一、基本概念
1. 音频简介
数码音频系统是通过将声波波形转换成一连串的二进制数据来再现原始声音的,
实现这个步骤使用的设备是模/数转换器(A/D)它以每秒上万次的速率对声波进行采样,
每一次采样都记录下了原始模拟声波在某一时刻的状态,称之为样本。
将一串的样本连接起来,就可以描述一段声波了,把每一秒钟所采样的数目称为采样频率或采率,单位为HZ(赫兹)。
采样频率越高所能描述的声波频率就越高。
采样率决定声音频率的范围(相当于音调),可以用数字波形表示。
以波形表示的频率范围通常被称为带宽。
要正确理解音频采样可以分为采样的位数和采样的频率。
1.1 采样的位数
采样位数可以理解为采集卡处理声音的解析度。这个数值越大,解析度就越高,录制和回放的声音就越真实。
我们首先要知道:电脑中的声音文件是用数字0和1来表示的。
连续的模拟信号(加窗截断)按一定的采样频率经数码脉冲取样后,每一个离散的脉冲信号被以一定的量化精度量化成一串二进制编码流,
这串编码流的位数即为采样位数,也称为量化精度。
从码率的计算公式中可以清楚的看出码率和采样位数的关系:
码率=取样频率×量化精度×声道数。
在电脑上录音的本质就是把模拟声音信号转换成数字信号。
反之,在播放时则是把数字信号还原成模拟声音信号输出。
采集卡的位是指采集卡在采集和播放声音文件时所使用数字声音信号的二进制位数。
采集卡的位客观地反映了数字声音信号对输入声音信号描述的准确程度。
8位代表2的8次方--256,16位则代表2的16次方--64K。
比较一下,一段相同的音乐信息,16位声卡能把它分为64K个精度单位进行处理,而8位声卡只能处理256个精度单位。
8位采样的差别在于动态范围(维基百科:动态范围(英语:dynamic range)是可变化信号(例如声音或光)最大值和最小值的比值。
也可以用以10为底的对数(分贝)或以2为底的对数表示。)的宽窄,动态范围宽广,音量起伏的大小变化就能够更精细的被记录下来,
如此一来不论是细微的声音或是强烈的动感震撼,都可以表现的淋漓尽致,而CD音质的采样规格正式16位采样的规格。
16位二进制数的最小值是0000000000000000,最大值是1111111111111111,
对应的十进制数就是0和65535,也就是最大和最小值之间的差值是65535,
也就是说,它量化的模拟量的动态范围可以差65535,也就是96.32分贝,
所以,量化精度只和动态范围有关,和频率响应没关系。
动态范围定在96分贝也是有道理的,人耳的无痛苦极限声压是90分贝,96分贝的动态范围在普通应用中足够使用,
所以96分贝动态范围内的模拟波,经量化后,不会产生削波失真的。
声音的位数就相当于画面的颜色数,表示每个取样的数据量,当然数据量越大,回放的声音越准确,
不至于把开水壶的叫声和火车的鸣笛混淆。
同样的道理,对于画面来说就是更清晰和准确,不至于把血和西红柿酱混淆。
不过受人的器官的机能限制,16位的声音和24位的画面基本已经是普通人类的极限了,更高位数就只能靠仪器才能分辨出来了。
比如电话就是3kHZ取样的7位声音,而CD是44.1kHZ取样的16位声音,所以CD就比电话更清楚。
如今市面上所有的主流产品都是16位的采集卡,而并非有些无知商家所鼓吹的64位乃至128位,
他们将采集卡的复音概念与采样位数概念混淆在了一起。
如今功能最为强大的采集卡系列采用的EMU10K1芯片虽然号称可以达到32位,
但是它只是建立在Direct Sound加速基础上的一种多音频流技术,其本质还是一块16位的声卡。
应该说16位的采样精度对于电脑多媒体音频而言已经绰绰有余了。
很多人都说,就算从原版CD抓轨,再刻录成CD,重放的音质也是不一样的,这个也是有道理的
,那么,既然0101这样的二进数是完全克隆的,重放怎么会不一样呢?
