版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_41550842/article/details/83547199
我们写代码有时候会出现这种情况:在自己电脑上运行的很正常,字符显示很完美,把自己的代码给别人或者换台机器运行,就会出现乱码的现象,这是为什么呢?都是编码方式在作祟,不同的机器或java项目可能使用的默认编码不同。
如何查看eclipse 中java项目的编码方式:

如图右击项目名称,然后选择propertices选项,就可以了
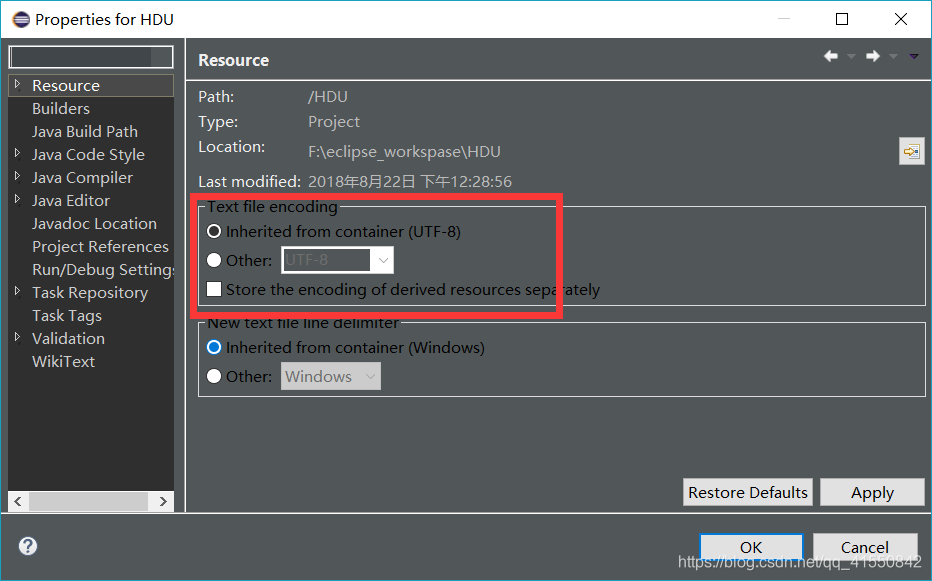
我的这个项目的默认编码方式是utf-8 ,下面对java的编码方式总结一下,记录一下:
import java.io.UnsupportedEncodingException;
public class EncodeDemo {
public static void main(String[] args) throws UnsupportedEncodingException{
String s = "我爱ABC";
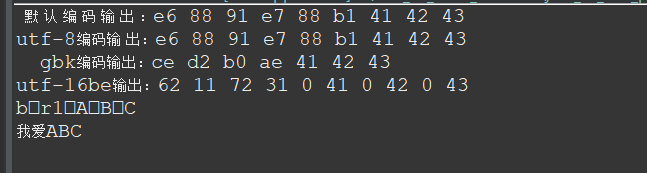
byte[] byte1 = s.getBytes();//以系统默认的编码方式转换为字节流
System.out.print(" 默 认 编 码 输 出 :");
for(byte b : byte1){
System.out.print(Integer.toHexString(b & 0xff) + " ");
}
System.out.print("\nutf-8编码输 出:");
byte[] byte2 = s.getBytes("utf-8");//以utf-8的编码转换
for(byte b : byte2){
System.out.print(Integer.toHexString(b & 0xff) + " ");
}
/*
* 以上两个输出说明该工程使用的默认编码是utf-8
* 该编码格式一个汉字栈占用三个字节,英文字母占用一个字节
*/
System.out.print("\n gbk编码输出:");
byte[] byte3 = s.getBytes("gbk");
for(byte b : byte3){
System.out.print(Integer.toHexString(b & 0xff) + " ");
}
/*
* gbk编码格式,中文占两个字节,英文字母占一个字节
*/
System.out.print("\nutf-16be输出:");
/*
* java使用的双字节编码(utf-16be)
* 中文英文都是两个字节
*/
byte[] byte4 = s.getBytes("utf-16be");
for(byte b : byte4){
System.out.print(Integer.toHexString(b & 0xff) + " ");
}
/*
* 当我们吧utf-16be编码格式的byte4转换为数组时,不指定编码方式,而是使用
* 项目默认编码方式,发现打印出来的是乱码,之后将编码方式改为上面utf-16be的
* 格式再打印发现没有乱码。同理,如果我们想将byte3转换为字符串再输出,则需要
* 使用对应的gbk的编码方式,这样才不会乱码
*/
System.out.println();
String s1 = new String(byte4);//使用项目默认的编码(utf-8)
System.out.println(s1);
String s2 = new String(byte4,"utf-16be");
System.out.println(s2);
}
}
代码中b & 0xff 操作是为了去掉整数高24位多余的0,因为我们知道一个字节8位,而int是四个字节,所以byte转换为int后就变成了32位,但高24位都是0,影响视觉效果,所以用这个操作把它去掉就好了。输出结果如下图: