比特币源码阅读笔记【基础篇】
出差坐火车ing,正好利用这段时间学习一波比特币源代码,比特币源码的主要语言是C++,测试代码语言主要是Python。
一、区块链数据结构和数字签名算法
1. 数据结构 Merkle树
区块链, 顾名思义是由一个个区块按一定规则组成的链。何谓区块,我们可以用命令行工具bitcoin-cli或者区块链浏览器(blockchain.info等网站)浏览区块详细信息, 例如:
{
"size": 43560,
"version": 2,
"previousblockhash": "00000000000000027e7ba6fe7bad39faf3b5a83daed765f05f7d1b71a1632249",
"merkleroot": "5e049f4030e0ab2debb92378f53c0a6e09548aea083f3ab25e1d94ea1155e29d",
"time": 1388185038,
"difficulty": 1180923195.25802612,
"nonce": 4215469401,
"tx": ["257e7497fb8bc68421eb2c7b699dbab234831600e7352f0d9e6522c7cf3f6c77", # [...many more transactions omitted...]
"05cfd38f6ae6aa83674cc99e4d75a1458c165b7ab84725eda41d018a09176634"
]
}区块包含的信息分几个部分:1.元信息,如version,time,size等 2. 挖矿信息,如仅用一次的随机数nonce, 难度系数difficulty 3. 交易数据 4. 交易摘要,merkleroot和perviousblockhash。
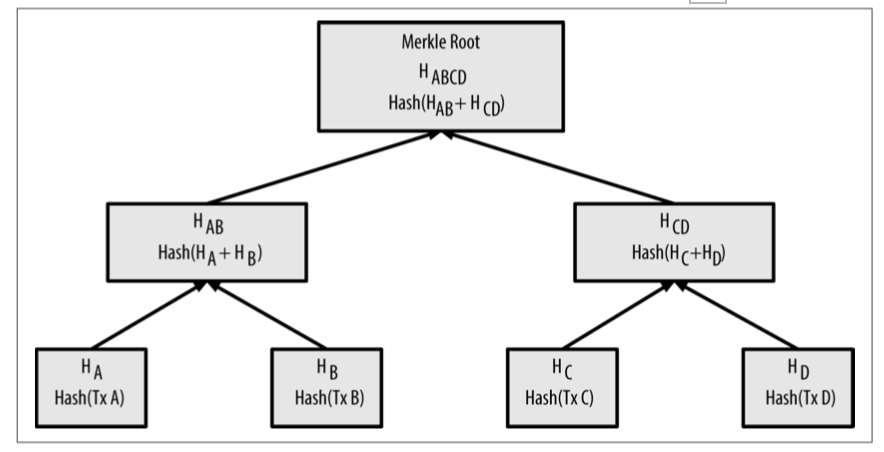
比特币采用Merkle树进行交易摘要。 Merkle树的基础是哈希函数和非对称数字签名,比特币选择的哈希函数是两层SHA256。交易本身不存储在Merkle树中,Merkle树保存交易的哈希值。例如,一笔交易A的哈希值计算过程HA = SHA256(SHA256(A))
, 两笔交易A和B的哈希值计算过程为H(A,B) = SHA256(SHA256(HA+HB)))。交易数据两两计算,最终组成一个哈希二叉树,如下图所示
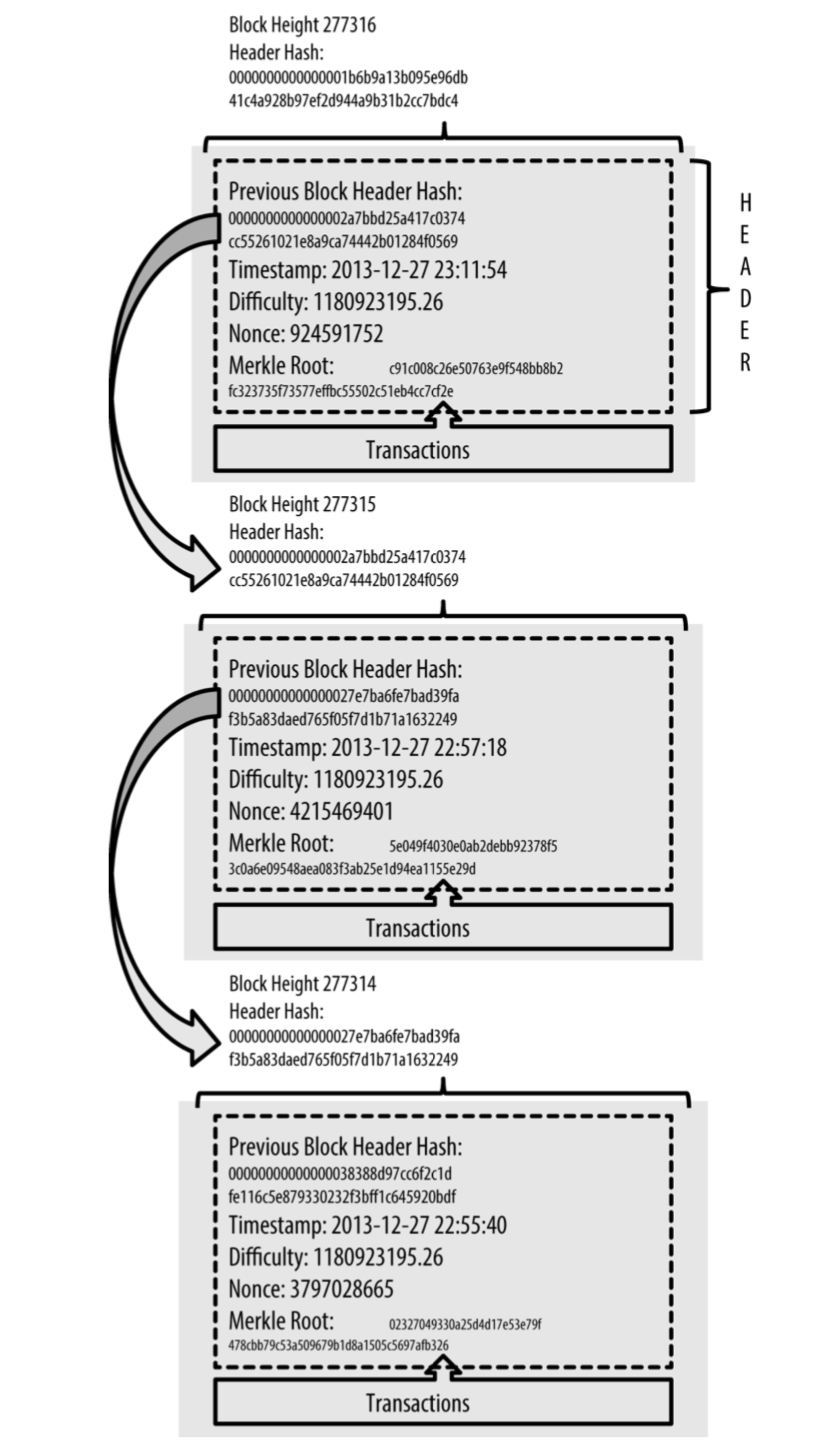
这两个字段,merkleroot表示整条链的交易摘要哈希值,perviousblockhash表示该区块在链中的位置;
下图是一个链的样例:
到此为止,我们已经知道,比特币区块链的基础数据结构是Merkle树。Merkle树是哈希指针形式的二叉树,每个节点包含其子节点的哈希值,一旦子节点的结构或内容发生变动,该节点的哈希值必然发生改变,从而,两个Merkle树最上层节点的哈希值相同,我们就认为两个Merkle树是完全一致的。
Merkle树计算核心函数,见consensus/merkle.cpp
/* This implements a constant-space merkle root/path calculator, limited to 2^32 leaves. */
static void MerkleComputation(const std::vector<uint256>& leaves, uint256* proot, bool* pmutated, uint32_t branchpos, std::vector<uint256>* pbranch) {
if (pbranch) pbranch->clear();
if (leaves.size() == 0) {
if (pmutated) *pmutated = false;
if (proot) *proot = uint256();
return;
}
bool mutated = false;
// count is the number of leaves processed so far.
uint32_t count = 0;
// inner is an array of eagerly computed subtree hashes, indexed by tree
// level (0 being the leaves).
// For example, when count is 25 (11001 in binary), inner[4] is the hash of
// the first 16 leaves, inner[3] of the next 8 leaves, and inner[0] equal to
// the last leaf. The other inner entries are undefined.
uint256 inner[32];
