Kaggle 上的比赛, 识别12种类型的植物,部分图片如下:

预处理
这里参考Gábor Vecsei的kernel,将叶片从背景中提取出来
训练
使用keras中的Xception模型,数据增加部分使用了[-180°,180°]的随机旋转,0.3的随机平移,0.3的随机放缩与随机翻转,代码如下:
batch_size = 16
train_img = np.zeros([4750, img_size, img_size, 3])
train_label = np.zeros([4750, 1])
i = 0
for index, label in tqdm(enumerate(labels), total=len(labels)):
for file in os.listdir('seg_train/' + label):
im = imread('seg_train/{}/{}'.format(label, file))
train_img[i,:,:,:] = imresize(im[:,:,:3], (img_size, img_size))
train_label[i] = index
i += 1
train_label = np_utils.to_categorical(train_label, 12)
datagen = ImageDataGenerator(preprocessing_function=preprocess_input,
rotation_range=180,
width_shift_range=0.3,
height_shift_range=0.3,
zoom_range=0.3,
horizontal_flip=True,
vertical_flip=True)
datagen.fit(train_img)
base_model = Xception(weights='imagenet', input_shape=(img_size, img_size, 3), include_top=False)
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(1024, activation='relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(12, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.compile(optimizer='Adadelta',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit_generator(datagen.flow(train_img, train_label, batch_size=batch_size), steps_per_epoch=len(train_img)//batch_size, epochs=100, verbose=1)
model.save_weights('Xception.h5')预测
在预测时同时使用了数据增强,对一张图片预测100次,对预测结果求和取最大,代码如下:
datagen = ImageDataGenerator(preprocessing_function=preprocess_input,
rotation_range=180,
width_shift_range=0.3,
height_shift_range=0.3,
zoom_range=0.3,
horizontal_flip=True,
vertical_flip=True)
base_model = Xception(weights=None, include_top=False, input_shape=(img_size, img_size, 3))
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(1024, activation='relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(12, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.load_weights('Xception.h5')
with open('submission.csv', 'w') as f:
f.write('file,species\n')
for file in tqdm(os.listdir('seg_test/')):
img = image.load_img(os.path.join('seg_test', file), target_size=(img_size, img_size))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
pred = np.zeros([12,])
for i, im in enumerate(datagen.flow(x)):
pred += model.predict(im)[0]
if i > 100:
break
f.write('{},{}\n'.format(file, labels[np.where(pred==np.max(pred))[0][0]]))最终得分:0.98614,Public Leaderboard排名47/836(top 6%)
18.6.21更新 :冠军方案
方案中分5个step:
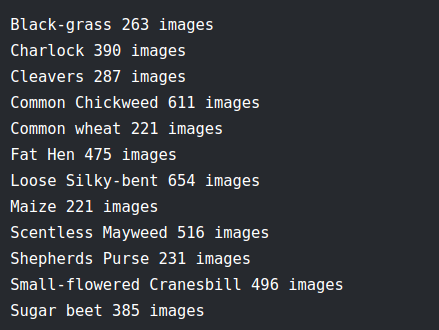
- step1:分析了数据集的结构,发现这个数据集是imbalance的,然后划分20%作为验证集。
- step2:使用keras.application中的ResNet50和InceptionResNetV2作为benchmark。
- step3:balance data,这里使用了两种方法:
- Adaptive synthetic sampling approach for imbalanced learning (ADASYN)
- Synthetic Minority Over-sampling Technique (SMOTE)
当数据balance后,进行图像增强,包括: Scaling,Cropping,Flipping,Rotation,Translation,Adding Noise,Changing lighting conditions。
- step4:学习率的设置,以及Snapshot Ensembling方法的使用。
- step5:用混淆矩阵可视化结果,获得最佳超参,将验证集也放入训练集中。