那是因为,时基问题造成的数模互换时的差别,并非是克隆过来的二进制数变了,
二进制数一个也没变,时基误差不一样,数模转换后的模拟波的频率和源相比就会有不一样。
1.2 采样的频率
采样频率是指录音设备在一秒钟内对声音信号的采样次数,采样频率越高声音的还原就越真实越自然。
在当今的主流采集卡上,采样频率一般共分为22.05KHz、44.1KHz、48KHz三个等级,
22.05 KHz只能达到FM广播的声音品质,
44.1KHz则是理论上的CD音质界限,
48KHz则更加精确一些。
对于高于48KHz的采样频率人耳已无法辨别出来了,所以在电脑上没有多少使用价值。
5kHz的采样率仅能达到人们讲话的声音质量。
11kHz的采样率是播放小段声音的最低标准,是CD音质的四分之一。
22kHz采样率的声音可以达到CD音质的一半,目前大多数网站都选用这样的采样率。
44kHz的采样率是标准的CD音质,可以达到很好的听觉效果。
采样率类似于动态影像的帧数,
比如电影的采样率是24赫兹,PAL制式的采样率是25赫兹,NTSC制式的采样率是30赫兹。
当我们把采样到的一个个静止画面再以采样率同样的速度回放时,看到的就是连续的画面。
同样的道理,把以44.1kHZ采样率记录的CD以同样的速率播放时,就能听到连续的声音。
显然,这个采样率越高,听到的声音和看到的图像就越连贯。
当然,人的听觉和视觉器官能分辨的采样率是有限的。
对同一段声音,用20kHz和44.1kHz来采样,重放时,可能可以听出其中的差别,
而基本上高于44.1kHZ采样的声音,比如说96kHz采样,绝大部分人已经觉察不到两种采样出来的声音的分别了。
之所以使用44.1kHZ这个数值是因为经过了反复实验,人们发现这个采样精度最合适,
低于这个值就会有较明显的损失,而高于这个值人的耳朵已经很难分辨,而且增大了数字音频所占用的空间。
一般为了达到“万分精确”,我们还会使用48k甚至96k的采样精度,
实际上,96k采样精度和44.1k采样精度的区别绝对不会象44.1k和22k那样区别如此之大,我们所使用的CD的采样标准就是44.1k。
1.3 位速
位速是指在一个数据流中每秒钟能通过的信息量。
您可能看到过音频文件用 “128–Kbps MP3” 或 “64–Kbps WMA” 进行描述的情形。
Kbps 表示 “每秒千位数”,因此数值越大表示数据越多:
128–Kbps MP3 音频文件包含的数据量是 64–Kbps WMA 文件的两倍,并占用两倍的空间。
(不过在这种情况下,这两种文件听起来没什么两样。
原因是什么呢?有些文件格式比其他文件能够更有效地利用数据, 64–Kbps WMA 文件的音质与 128–Kbps MP3 的音质相同。)
需要了解的重要一点是,位速越高,信息量越大,对这些信息进行解码的处理量就越大,文件需要占用的空间也就越多。
为项目选择适当的位速取决于播放目标:
如果您想把制作的 VCD 放在 DVD 播放器上播放,那么视频必须是 1150 Kbps,音频必须是 224 Kbps。
典型的 206 MHz Pocket PC 支持的 MPEG 视频可达到 400 Kbps—超过这个限度播放时就会出现异常。
1.4 VBR
VBR(Variable Bitrate)动态比特率。
也就是没有固定的比特率,压缩软件在压缩时根据音频数据即时确定使用什么比特率。
这是Xing发展的算法,他们将一首歌的复杂部分用高Bitrate编码,简单部分用低Bitrate编码。
主意虽然不错,可惜Xing编码器的VBR算法很差,音质与CBR相去甚远。
幸运的是, Lame完美地优化了VBR算法,使之成为MP3的最佳编码模式。这是以质量为前提兼顾文件大小的方式,推荐编码模式。
ABR(Average Bitrate)平均比特率,是VBR的一种插值参数。
Lame针对CBR不佳的文件体积比和VBR生成文件大小不定的特点独创了这种编码模式。
ABR也被称为“Safe VBR”,它是在指定的平均Bitrate内,以每50帧(30帧约1秒)为一段,低频和不敏感频率使用相对低的流量,高频和大动态表现时使用高流量。
举例来说,当指定用192kbps ABR对一段wav文件进行编码时,Lame会将该文件的85%用192kbps固定编码,然后对剩余15%进行动态优化:
复杂部分用高于192kbps 来编码、简单部分用低于192kbps来编码。
与192kbps CBR相比,192kbps ABR在文件大小上相差不多,音质却提高不少。
ABR编码在速度上是VBR编码的2到3倍,在128-256kbps范围内质量要好于CBR。
可以做为 VBR和CBR的一种折衷选择。
CBR(Constant Bitrate),常数比特率,指文件从头到尾都是一种位速率。
相对于VBR和ABR来讲,它压缩出来的文件体积很大,但音质却不会有明显的提高。
对MP3来说Bitrate是最重要的因素,它用来表示每秒钟的音频数据占用了多少个bit(bit per second,简称bps)。这个值越高,音质就越好。