// Which position in inner is a hash that depends on the matching leaf.
int matchlevel = -1;
// First process all leaves into 'inner' values.
while (count < leaves.size()) {
uint256 h = leaves[count];
bool matchh = count == branchpos;
count++;
int level;
// For each of the lower bits in count that are 0, do 1 step. Each
// corresponds to an inner value that existed before processing the
// current leaf, and each needs a hash to combine it.
for (level = 0; !(count & (((uint32_t)1) << level)); level++) {
if (pbranch) {
if (matchh) {
pbranch->push_back(inner[level]);
} else if (matchlevel == level) {
pbranch->push_back(h);
matchh = true;
}
}
mutated |= (inner[level] == h);
CHash256().Write(inner[level].begin(), 32).Write(h.begin(), 32).Finalize(h.begin());
}
// Store the resulting hash at inner position level.
inner[level] = h;
if (matchh) {
matchlevel = level;
}
}
// Do a final 'sweep' over the rightmost branch of the tree to process
// odd levels, and reduce everything to a single top value.
// Level is the level (counted from the bottom) up to which we've sweeped.
int level = 0;
// As long as bit number level in count is zero, skip it. It means there
// is nothing left at this level.
while (!(count & (((uint32_t)1) << level))) {
level++;
}
uint256 h = inner[level];
bool matchh = matchlevel == level;
while (count != (((uint32_t)1) << level)) {
// If we reach this point, h is an inner value that is not the top.
// We combine it with itself (Bitcoin's special rule for odd levels in
// the tree) to produce a higher level one.
if (pbranch && matchh) {
pbranch->push_back(h);
}
CHash256().Write(h.begin(), 32).Write(h.begin(), 32).Finalize(h.begin());
// Increment count to the value it would have if two entries at this
// level had existed.
count += (((uint32_t)1) << level);
level++;
// And propagate the result upwards accordingly.
while (!(count & (((uint32_t)1) << level))) {
if (pbranch) {
if (matchh) {
pbranch->push_back(inner[level]);
} else if (matchlevel == level) {
pbranch->push_back(h);
matchh = true;
}
}
CHash256().Write(inner[level].begin(), 32).Write(h.begin(), 32).Finalize(h.begin());
level++;
}
}
// Return result.
