环境:win10,anaconda3(python3.5)
爬取对象网站:链家上海租房
方法一:利用requests获取网页信息,再利用正则提取数据,并将结果保存到csv文件。
代码地址:代码
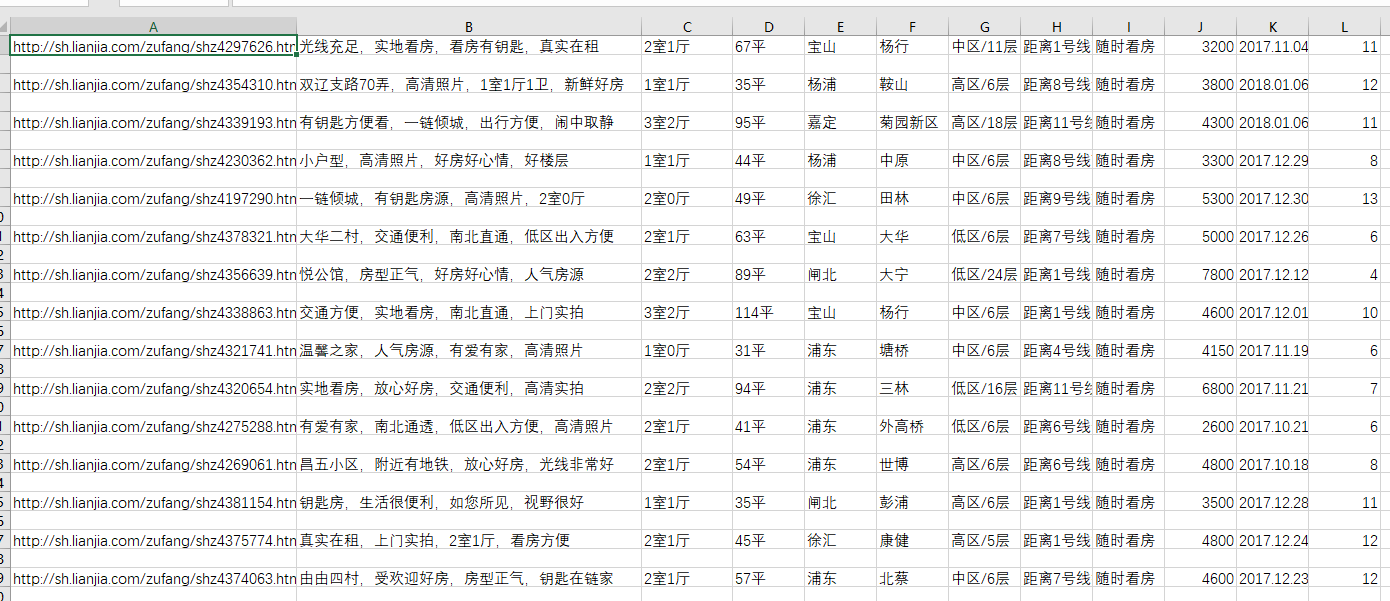
抓取到的数据如下所示:
从左往右依次是:房屋链接、房屋描述、房屋布局、房屋大小、所在区、所在区的具体区域、房屋楼层数、交通信息、看房时间、房租(/月)、上架时间以及当前有多少人看过该房屋。
方法二:利用requests获取网页信息,再用BeautifulSoup解析数据,并用MongoDB保存结果。
主要爬取的数据有:房屋链接、房屋描述、小区、户型、面积,所在区域、房租、交通信息、多少人看过等。

链家只提供100页数据,所以只爬取这100页数据。
审查元素发现每个li标签就是一个房源

而在每个li标签中,房屋信息全在class=info-panel中,所以class=info-panel中的数据即为我们需要抓取的数据块。
用BeautifulSoup解析数据,
soup = BeautifulSoup(html, 'lxml')
for item in soup.select('.info-panel'):
一个个装载数据即可
houseUrl = item.find("h2").a["href"]
title = item.find("h2").a["title"]
。。。。
然后将抓取好的数据,存入数据库。
先为每个item生成一个链表:
yield {
'_id': id,
'houseUrl': houseUrl,
'houseDescription': title,
'xiaoqu': xiaoqu,
'huxing': huxing,
'mianji': mianji,
'area': area,
'sub_area': sub_area,
'traffic': subway,
'price': price,
'data': data,
'watchedPersons': watched
}
初始化设置MongoDB(windows配置MongoDB移步至:win10 配置MongoDB以及可视化工具Robo 3T)
client = pymongo.MongoClient('mongodb://localhost:27017')
db_name = 'lianjia_zufang_shanghai'
db = client[db_name]
collection_set01 = db['set01']
再依次将数据存入数据库中
for item, index in parse_one_page(html, index):
collection_set01.save(item)
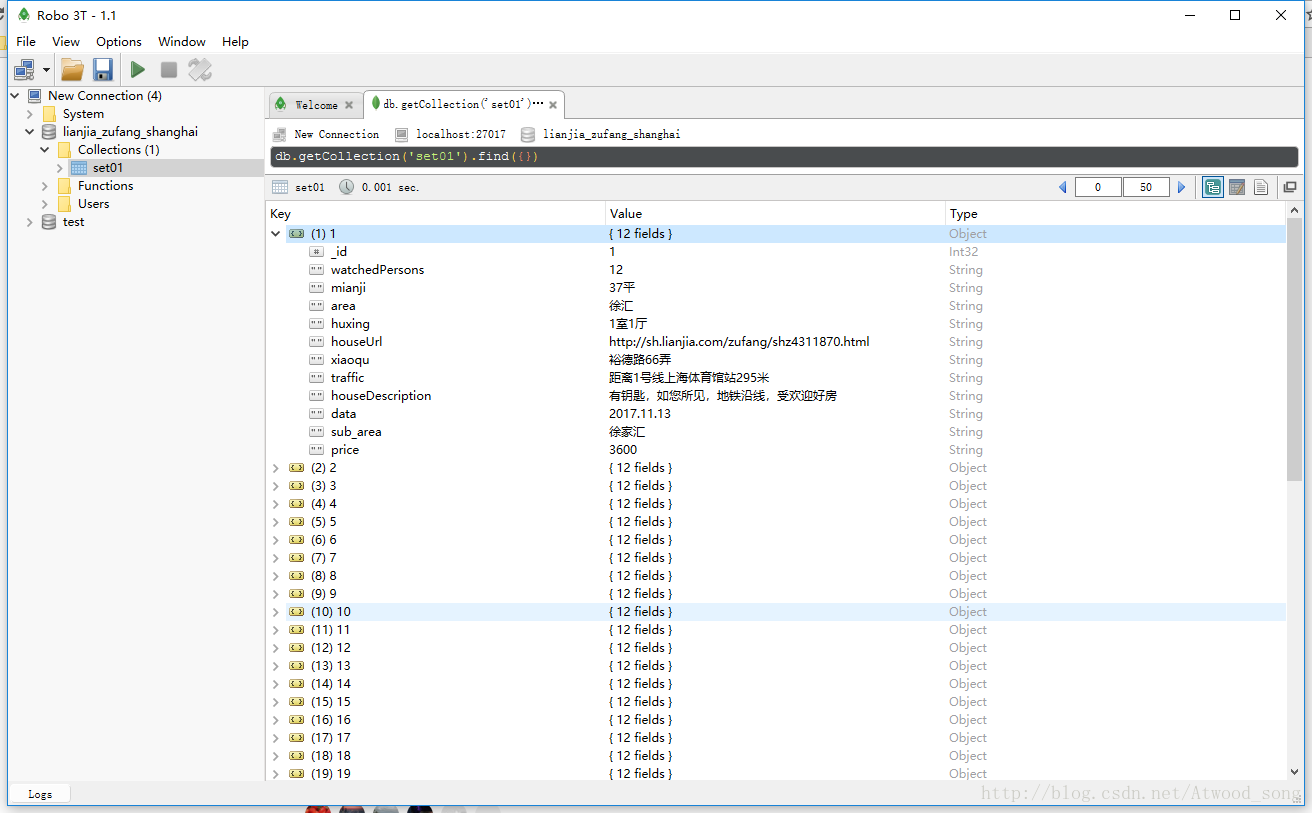
保存到数据库中的数据如下:
完整代码:代码
总之就是写好自己的model类,所有数据一股脑捣鼓进去,然后save。
只是个爬虫小程序,代码写得比较简单,只是能跑起来而已。