1. 5 MP3
MP3的全称应为MPEG1 Layer-3音频文件,
MPEG(Moving Picture Experts Group)在汉语中译为活动图像专家组,特指活动影音压缩标准,
MPEG音频文件是MPEG1标准中的声音部分,也叫MPEG音频层,
它根据压缩质量和编码复杂程度划分为三层,即Layer-1、Layer2、Layer3,
且分别对应MP1、MP2、MP3这三种声音文件,并根据不同的用途,使用不同层次的编码。
MPEG音频编码的层次越高,编码器越复杂,压缩率也越高,MP1和MP2的压缩率分别为4:1和6:1-8:1,
而MP3的压缩率则高达 10:1-12:1,也就是说,一分钟CD音质的音乐,未经压缩需要10MB的存储空间,
而经过MP3压缩编码后只有1MB左右。不过MP3对音频信号采用的是有损压缩方式,为了降低声音失真度,
MP3采取了“感官编码技术”,即编码时先对音频文件进行频谱分析,
然后用过滤器滤掉噪音电平,接着通过量化的方式将剩下的每一位打散排列,
最后形成具有较高压缩比的MP3文件,并使压缩后的文件在回放时能够达到比较接近原音源的声音效果。
(另MP3PRO: mp3PRO编码器将音频的录音分成两个部分:mp3部分和PRO部分。
mp3部分分析低频段(Low Frequency Band)信息,并将其编码成通常的mp3文件数据流。
这就使得编码器能够集中编码更少的有用信息,获得更佳品质的编码效果。
同时,这也保证了 mp3PRO文件同老的mp3播放器的兼容性。
PRO部分分析的则是高频段(High Frequency Band)信息,并将其编码成mp3数据流的一部分,
而这些通常在老的mp3解码器里是被忽略的。
新的mp3PRO解码器会有效地利用这部分数据流,将两段(高频段和低频段)合并起来产生完全的音频带,达到增强音质的效果。
1.6 音频格式的描述
经常见到这样的描述: 44100HZ 16bit stereo 或者 22050HZ 8bit mono 等等.
44100HZ 16bit stereo: 每秒钟有 44100 次采样, 采样数据用 16 位(2字节)记录, 双声道(立体声);
22050HZ 8bit mono : 每秒钟有 22050 次采样, 采样数据用 8 位(1字节)记录, 单声道;
当然也可以有 16bit 的单声道或 8bit 的立体声, 等等。
采样率 : 是指声音信号在“模→数”转换过程中单位时间内采样的次数。
采样值: 是指每一次采样周期内声音模拟信号的积分值。
对于单声道声音文件,采样数据为八位的短整数(short int 00H-FFH);
而对于双声道立体声声音文件,每次采样数据为一个16位的整数(int),高八位(左声道)和低八位(右声道)分别代表两个声道。
人对频率的识别范围是 20HZ - 20000HZ, 如果每秒钟能对声音做 20000 个采样, 回放时就足可以满足人耳的需求.
所以 22050 的采样频率是常用的, 44100已是CD音质, 超过48000的采样对人耳已经没有意义。
这和电影的每秒 24 帧图片的道理差不多。
每个采样数据记录的是振幅, 采样精度取决于储存空间的大小:
1 字节(也就是8bit) 只能记录 256 个数, 也就是只能将振幅划分成 256 个等级;
2 字节(也就是16bit) 可以细到 65536 个数, 这已是 CD 标准了;
4 字节(也就是32bit) 能把振幅细分到 4294967296 个等级, 实在是没必要了.
如果是双声道(stereo), 采样就是双份的, 文件也差不多要大一倍.
这样我们就可以根据一个 wav 文件的大小、采样频率和采样大小估算出一个 wav 文件的播放长度。
譬如 ,
"Windows XP 启动.wav" 的文件长度是 424,644 字节, 它是 "22050HZ / 16bit / 立体声" 格式(这可以从其 "属性->摘要" 里看到),
那么它的每秒的传输速率(位速, 也叫比特率、取样率)是 22050*16*2 = 705600(bit/s),
换算成字节单位就是 705600/8 = 88200(字节/秒),
播放时间:424644(总字节数) / 88200(每秒字节数) ≈ 4.8145578(秒)。
但是这还不够精确,
包装标准的 PCM 格式的 WAVE 文件(*.wav)中至少带有 42 个字节的头信息, 在计算播放时间时应该将其去掉,
所以就有:(424644-42) / (22050*16*2/8) ≈ 4.8140816(秒). 这样就比较精确了.
关于声音文件还有一个概念: "位速", 也有叫做比特率、取样率,
譬如上面文件的位速是 705.6kbps 或 705600bps, 其中的 b 是 bit, ps 是每秒的意思;
压缩的音频文件常常用位速来表示, 譬如达到 CD 音质的 MP3 是: 128kbps / 44100HZ.