if (pmutated) *pmutated = mutated;
if (proot) *proot = h;
}2. 数字签名算法 椭圆曲线算法
2.1 椭圆曲线算法和公私钥
日常工作中,我们每天登录服务器,对公私钥系统已经非常熟悉了,公私钥并不是新鲜的技术。我们可以用ssh-keygen命令生成一对公钥和私钥;当拥有私钥时,可以用ssh-keygen -y -f生成配对的公钥,但拥有公钥无法生成配对的私钥。这背后的原理就是椭圆曲线数字签名算法(Elliptic Curve Digital Signature Algorithm, 简写为ECDSA)。比特币利用椭圆曲线生成密钥对,其中公钥作为交易接收方的地址,对外传播。
在平面直角坐标系中,一条椭圆曲线的形状如下图。比特币的源码中,椭圆曲线定义在src/secp256k1目录。比特币选择的椭圆曲线方程为y2 mod p = (x3 + 7) mod p,其中p是一个非常大的质数,p = 2256 - 232 - 29 - 28 - 27 - 26 - 24 - 1。
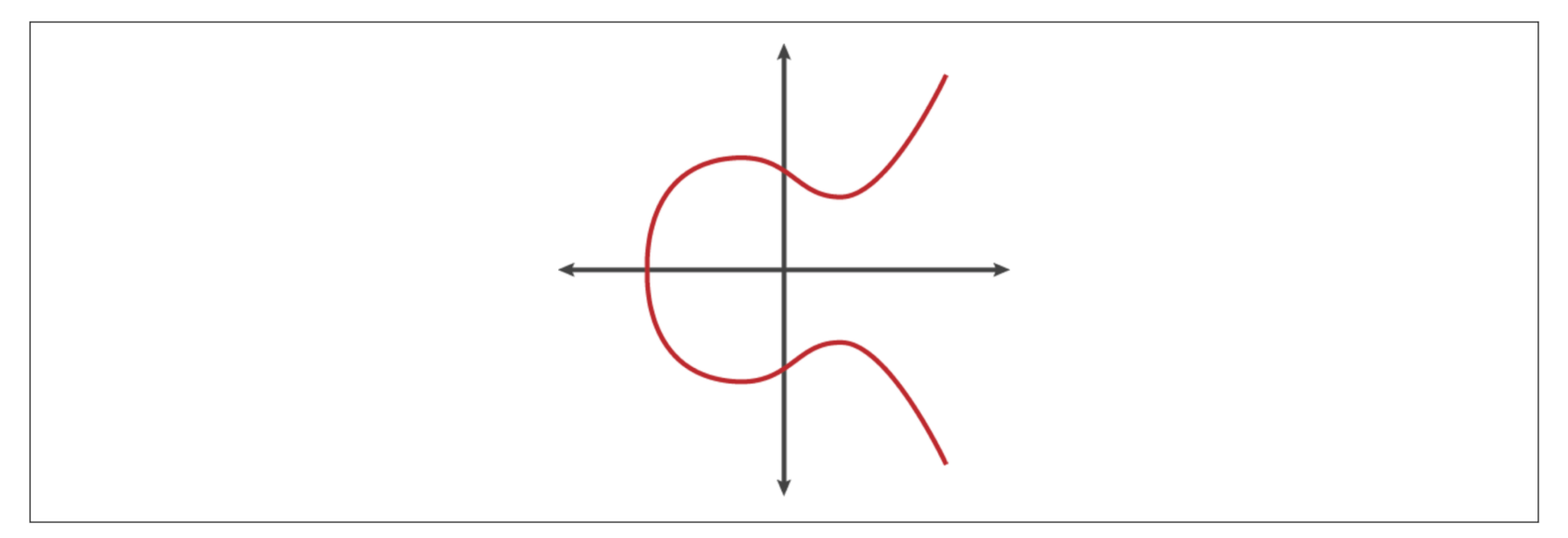
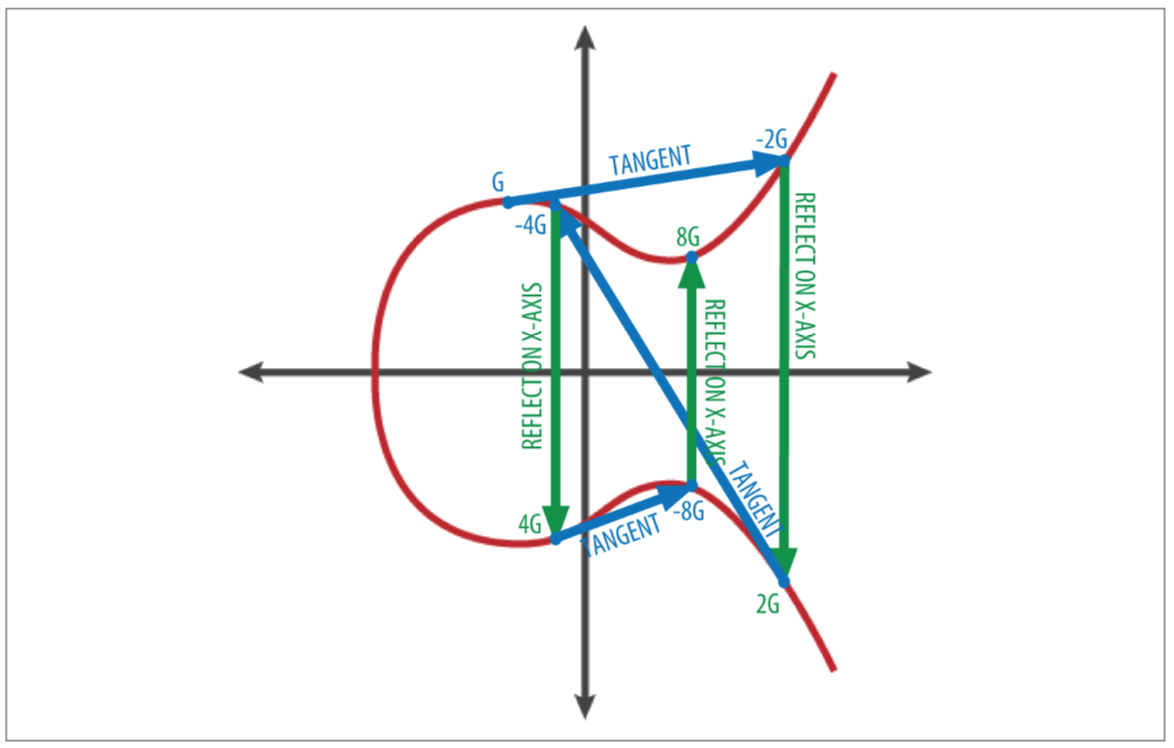
给定私钥k, 如何根据椭圆曲线生成公钥K呢?公式为K = k * G。其中,G 代表一种变换,从点k=(x,y)进行一次变换生成k1=(x1, y1),先在点k出求正切线,正切线与椭圆曲线的交点…
下图用几何形式展示了变换G。
