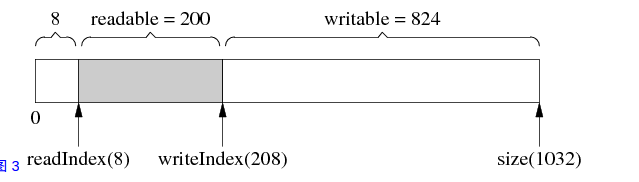
从上图易看出可读位置任然是8,由于新增加了200数据,可写位置也就要相应的后移200个位置,如上图writeIndex = 208
当我们从上图中的buffer中取走50数据时,如下图所示
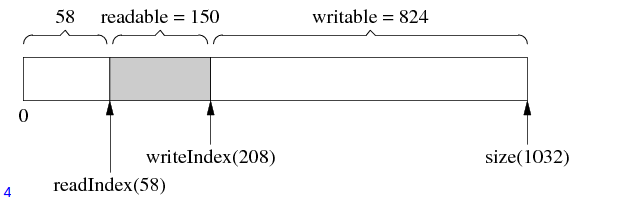
由于已经取走了50数据,所以readIndex的位置也就要后移50个位置,此时预留空间增大了50字节
根据上述的具体操作,我们不能总结出,prependable(预存空间),readable(可读空间),writable(可写空间)的定义
prependable = readIndex
readable = writeIndex - readIndex
writable = size() - writeIndex(2)buffer的自动增长
muduo中的buffer是不定长的,它可以自动增长,具体如下
假如初始buffer如下
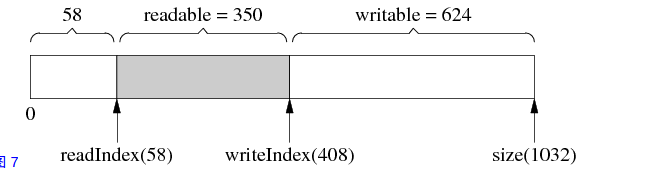
当我们再向buffer中添加1000数据时,buffer会变为下图

具体变化过程代码如下
void makeSpace(size_t len) //增大vector
{
if(writableBytes() + prependableBytes() < len + kCheapPrepend) //可写空间和移动中腾出的空间是否小于写入长度和预留空间的长度和
{
//说明缓存空间真是不够不够用了
buffer_.resize(writerIndex_ + len);
}
else
{
assert(kCheapPrepend < readerIndex);
size_t readable = readableBytes();
//将现有数据腾挪到kCheapPrepend位置
std::copy(begin() + readerIndex_,
begin() + writerIndex_,
begin() + kCheapPrepend);
readerIndex_ = kCheapPrepend;
writerIndex_ = readerIndex_ + readable;
assert(readable == readableBytes());
}
}上述增大buffer的具体过程如下:
首先判断当预留空间加可写空间小于待写入长度和基本预留长度kCheapPrepend时,则说明当前buffer确实没有空间了,此时我么需要调用resize加大vector的空间大小。否则,说明当前只是可写空间不足待写入长度大小,但是可写空间和预留空间的总大小要比上述判断的len + kCheapPrepend大,之所以表现为空间不够,只是预留空间没有被利用而已,所以我们只需要将buffer中的数据区域(readIndex到writerIndex)移动到基本预留空间(buffer的第8个位置即可)