2. PCM数据格式
2.1 What is PCM?
PCM(Pulse-code-modulation), 也被称为 脉码编码调制。
是模拟信号以固定的采样频率转换成数字信号后的表现形式。
PCM中的声音数据没有被压缩,通常以五个数据来描述一个PCM数据,播放一个PCM文件就需要这五个数据。
Sample Rate :
采样频率单位为:Hz。采样频率越高,音频质量越好,占用空间也越大。
Sign :
音频数据是否是有符号的。通常情况下都是有符号的。若是将有符号的数据当做无符号的数据来处理将会使声音听来很刺
Sample Size :
表示每一个采样数据的大小。通常该值为16-bit。
Byte Ordering :
字节序指的是little-endian还是big-endian。表示音频数据的存储字节序。通常均为little-endian。
Number of Channels :
标识音频是单声道(mono,1 channel)还是立体声(stereo,2 channels)。
PCM数据的存储,如图所示:
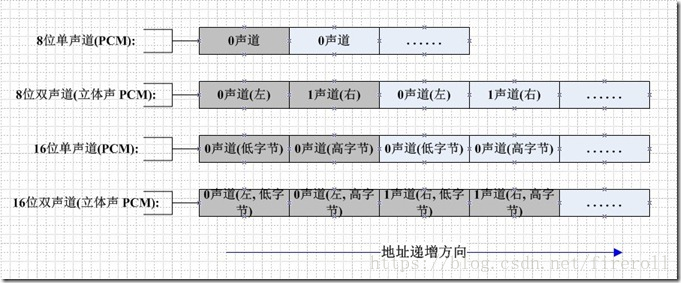
PCM的每个样本值包含在一个整数i中,i的长度为容纳指定样本长度所需的最小字节数。
这样8位和16位的PCM波形样本的数据格式如下所示。
样本大小 数据格式 最小值 最大值
8位PCM unsigned int 0 225
16位PCM int -32767 32767
2.2. What does a PCM stream look like?
单声道:
+------+------+------+------+------+------+------+------+------+
| 500 | 300 | -100 | -20 | -300 | 900 | -200 | -50 | 250 |
+------+------+------+------+------+------+------+------+------+
每个整数占据2个字节(16-bit),9个采样也就是18字节的数据。
每个采样的整数大小最小为 -32768,最大为 32768 。
根据采样数据的位置和值画一个图的话,就会得到像播放器上那样的波浪形图。
我们可以像下面伪代码示例这样将数据读入一个C语言数组 :
FILE *pcmfile
int16_t *pcmdata;
pcmfile = fopen(your pcm data file);
pcmdata = malloc(size of the file);
fread(pcmdata, sizeof(int16_t), size of file / sizeof(int16_t), pcmfile);
如果我们将这些数据送入声卡,我们就可以听到声音。
当然我们需要告诉声卡这些数据的采样率。
若我们告知声卡的采样率大于数据本身的采样率,那么这些数据的播放速度会高于其原始的速度。就是快放的功能。
立体声:
+----------+----------+---------+----------+---------+----------+---------+----------+----------+
| LFrame1 | RFrame1 | LFrame2 | RFrame2 | LFrame3 | RFrame3 | LFrame4 | RFrame4 | LFrame5 |
+----------+----------+---------+----------+---------+----------+---------+----------+----------+
每一个frame是一个16-bit的采样点。左右声道的数据交叉存放。
2.3. Basic Audio Effects – Volume Control
现在让我们来看一下一些真实的波形图。最简单的就是正弦波了。

我们将波形的振幅扩大五倍,图形如下:
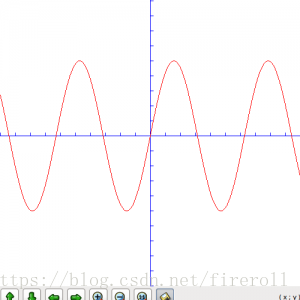
所以如果要增加PCM数据的音量,只需要将每一个采样的数据乘以一个系数就行了。
如果我们的PCM数据有2048个字节,则包含了1024个采样。我们用如下的伪代码来扩大音量 :
int16_t pcm[1024] = read in some pcm data;
for (ctr = 0; ctr < 1024; ctr++) {
pcm[ctr] *= 2;
}
音量控制就是这么简单,但是要注意两点:
若采样点的数据乘以扩大系数之后的值 小于 -32768 或 大于 32768 ,则此处采样的数值只能取 -32768 或 32768
int16_t pcm[1024] = read in some pcm data;
int32_t pcmval;
for (ctr = 0; ctr < 1024; ctr++) {
pcmval = pcm[ctr] * 2;
if (pcmval < 32767 && pcmval > -32768) {
pcm[ctr] = pcmval
} else if (pcmval > 32767) {
pcm[ctr] = 32767;
} else if (pcmval < -32768) {
pcm[ctr] = -32768;
}
}
我们将采样点的数据乘以2并不代表将声音的音量扩大了两倍,事实上也的确如此。
声音音量的增益系数与音量的关系如图:
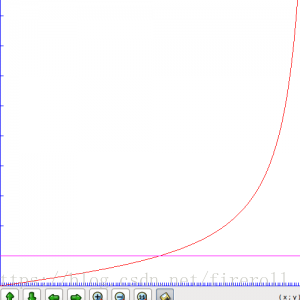
以上内容翻译自:http://www.ypass.net/blog/2010/01/pcm-audio-part-3-basic-audio-effects-volume-control/
2.4. How to change PCM Sample Rate
根据定义,Sample Rate表示每秒钟的采样个数,
所以若是要改变音频的采样频率,我们只需要对采样点做适当的丢弃或者复制就可以。
比如:原始音频为opus编码,单声道,采样率为48kHz,采样点大小为16-bit。
如何得到编码为speex,采样率为16kHz,采样大小为16-bit的音频?