2.2 SHA-256
哈希函数在比特币中用途极为广泛,包括:比特币地址,交易脚本地址,挖矿工作量证明。在比特币系统中,利用公钥生成比特币地址的算法是SHA256和 RIPEMD160。
由公钥生成比特币地址的总体过程如下图所示
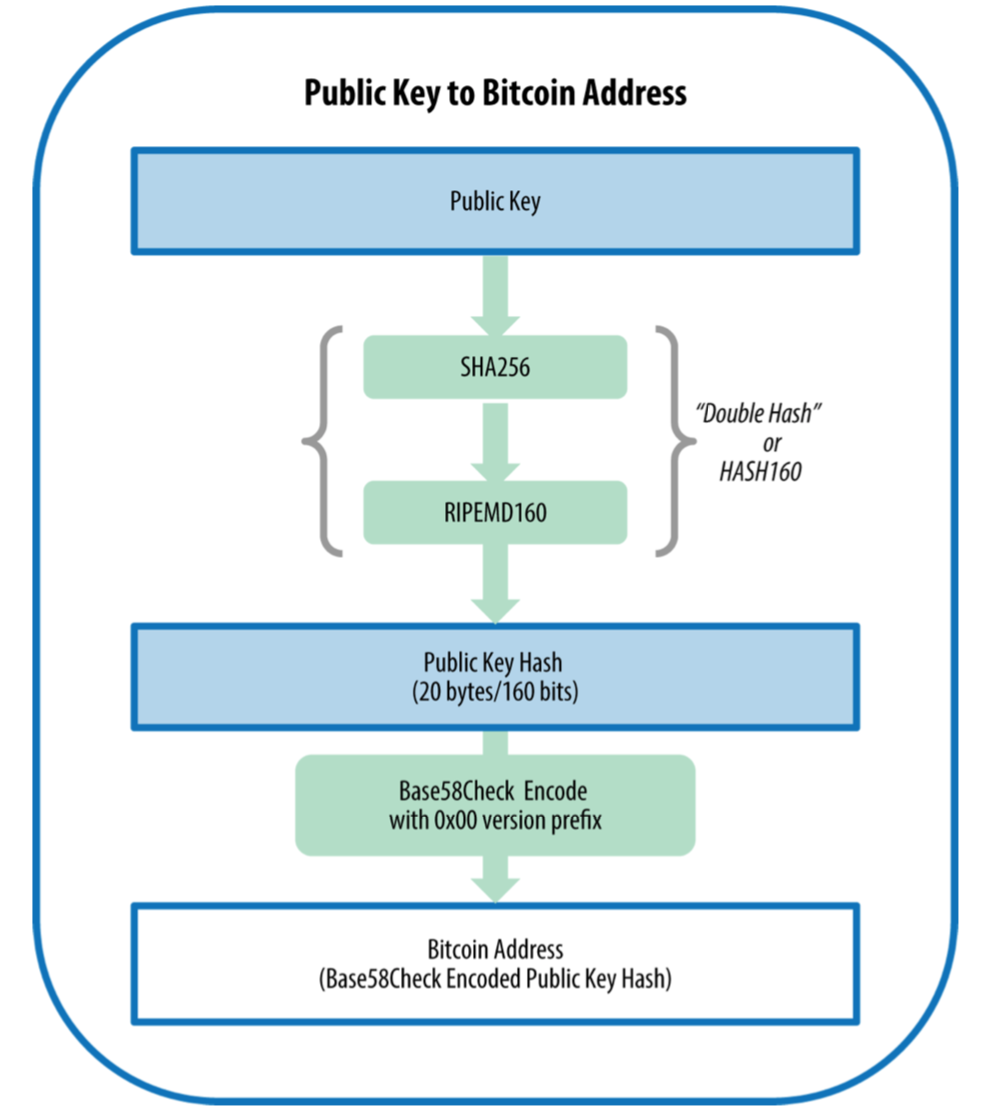
给定公钥K,先进行SHA256哈希,再对SHA256的结果进行RIPEMD160哈希,得到的值A就是比特币地址, 即A = RIPEMD160(SHA256(K))。A值进一步压缩, 我们就得到了比特币地址, 形如1J7mdg5rbQyUHENYdx39WVWK7fsLpEoXZy。比特币选择的压缩算法是Base58Check。
SHA-256计算过程,如下图
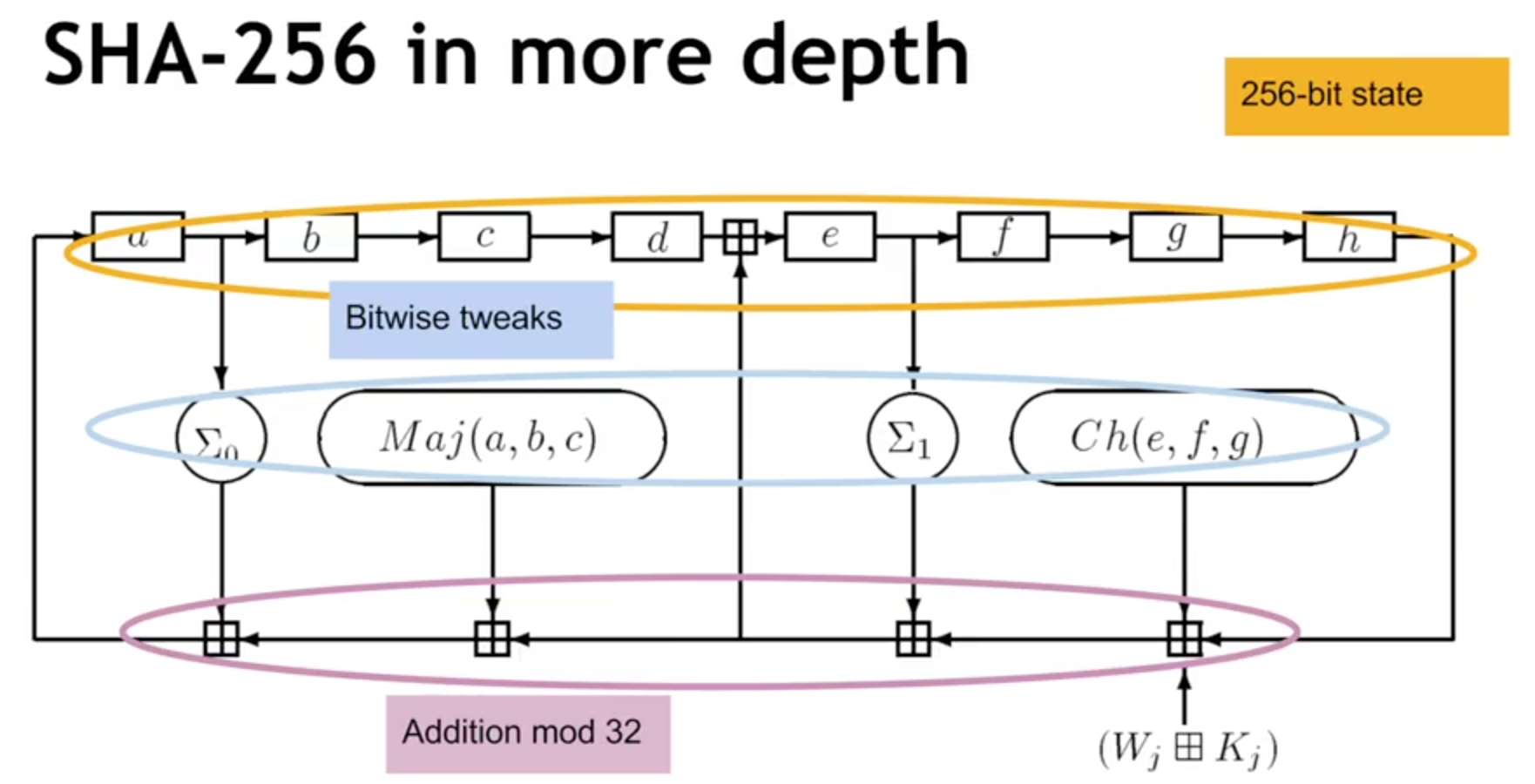
我们来看一下比特币源码中SHA256哈希的实现
哈希函数类定义如下, 主体是状态s,由8个32位无符号整数组成。缓冲buf用于批量读入和计算数据。
/** A hasher class for SHA-256. */
class CSHA256
{
private:
uint32_t s[8];
unsigned char buf[64];
uint64_t bytes;
public:
static const size_t OUTPUT_SIZE = 32;
CSHA256();
CSHA256& Write(const unsigned char* data, size_t len);
void Finalize(unsigned char hash[OUTPUT_SIZE]);
CSHA256& Reset();
};SHA256的主体代码,数据data每64字节读入一次,写入buff,经过Transform处理,得到s值。
CSHA256& CSHA256::Write(const unsigned char* data, size_t len)
{
const unsigned char* end = data + len;
size_t bufsize = bytes % 64;
if (bufsize && bufsize + len >= 64) {
// Fill the buffer, and process it.
memcpy(buf + bufsize, data, 64 - bufsize);
bytes += 64 - bufsize;
data += 64 - bufsize;
Transform(s, buf, 1);
bufsize = 0;
}
if (end - data >= 64) {
size_t blocks = (end - data) / 64;
Transform(s, data, blocks);
data += 64 * blocks;
bytes += 64 * blocks;
}
if (end > data) {
// Fill the buffer with what remains.
