import re
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as pq
import pymongo
SERVICE_ARGS = ['--load-images=false','--disk-cache=true']
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_TABBLE='clothes'
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
browser= webdriver.PhantomJS(service_args=SERVICE_ARGS)
browser.set_window_size(1400,900)
wait = WebDriverWait(browser, 10)
def save_to_mongo(result):
try:
db[MONGO_TABBLE].insert(result)
print(result, "存储到mongodb成功")
except Exception:
print(result, "存储到mongodb不成功")
def search():
print("正在搜索")
try:
browser.get('http://taobao.com')
Input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#q'))
)
Sumbit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button'))
)
Input.send_keys('衣服')
Sumbit.click()
total = wait.until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'total')))[0]
return total.text
except TimeoutException:
return search()
def next_page(page_number):
print("正在翻页",page_number)
try:
Input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > input'))
)
Sumbit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit'))
)
Input.clear()
Input.send_keys(page_number)
Sumbit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(page_number)))
get_products()
except TimeoutException:
return next_page(page_number)
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html = browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'title': item.find('.title').text(),
'price' : item.find('.price').text(),
'deal' : item.find('.deal-cnt').text()[:-3],
'shop': item.find('.shop').text(),
'location': item.find('.location').text(),
'image': item.find('.pic .img').attr('src'),
}
save_to_mongo(product)
def main():
total = search()
total=int(re.compile('(\d+)').search(total).group(1))
for i in range(2,total+1):
next_page(i)
browser.close()
if __name__ == '__main__':
main()
以上是源码
可供参考的网址包括
http://phantomjs.org/
http://selenium-python.readthedocs.io/index.html
https://sites.google.com/a/chromium.org/chromedriver/
接下来是结果
图片一
图片二
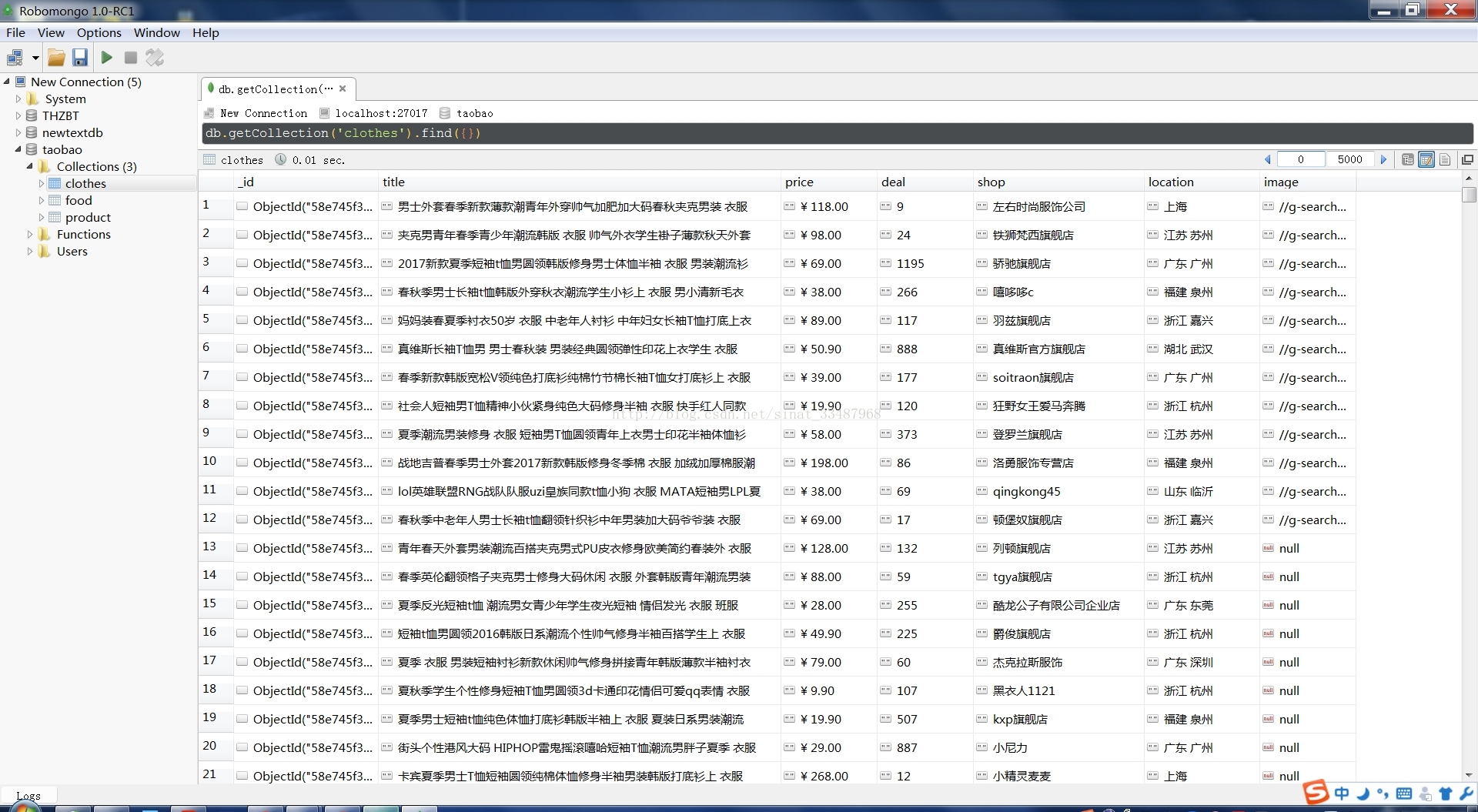
衣服只是其中冰山一角,可以切换不同的关键词搜索,数据爬取是第一步,怎么分析和使用更加重要。我会继续前进。