我们需要以下几步:
Step1: 将opus解码为PCM格式数据(叫做PCM1),此时的PCM1的采样率为48kHz
Step1: 取PCM1的数据中第 3*n(n为从0开始的自然数) 个位置的采样点,丢弃3*n+1 和3*n+2位置的采样点。
得到PCM2,此时的PCM2采样率为48kHz / 3 = 16kHz
Step1: 将PCM2编码为speex数据
2.5 如何改变位深
采样位数可以理解为采集卡处理声音的解析度。
这个数值越大,解析度就越高,录制和回放的声音就越真实。
我们首先要知道:电脑中的声音文件是用数字0和1来表示的。
连续的模拟信号(加窗截断)按一定的采样频率经数码脉冲取样后,每一个离散的脉冲信号被以一定的量化精度量化成一串二进制编码流,
这串编码流的位数即为采样位数,也称为量化精度。
从码率的计算公式中可以清楚的看出码率和采样位数的关系:码率=取样频率×量化精度×声道数。
在电脑上录音的本质就是把模拟声音信号转换成数字信号。
反之,在播放时则是把数字信号还原成模拟声音信号输出。
采集卡的位是指采集卡在采集和播放声音文件时所使用数字声音信号的二进制位数。
采集卡的位客观地反映了数字声音信号对输入声音信号描述的准确程度。
8位代表2的8次方--256,16位则代表2的16次方--64K。
比较一下,一段相同的音乐信息,16位声卡能把它分为64K个精度单位进行处理,而8位声卡只能处理256个精度单位。
8位采样的差别在于动态范围(维基百科:动态范围(英语:dynamic range)是可变化信号(例如声音或光)最大值和最小值的比值。
也可以用以10为底的对数(分贝)或以2为底的对数表示。)的宽窄,动态范围宽广,音量起伏的大小变化就能够更精细的被记录下来,
如此一来不论是细微的声音或是强烈的动感震撼,都可以表现的淋漓尽致,而CD音质的采样规格正式16位采样的规格。
音频的一个采样用几个bit来表示,叫采样精度,又叫位深(bit-depth)。
我们常用的位深是16bit,也就是16bit表达一个采样,这样,最高信噪比可以表示为20log(2^16)=96db,
而用24bit位深的话,最高信噪比可以到达20log(2^24)=144db。
专业的数字音频处理软件内部其实都是用float型来表示一个采样,也就是32bit,那么最高信噪比可以达到193db,这个信噪比已经非常高了。
我们需要达到的目标,比如达到业界vivo的codec cs4398信噪比120db,这个只需要24bit就能在理论上提供了可行性。
对于MP3等有损格式,无论压缩前的pcm数据是24bit还是16bit的,压缩过程中都会尽量使用最小bit-depth来存储数据,
因此解码时的bit-depth理论上时没有意义的。
但是工程上讲,使用24bit解码器的mp3,解码时进行加减乘除运算的精度变大,从而能提高一些信噪比。
为了方便处理,通常会把24bit放入一个32bit int,怎么放呢?