memcpy(buf + bufsize, data, end - data);
bytes += end - data;
}
return *this;
}这里定义了一些基本运算,Ch, Maj, Sigma0, Sigma1, sigma0, sigma1,很直白,无需赘言。
uint32_t inline Ch(uint32_t x, uint32_t y, uint32_t z) { return z ^ (x & (y ^ z)); }
uint32_t inline Maj(uint32_t x, uint32_t y, uint32_t z) { return (x & y) | (z & (x | y)); }
uint32_t inline Sigma0(uint32_t x) { return (x >> 2 | x << 30) ^ (x >> 13 | x << 19) ^ (x >> 22 | x << 10); }
uint32_t inline Sigma1(uint32_t x) { return (x >> 6 | x << 26) ^ (x >> 11 | x << 21) ^ (x >> 25 | x << 7); }
uint32_t inline sigma0(uint32_t x) { return (x >> 7 | x << 25) ^ (x >> 18 | x << 14) ^ (x >> 3); }
uint32_t inline sigma1(uint32_t x) { return (x >> 17 | x << 15) ^ (x >> 19 | x << 13) ^ (x >> 10); }初始化8个32位的无符号整数,作为初始状态。
/** Initialize SHA-256 state. */
void inline Initialize(uint32_t* s)
{
s[0] = 0x6a09e667ul;
s[1] = 0xbb67ae85ul;
s[2] = 0x3c6ef372ul;
s[3] = 0xa54ff53aul;
s[4] = 0x510e527ful;
s[5] = 0x9b05688cul;
s[6] = 0x1f83d9abul;
s[7] = 0x5be0cd19ul;
}/** One round of SHA-256. */
void inline Round(uint32_t a, uint32_t b, uint32_t c, uint32_t& d, uint32_t e, uint32_t f, uint32_t g, uint32_t& h, uint32_t k, uint32_t w)
{
uint32_t t1 = h + Sigma1(e) + Ch(e, f, g) + k + w;
uint32_t t2 = Sigma0(a) + Maj(a, b, c);
d += t1;
h = t1 + t2;
}每一轮SHA256计算过程如上所示,同样很直白,无需赘言。
下面的Transform函数比较有内容,函数输入一个64字节的chunk和状态s,每次从chunk读入4字节,根据当前状态s,做16次Round计算;完成后再做三轮16次Round;最后,8个无符号整数都加上上述64次Round的结果,更新状态s。经过上述计算,我们就得到了数据chunk的SHA256哈希值。
数据读写的代码,见/src/crypto/common.h
/** Perform a number of SHA-256 transformations, processing 64-byte chunks. */
void Transform(uint32_t* s, const unsigned char* chunk, size_t blocks)
{
while (blocks--) {
uint32_t a = s[0], b = s[1], c = s[2], d = s[3], e = s[4], f = s[5], g = s[6], h = s[7];
uint32_t w0, w1, w2, w3, w4, w5, w6, w7, w8, w9, w10, w11, w12, w13, w14, w15;
// 步骤一:
Round(a, b, c, d, e, f, g, h, 0x428a2f98, w0 = ReadBE32(chunk + 0));
Round(h, a, b, c, d, e, f, g, 0x71374491, w1 = ReadBE32(chunk + 4));
// 中间省略...
Round(c, d, e, f, g, h, a, b, 0x9bdc06a7, w14 = ReadBE32(chunk + 56));
Round(b, c, d, e, f, g, h, a, 0xc19bf174, w15 = ReadBE32(chunk + 60));
// 步骤二:
Round(a, b, c, d, e, f, g, h, 0xe49b69c1, w0 += sigma1(w14) + w9 + sigma0(w1));
Round(h, a, b, c, d, e, f, g, 0xefbe4786, w1 += sigma1(w15) + w10 + sigma0(w2));
// 中间省略
Round(c, d, e, f, g, h, a, b, 0x06ca6351, w14 += sigma1(w12) + w7 + sigma0(w15));
Round(b, c, d, e, f, g, h, a, 0x14292967, w15 += sigma1(w13) + w8 + sigma0(w0));
// 步骤三:
Round(a, b, c, d, e, f, g, h, 0x27b70a85, w0 += sigma1(w14) + w9 + sigma0(w1));
Round(h, a, b, c, d, e, f, g, 0x2e1b2138, w1 += sigma1(w15) + w10 + sigma0(w2));
// 中间省略
Round(c, d, e, f, g, h, a, b, 0xf40e3585, w14 += sigma1(w12) + w7 + sigma0(w15));
Round(b, c, d, e, f, g, h, a, 0x106aa070, w15 += sigma1(w13) + w8 + sigma0(w0));
// 步骤四:
Round(a, b, c, d, e, f, g, h, 0x19a4c116, w0 += sigma1(w14) + w9 + sigma0(w1));
Round(h, a, b, c, d, e, f, g, 0x1e376c08, w1 += sigma1(w15) + w10 + sigma0(w2));
// 中间省略
Round(c, d, e, f, g, h, a, b, 0xbef9a3f7, w14 + sigma1(w12) + w7 + sigma0(w15));
Round(b, c, d, e, f, g, h, a, 0xc67178f2, w15 + sigma1(w13) + w8 + sigma0(w0));
s[0] += a;
s[1] += b;
s[2] += c;
s[3] += d;
s[4] += e;
s[5] += f;
s[6] += g;
s[7] += h;
chunk += 64;
}
}
以上就是SHA256哈希算法的实现;下一步,我们分析交易结构。
二、交易
一般的交易系统设计:账户,余额。比特币的交易系统, 不记录余额,记录交易内容。例如,一般的交易系统,记录Alice的余额为10 RMB,Bob的余额为5RMB,当Alice发起交易,给Bob支付5RMB时,支付系统后台检查Alice的余额,验证通过后,对Alice的余额减5RMB,再对Bob的余额加5RMB。
而区块链处理的思路是,不记录Alice和Bob的账户余额,记录历史上发生过的所有交易记录,以未消费交易输出(UTXO)形式分布式地保存在区块链上,区块链网络节点共同验证UTXO是否合法。
