版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Chengzi_comm/article/details/47978191
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中
一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,
函数f(key)为哈希(Hash) 函数。
哈希表就是一维数组,数组元素是一个结构体
:结构体有一个节点指针元素,可以有一个数据域,也可以有多个数据域,也可以没有
简单的说
哈希表:hash_table = 顺序结构+链式结构
冲突: 元素x、y、z 分别 % 上 P(默认哈希表长度)后相等,即应该存放在相同下标下
解决办法:把y插入到一个节点中,该节点悬挂到下标为x%P的数组元素下面,z悬挂到y下面。//下面给出哈希表的实现、插入以及打印代码:
#include<iostream>
using namespace std;
#define P 7 // 哈希表默认表长
#define $ -1 // 默认初始化的值
#define ElemType int // 值类型
typedef struct bucket_node // 节点类型
{
ElemType data[3];
struct bucket_node *next; // 每个节点能存放3个数据和一个指向另一个节点的指针
}bucket_node;
typedef bucket_node hash_table[P]; // 定义哈希表(实际就是一个数组)
/*初始化哈希表(数组)元素 */
void init_bucket_node(hash_table &ht, int i)
{
memset(&ht[i], $, sizeof(ElemType)*3);
ht[i].next = 0;
}
/* 初始化哈希表 */
void init_hash_table(hash_table &ht)
{
for(int i = 0; i<P; ++i)
init_bucket_node(ht, i);
}
/* 哈希函数,得到元素x应当插入到哈希表的哪个下标 */
int hash(ElemType x)
{
return x % P;
}
/* 把元素x 插入到哈希表ht中 */
int insert_new_element(hash_table &ht, ElemType x)
{
int index = hash(x); //得到元素x应当插入到哈希表的哪个下标
for(bucket_node* p = &ht[index],*q = NULL; NULL!=p; q=p,p=p->next)
{ // 节点指针p 指向ht[index]节点
if(NULL != p->next) // 如果p->next == NULL,说明p所指节点的三个数据已经插满
continue; // 则p指向下一个节点
for(int i = 0; i<3; ++i)
{
if($ == p->data[i]) // 如果某个位置等于$,说明该位置为空,把x插入并返回
{
p->data[i] = x;
return 0;
}
}
}
if(NULL == p) // 如果 p == NULL,说明最后一个节点刚好插满,需要另外开辟一个节点的内存
{
bucket_node * s = new bucket_node;
memset(s, $, sizeof(ElemType)*3); // 初始化刚开辟的内存
s->next = NULL;
s->data[0] = x; // x 放入该节点的第一个位置
q->next = s; // 把s 挂到最后一个节点的下面
return 0;
}
return -1; // 如果没有在现有节点下找到位置,并且开辟节点也失败的话,x 就真的不能插入了
}
/* 打印哈希表 */
void show_hash_table(hash_table &ht)
{
bucket_node* p = NULL;
for(int i = 0; i<P; ++i) // 从第一个哈希表元素开始打印,知道最后一个元素
{
cout<<"ht["<<i<<"]"<<" : ";
for(p=&ht[i]; NULL!=p; p=p->next) // 打印下标为i的哈希表元素及该位置所链接的节点
{
for( int k = 0; 3>k && $!=p->data[k]; ++k) // p->data[k] != $ ,说明该位置不空,则打印
{
cout<<p->data[k]<<" ";
}
}
cout<<endl;
}
}//下面是测试代码: Main.cpp
void main()
{
hash_table ht;
ElemType ar[] = {0,7,14,21,28,59,35,42,5,9,3,6,13,52,64}; // 测试数组
init_hash_table(ht); // 初始化哈希表
for(int i = 0; i<sizeof(ar)/sizeof(*ar); ++i)
insert_new_element(ht, ar[i]); // 数组元素依次插入哈希表
show_hash_table(ht); // 打印哈希表
cout<<"Over"<<endl;
}
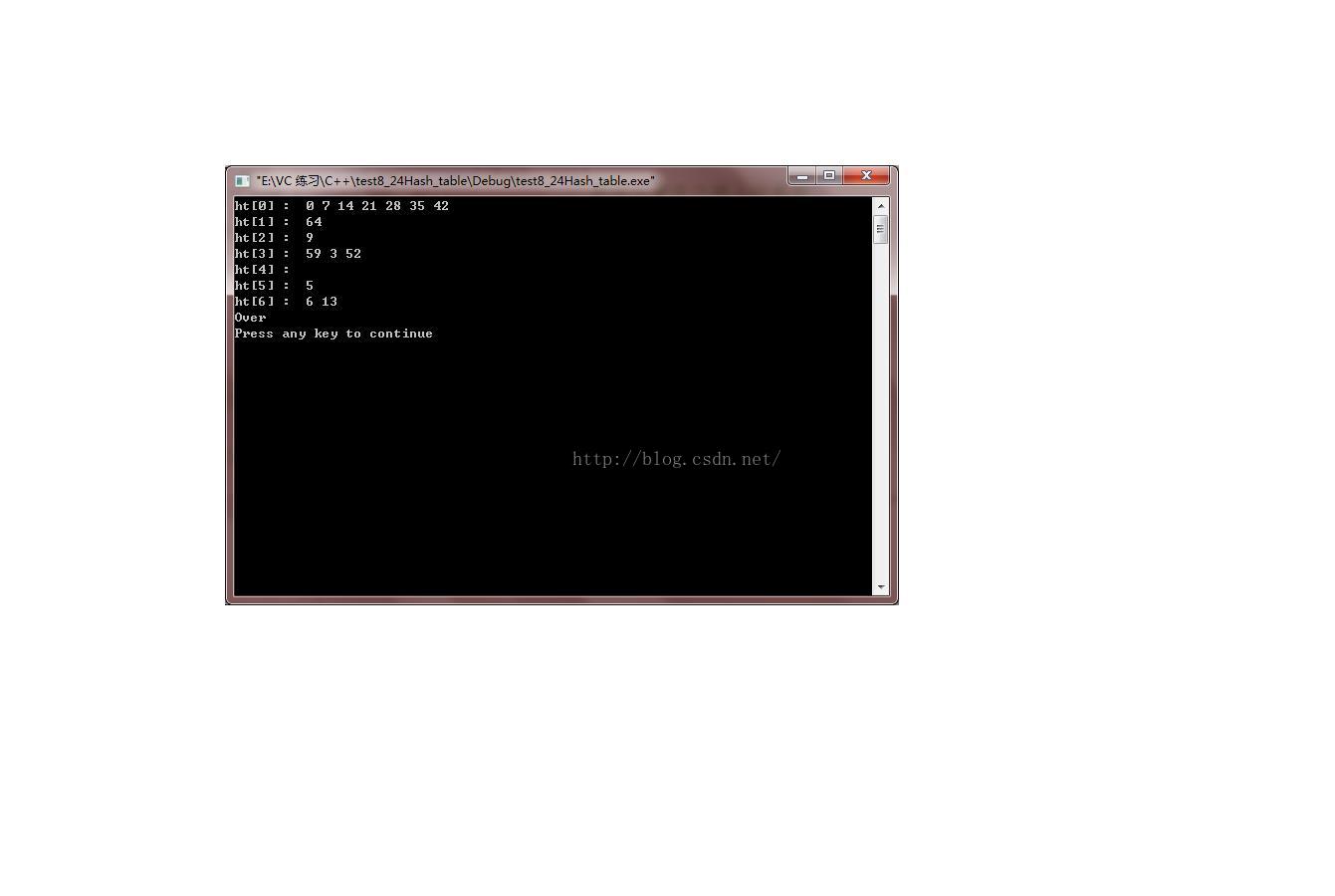
如果数据较多(足够多)的话,插入的元素应该均匀地分布在哈希表中,也就是每个节点元素后面的链长度应该相等.