跟容器类型和机器大小端有关系。
比如WAV容器,它存储是小端的,这样,存储 0xAA BB CC 这个24bit的采样就需要存成:
CC BB AA (---地址从低到高--->)
为了转化为 int32_t 进行处理,需要把它的高位填充到一个 int32_t 型数中的高位,而最低 8位补零,最终得到 0xAABBCC00 。
由于arm 也是小端的,内存中应该是这样的布局:
00 CC BB AA (---地址从低到高--->)
位深变化的示意图如下:
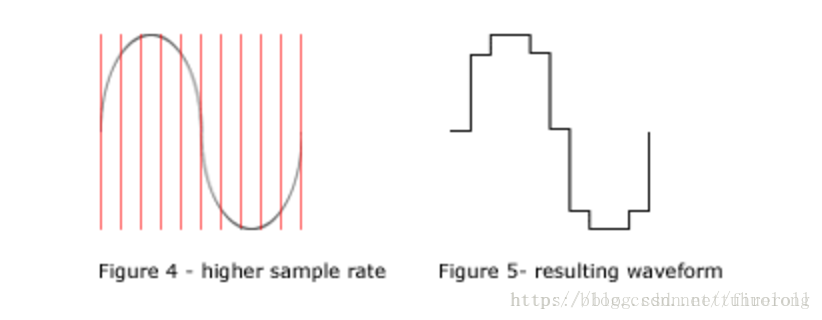
低采样率和低位深
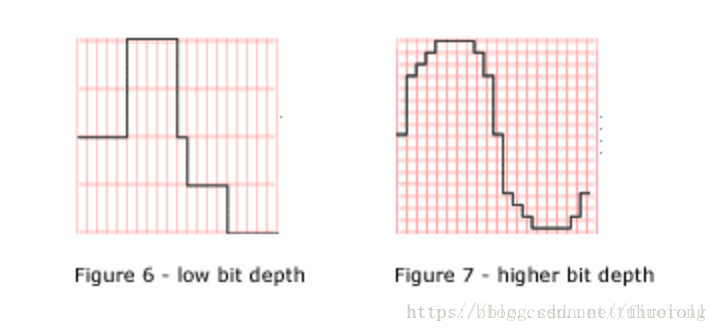
高采样率和高位深
二、FFmpeg中的音频处理
1. 获取pcm音频帧声道数
AVCodecContext->channels
avframe->channels
printf("av_frame_get_channels = %d\n",av_frame_get_channels(frame));
1.1 声道与布局具有映射关系
通过
av_get_channel_layout_nb_channels()和
av_get_default_channel_layout()
这些函数可以得到channels和channellayout的转换。
libavutil中的audioconvert.c定义channellayout和channels的相关map:
channel_layout_map[]
{ "mono", 1, AV_CH_LAYOUT_MONO },
{ "stereo", 2, AV_CH_LAYOUT_STEREO },
{ "2.1", 3, AV_CH_LAYOUT_2POINT1 },
{ "3.0", 3, AV_CH_LAYOUT_SURROUND },
{ "3.0(back)", 3, AV_CH_LAYOUT_2_1 },
{ "4.0", 4, AV_CH_LAYOUT_4POINT0 },
{ "quad", 4, AV_CH_LAYOUT_QUAD },
{ "quad(side)", 4, AV_CH_LAYOUT_2_2 },
{ "3.1", 4, AV_CH_LAYOUT_3POINT1 },
{ "5.0", 5, AV_CH_LAYOUT_5POINT0_BACK },
{ "5.0(side)", 5, AV_CH_LAYOUT_5POINT0 },
{ "4.1", 5, AV_CH_LAYOUT_4POINT1 },
{ "5.1", 6, AV_CH_LAYOUT_5POINT1_BACK },
{ "5.1(side)", 6, AV_CH_LAYOUT_5POINT1 },
{ "6.0", 6, AV_CH_LAYOUT_6POINT0 },
{ "6.0(front)", 6, AV_CH_LAYOUT_6POINT0_FRONT },
{ "hexagonal", 6, AV_CH_LAYOUT_HEXAGONAL },
{ "6.1", 7, AV_CH_LAYOUT_6POINT1 },
{ "6.1", 7, AV_CH_LAYOUT_6POINT1_BACK },
{ "6.1(front)", 7, AV_CH_LAYOUT_6POINT1_FRONT },
{ "7.0", 7, AV_CH_LAYOUT_7POINT0 },
{ "7.0(front)", 7, AV_CH_LAYOUT_7POINT0_FRONT },
{ "7.1", 8, AV_CH_LAYOUT_7POINT1 },
{ "7.1(wide)", 8, AV_CH_LAYOUT_7POINT1_WIDE },
{ "octagonal", 8, AV_CH_LAYOUT_OCTAGONAL },
{ "downmix", 2, AV_CH_LAYOUT_STEREO_DOWNMIX, },
2. 获取pcm音频帧每个声道的sample采样点个数
frame_->nb_samples
3 获取pcm音频帧物理存放方式
3.1 获取解码之后的pcm音频帧物理存放方式
frame->format
3.2 ffmpeg支持的音频帧的物理存放方式
Audio sample formats.
- The data described by the sample format is always in native-endian order. Sample values can be expressed by native C types, hence the lack of a signed 24-bit sample format even though it is a common raw audio data format.
- The floating-point formats are based on full volume being in the range [-1.0, 1.0]. Any values outside this range are beyond full volume level.