构建比特币交易的基础是交易输出, 交易输出是比特币货币系统中不可拆分的块(chunk),记录在区块链上,被比特币网络认证;比特币网络节点记录所有可获得且可消费的交易输出,称作未消费交易输出(unspent transaction outputs), 简写成UTXO。
区块链上的一笔交易,代表着一组UTXO集合状态转换到另外一组UTXO集合状态。当产生新的“比特币”时,UTXO集合大小增加。UTXO是比特币交易的基础。“账户余额”的概念由比特币钱包应用创造,钱包应用扫描区块链,得到钱包拥有者的私钥可以消费的UTXO的总和,即“账户余额”。大多数钱包应用维护了一个数据库,用于存储该钱包私钥可以消费的UTXO集合。
2.1 交易格式
实际比特币的交易记录是二进制格式,转换成可读格式后,一笔交易的内容包含三个部分:元数据,输入,输出; 如下所示
{
"version": 1,
"locktime": 0,
"vin": [{
"txid": "7957a35fe64f80d234d76d83a2a8f1a0d8149a41d81de548f0a65a8a999f6f18",
"vout": 0,
"scriptSig": "3045022100884d142d86652a3f47ba4746ec719bbfbd040a570b1deccbb6498c75c4ae24cb02204 b9f039ff08df09cbe9f6addac960298cad530a863ea8f53982c09db8f6e3813[ALL] 0484ecc0d46f1918b30928fa0e4ed99f16a0fb4fde0735e7ade8416ab9fe423cc5412336376789d1 72787ec3457eee41c04f4938de5cc17b4a10fa336a8d752adf",
"sequence": 4294967295
}],
"vout": [{
"value": 0.01500000,
"scriptPubKey": "OP_DUP OP_HASH160 ab68025513c3dbd2f7b92a94e0581f5d50f654e7 OP_EQUALVERIFY OP_CHECKSIG "
}, {
"value": 0.08450000,
"scriptPubKey": "OP_DUP OP_HASH160 7f9b1a7fb68d60c536c2fd8aeaa53a8f3cc025a8 OP_EQUALVERIFY OP_CHECKSIG"
}]
}值得注意的是,每个输入包含了一项scirptSig, 上例中是3045022100884d142d86652a3f47ba4746ec719bbfbd040a570b1deccbb6498c75c4ae24cb02204 b9f039ff08df09cbe9f6addac960298cad530a863ea8f53982c09db8f6e3813[ALL] 0484ecc0d46f1918b30928fa0e4ed99f16a0fb4fde0735e7ade8416ab9fe423cc5412336376789d1 72787ec3457eee41c04f4938de5cc17b4a10fa336a8d752adf, 每个输出的元素都包含了一项scriptPubKey, 上例中是ab68025513c3dbd2f7b92a94e0581f5d50f654e7, 这个值代表了交易脚本的哈希值。(稍后详细描述)
比特币交易结构,见primitives/transaction.h
/**
* Basic transaction serialization format:
* - int32_t nVersion
* - std::vector<CTxIn> vin
* - std::vector<CTxOut> vout
* - uint32_t nLockTime
*
* Extended transaction serialization format:
* - int32_t nVersion
* - unsigned char dummy = 0x00
* - unsigned char flags (!= 0)
* - std::vector<CTxIn> vin
* - std::vector<CTxOut> vout
* - if (flags & 1):
* - CTxWitness wit;
* - uint32_t nLockTime
*/可以看到,基本交易序列化格式的信息包括:版本号,输入列表,输出列表,锁定时间;此外,扩展的交易序列化格式还包括扩容方案隔离见证的一些信息。关于比特币扩容和隔离见证此处不展开讨论,准备单独写一篇笔记。对比特币扩容方案感兴趣的读者,建议阅读BIP-141, BIP-143和BIP-147。
交易输入定义,见src/primitives/transaction.h
/** An input of a transaction. It contains the location of the previous
* transaction's output that it claims and a signature that matches the
* output's public key.
*/
class CTxIn
{
public:
COutPoint prevout;
CScript scriptSig;
uint32_t nSequence;
CScriptWitness scriptWitness; //! Only serialized through CTransaction
/* Setting nSequence to this value for every input in a transaction
* disables nLockTime. */
static const uint32_t SEQUENCE_FINAL = 0xffffffff;
/* Below flags apply in the context of BIP 68*/
/* If this flag set, CTxIn::nSequence is NOT interpreted as a
* relative lock-time. */
static const uint32_t SEQUENCE_LOCKTIME_DISABLE_FLAG = (1 << 31);
/* If CTxIn::nSequence encodes a relative lock-time and this flag
* is set, the relative lock-time has units of 512 seconds,
* otherwise it specifies blocks with a granularity of 1. */
static const uint32_t SEQUENCE_LOCKTIME_TYPE_FLAG = (1 << 22);
/* If CTxIn::nSequence encodes a relative lock-time, this mask is
* applied to extract that lock-time from the sequence field. */
static const uint32_t SEQUENCE_LOCKTIME_MASK = 0x0000ffff;
/* In order to use the same number of bits to encode roughly the
* same wall-clock duration, and because blocks are naturally
* limited to occur every 600s on average, the minimum granularity
* for time-based relative lock-time is fixed at 512 seconds.