- The data layout as used in av_samples_fill_arrays() and elsewhere in FFmpeg (such as AVFrame in libavcodec) is as follows:
For planar sample formats, each audio channel is in a separate data plane, and linesize is the buffer size, in bytes, for a single plane. All data planes must be the same size. For packed sample formats, only the first data plane is used, and samples for each channel are interleaved. In this case, linesize is the buffer size, in bytes, for the 1 plane.
| Enumerator |
|
| AV_SAMPLE_FMT_NONE |
|
| AV_SAMPLE_FMT_U8 |
unsigned 8 bits |
| AV_SAMPLE_FMT_S16 |
signed 16 bits |
| AV_SAMPLE_FMT_S32 |
signed 32 bits |
| AV_SAMPLE_FMT_FLT |
float |
| AV_SAMPLE_FMT_DBL |
double |
| AV_SAMPLE_FMT_U8P |
unsigned 8 bits, planar |
| AV_SAMPLE_FMT_S16P |
signed 16 bits, planar |
| AV_SAMPLE_FMT_S32P |
signed 32 bits, planar |
| AV_SAMPLE_FMT_FLTP |
float, planar |
| AV_SAMPLE_FMT_DBLP |
double, planar |
| AV_SAMPLE_FMT_NB |
Number of sample formats. DO NOT USE if linking dynamically. |
打印对应的含义
printf("av_get_sample_fmt_name= %s\n",av_get_sample_fmt_name(frame->format));
3.3 ffmpeg音频帧的物理存放方式含义
3.3.1 第一层意思: 每个采样点数据的物理存储类型
大端小端方式
无符号/有符号
数据位数
8位,16位等
数据类型
整形,浮点类型等
3.3.2 第二层意思: 不同声道的同一采样点是否单独存放
两种存放方式 packed和planar
第一种: 多个声道数据交错存放(packed类型,不带字符P)
对于 packed音频(左右声道打包存放), 只有一个数据指针(相当于一个声道)。
所有声道的数据交错排放在frame->data[0](即frame->extended_data[0])地址处
所有声道的数据长度为linesize[0](单位:字节)
地址 数据 备注
data[0] 声道1的采样点0 每个采样点数据有int、uint、float,大端小端之分
data[0]+1 声道2的采样点0
data[0]+2 声道1的采样点1
data[0]+3 声道2的采样点1
data[0]+4 声道1的采样点2
data[0]+5 声道2的采样点2
… …
data[0]+2i 声道1的采样点i
data[0]+2i+1 声道2的采样点i
比如:
AV_SAMPLE_FMT_S16 所有声道的数据放在一个buffer中,左右声道采样点交叉存放,
每个采样值为一个signed 16位(范围为-32767 to +32767)。
第二种: 每个声道数据单独存放(planar类型,带字符P)
对于 planar音频(左右声道分开存放),每个声道有自己的数据存放位置。
声道0的起始地址为 frame->data[0](或frame->extended_data[0])
声道1的起始地址为 frame->data[1](或frame->extended_data[1])
声道i的起始地址为 frame->data[i](或frame->extended_data[i])
每个声道的数据长度为linesize[0](单位:字节)
实际上ffmpeg在实现的时候,每个声道的数据连续存放,不同声道之间也是连续存放的。
地址 声道
data[0] 声道1 采样点1
采样点2
采样点i
data[1] 声道2 采样点1
采样点2
采样点i
所以 data[i]=data[i-1] + linesize[0]
比如: AV_SAMPLE_FMT_S16P 每个声道的数据放在单独的buffer中,每个采样值为一个signed 16位(范围为-32767 to +32767)。
3.3.3 两者之间的联系
所有声道的数据都是存放在 frame->data[0]开始的一段连续空间中
如果是 packed类型,同一采样点的不同声道数据放到一起,然后存储下一个采样点
如果是 planar类型,同一声道的所有采样点数据放到一起,然后存放下一个声道
判断是否是 planar类型
av_sample_fmt_is_planar(sample_fmt)
3.3.4 两者之间的转换
通过重采样函数进行转换
手动将每个声道的数据交错存放
根据存放方式,分配pcm数据空间(重采样用)
1) . 手动分配
int nb_planes;
static uint8_t **audio_dst_data = NULL;
//如果是 planar类型,需要分配一个指针数组,每个元素指向一个声道
nb_planes = av_sample_fmt_is_planar(audio_dec_ctx->sample_fmt) ? audio_dec_ctx->channels : 1;
audio_dst_data = av_mallocz(sizeof(uint8_t *) * nb_planes);
if (!audio_dst_data) {
fprintf(stderr, "Could not allocate audio data buffers\n");
ret = AVERROR(ENOMEM);
goto end;
}
ret = av_samples_alloc(audio_dst_data, &audio_dst_linesize, av_frame_get_channels(frame),