* Converting from CTxIn::nSequence to seconds is performed by
* multiplying by 512 = 2^9, or equivalently shifting up by
* 9 bits. */
static const int SEQUENCE_LOCKTIME_GRANULARITY = 9;
CTxIn()
{
nSequence = SEQUENCE_FINAL;
}
explicit CTxIn(COutPoint prevoutIn, CScript scriptSigIn=CScript(), uint32_t nSequenceIn=SEQUENCE_FINAL);
CTxIn(uint256 hashPrevTx, uint32_t nOut, CScript scriptSigIn=CScript(), uint32_t nSequenceIn=SEQUENCE_FINAL);
ADD_SERIALIZE_METHODS;
template <typename Stream, typename Operation>
inline void SerializationOp(Stream& s, Operation ser_action) {
READWRITE(prevout);
READWRITE(scriptSig);
READWRITE(nSequence);
}
friend bool operator==(const CTxIn& a, const CTxIn& b)
{
return (a.prevout == b.prevout &&
a.scriptSig == b.scriptSig &&
a.nSequence == b.nSequence);
}
friend bool operator!=(const CTxIn& a, const CTxIn& b)
{
return !(a == b);
}
std::string ToString() const;
};交易输出定义,见src/primitives/transaction.h
/** An output of a transaction. It contains the public key that the next input
* must be able to sign with to claim it.
*/
class CTxOut
{
public:
CAmount nValue;
CScript scriptPubKey;
CTxOut()
{
SetNull();
}
CTxOut(const CAmount& nValueIn, CScript scriptPubKeyIn);
ADD_SERIALIZE_METHODS;
template <typename Stream, typename Operation>
inline void SerializationOp(Stream& s, Operation ser_action) {
READWRITE(nValue);
READWRITE(scriptPubKey);
}
void SetNull()
{
nValue = -1;
scriptPubKey.clear();
}
bool IsNull() const
{
return (nValue == -1);
}
friend bool operator==(const CTxOut& a, const CTxOut& b)
{
return (a.nValue == b.nValue &&
a.scriptPubKey == b.scriptPubKey);
}
friend bool operator!=(const CTxOut& a, const CTxOut& b)
{
return !(a == b);
}
std::string ToString() const;
};
2.2 交易脚本
比特币脚本语言是专为比特币而设计的简化版本的程序语言。比特币脚本语言有意设计成非图灵完备语言,计算表达能力受到了一定的限制。最主要的有三点:1.数据存储在栈中,不支持定义变量;2. 限制比特币脚本的可用内存和执行时间;3. 比特币脚本中不支持循环,避免死循环导致浪费比特币矿工计算资源。
比特币脚本指令集合,总共有256个操作,其中15个禁用,75个保留。主要的操作为:1. 算数操作,如加减法 2. 分支判断 if/then 3. 逻辑和数据处理 与或非,抛出异常和捕获异常,提前返回等 4. 加密算法,包括哈希函数,签名认证,多重签名认证等。 值得注意的是,比特币脚本语言具有强大的加密算法库,支持在一条操作中对多重签名进行验证,即OP_CHECKMULTISIG操作。多重签名意味着,指定n个公钥,指定一个阈值参数t,表示如果操作想要正常执行,至少匹配n个公钥中的的t个签名。
2.3 未消费交易输出, UTXO
终于到了“币”的环节, “币”在比特币的源码世界里,定义如下,见src/coins.h
/**
* A UTXO entry.
*
* Serialized format:
* - VARINT((coinbase ? 1 : 0) | (height << 1))
* - the non-spent CTxOut (via CTxOutCompressor)
*/
class Coin
{
public:
//! unspent transaction output
CTxOut out;
//! whether containing transaction was a coinbase
unsigned int fCoinBase : 1;
//! at which height this containing transaction was included in the active block chain
uint32_t nHeight : 31;
//! construct a Coin from a CTxOut and height/coinbase information.
Coin(CTxOut&& outIn, int nHeightIn, bool fCoinBaseIn) : out(std::move(outIn)), fCoinBase(fCoinBaseIn), nHeight(nHeightIn) {}
Coin(const CTxOut& outIn, int nHeightIn, bool fCoinBaseIn) : out(outIn), fCoinBase(fCoinBaseIn),nHeight(nHeightIn) {}
void Clear() {
out.SetNull();
fCoinBase = false;
nHeight = 0;
}
//! empty constructor
Coin() : fCoinBase(false), nHeight(0) { }
bool IsCoinBase() const {
return fCoinBase;
}
template<typename Stream>
void Serialize(Stream &s) const {
assert(!IsSpent());
uint32_t code = nHeight * 2 + fCoinBase;
::Serialize(s, VARINT(code));
::Serialize(s, CTxOutCompressor(REF(out)));
}
template<typename Stream>
void Unserialize(Stream &s) {
uint32_t code = 0;
::Unserialize(s, VARINT(code));
nHeight = code >> 1;
fCoinBase = code & 1;
::Unserialize(s, REF(CTxOutCompressor(out)));
}
bool IsSpent() const {
return out.IsNull();
}
size_t DynamicMemoryUsage() const {
return memusage::DynamicUsage(out.scriptPubKey);
}
};参考资料
- 普林斯顿大学公开课 Coursera
- Mastering Bitcoin