frame->nb_samples, frame->format, 1);
if (ret < 0) {
fprintf(stderr, "Could not allocate audio buffer\n");
return AVERROR(ENOMEM);
}
2). 调用接口函数(内部实现,即是上面的函数调用过程)
uint8_t ** audio_data;
src_nb_channels = av_get_channel_layout_nb_channels(src_ch_layout);
//都是定义二重指针 audio_data,注意这里的调用方式
ret = av_samples_alloc_array_and_samples(&src_data, &src_linesize, src_nb_channels,
src_nb_samples, src_sample_fmt, 0);
if (ret < 0) {
fprintf(stderr, "Could not allocate source samples\n");
goto end;
}
// 这个函数内部即是上面的过程
int av_samples_alloc_array_and_samples (uint8_t * audio_data,
int * linesize,
int nb_channels,
int nb_samples,
enum AVSampleFormat sample_fmt,
int align )
3.3.5 获取pcm声道占有的byte空间大小
获取pcm每个声道占有的byte空间大小(可以通过pcm物理数据类型和采样点个数,通道个数推导出)
对于 packed音频(左右声道打包存放)
AVFrame->int linesize[0]值即为打包存放的所有声道的数据字节长度
对于 planar音频(每个声道数据单独存放)
AVFrame->int linesize[0]值即为每个声道的数据字节长度
例如:
frame->format为 FLTP类型(每个sample是float类型的)
frame->nb_samples=2048(每个声道2048个采样点)
推导出: 每个声道占有的byte空间大小为 2048*4=8192
frame->linesize[0]确实等于8192
获取pcm所有声道占有的byte空间大小
对于 packed音频(左右声道打包存放)
linesize[0]值即为所有声道的数据字节长度
对于 packed和planar音频,都可以使用官方函数得出
输入的参数为pcm类型,声道个数,采样点数
int av_samples_get_buffer_size ( int * linesize, //主要针对 planar类型
int nb_channels,
int nb_samples,
enum AVSampleFormat sample_fmt,
int align
)
参数定义:
[out] linesize, calculated linesize, may be NULL
nb_channels , the number of channels
nb_samples, the number of samples in a single channel
sample_fmt, the sample format
align, buffer size alignment (0 = default, 1 = no alignment)
【Returns】
required buffer size, or negative error code on failure
三、FFmpeg的格式转换的实现
ffmpeg升级到2.1后(具体哪个版本开始的没去查,可能早几个版本就已经这样做了),音频格式增加了plane概念
enum AVSampleFormat {
AV_SAMPLE_FMT_NONE = -1,
AV_SAMPLE_FMT_U8, ///< unsigned 8 bits
AV_SAMPLE_FMT_S16, ///< signed 16 bits
AV_SAMPLE_FMT_S32, ///< signed 32 bits
AV_SAMPLE_FMT_FLT, ///< float
AV_SAMPLE_FMT_DBL, ///< double
// 以下都是带平面格式
AV_SAMPLE_FMT_U8P, ///< unsigned 8 bits, planar
AV_SAMPLE_FMT_S16P, ///< signed 16 bits, planar
AV_SAMPLE_FMT_S32P, ///< signed 32 bits, planar
AV_SAMPLE_FMT_FLTP, ///< float, planar
AV_SAMPLE_FMT_DBLP, ///< double, planar
AV_SAMPLE_FMT_NB ///< Number of sample formats. DO NOT USE if linking dynamically
};
这就有点像视频部分的YUV数据,有的带P,有的是不带P的,同样对双声道音频PCM数据,以S16P为例,存储就可能是
plane 0: LLLLLLLLLLLLLLLLLLLLLLLLLL...
plane 1: RRRRRRRRRRRRRRRRRRRRRRRRRR...
而不再是以前的连续buffer。
如mp3编码就明确规定了只使用平面格式的数据
AVCodec ff_libmp3lame_encoder = {
.....
.capabilities = CODEC_CAP_DELAY | CODEC_CAP_SMALL_LAST_FRAME,
.sample_fmts = (const enum AVSampleFormat[]) { AV_SAMPLE_FMT_S32P,
AV_SAMPLE_FMT_FLTP,
AV_SAMPLE_FMT_S16P,
AV_SAMPLE_FMT_NONE },
....
};
而AAC编码依旧使用 AV_SAMPLE_FMT_S16格式
也就说,音频编码不能再像以前那样简单的处理,统一输入S16数据,而要根据具体的codec转化为其支持的格式,
否则无论是编码还是解码输出的声音会莫名其妙,
幸好,转换工作不用自己做,ffmpeg提供了相应的API:
swr_convert(类似以前的audio_resample,只是audio_resample目前已不再推荐使用,因为swr_convert更强大)
示例代码见:
《基于FFmpeg-4.0 SDK的音频重采样》