自定义View系列教程00–推翻自己和过往,重学自定义View
自定义View系列教程01–常用工具介绍
自定义View系列教程02–onMeasure源码详尽分析
自定义View系列教程03–onLayout源码详尽分析
自定义View系列教程04–Draw源码分析及其实践
自定义View系列教程05–示例分析
自定义View系列教程06–详解View的Touch事件处理
自定义View系列教程07–详解ViewGroup分发Touch事件
自定义View系列教程08–滑动冲突的产生及其处理
探索Android软键盘的疑难杂症
深入探讨Android异步精髓Handler
详解Android主流框架不可或缺的基石
站在源码的肩膀上全解Scroller工作机制
Android多分辨率适配框架(1)— 核心基础
Android多分辨率适配框架(2)— 原理剖析
Android多分辨率适配框架(3)— 使用指南
讲给Android程序员看的前端系列教程(图文版)
讲给Android程序员看的前端系列教程(视频版)
Android程序员C语言自学完备手册
版权声明
- 本文原创作者:谷哥的小弟
- 作者博客地址:http://blog.csdn.net/lfdfhl
在C语言中字符都作为非负整数来处理。也就是说,每一个字符都有与之对应的编码(非负整数值)。但是,即时是同一个字符,在不同的程序运行环境中编码也会有所不同;具体要视程序运行时所用的字符编码而定。在此介绍几种常见的编码。
ASCII
我们知道:计算机在保存数据(例如:文本,图片,视频等)时全部都是用0和1的组合来表示的,更简单和通俗地说:计算机的底层只有0和1,除此以外别无他物。嗯哼,在美国人发明计算机的时候就遇到一个问题了:怎么样把26个英文字母、10个阿拉伯数字、常用的符号(例如句号,问号,空格,换行,制表符)保存到计算机中呢?于是,美国人制作了一张叫做ASCII的表用于将信息翻译成二进制数据。请看如下表格:

从这张表中我们可以看出来:
在ASCII表中用一个字节的低7位表示一个ASCII码,也就是说表中的二进制组合的最高位均是0;所以在ASCII表中共有128个ASCII码。
其中0—31表示控制字符,例如回车,换行等;32—126属于打印字符,这些字符都可以通过键盘输入并且能够显示出来;127代表DELETE删除。
在此列举我们几个熟悉的常用的ASCII码:
00110000(即十进制的48)表示数字0
01000001(即十进制的65)表示字母A
01100001(即十进制的97)表示字母a
00110000(即十进制的48)——00111001(即十进制的57)表示数字0—9
ISO-8859
随着社会和计算机技术的发展,原来的ASCII表中的128个ASCII码已经有些不够用,显得捉襟见肘了。于是国际标准化组织(International Organization for Standardization,ISO)在ASCII码表的基础上进行了扩展形成了新的码表即ISO-8859-1至ISO-8859-15。其中ISO-8859-1涵盖了大多数西欧语言中的字符,所以应用得最为广泛。ISO-8859-1依然是单字节编码,它总共能表示256个字符,关于扩充的128个字符请参见下表:
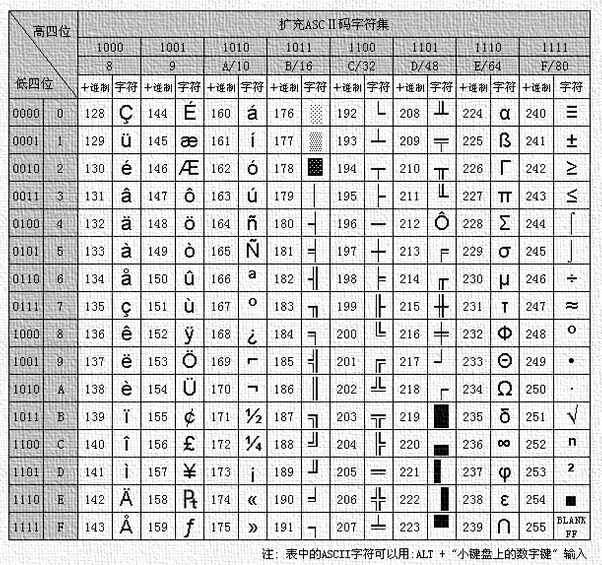
从这张表中我们可以看出:
- ISO-8859-1在ASCII表的基础上扩展了128个码
- 扩展的128个码从10000000(即十进制128)开始到11111111(即十进制255)结束
GBK
GBK全称《汉字内码扩展规范》(英文名称:Chinese Internal Code Specification)由中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订。它采用双字节编码,编码范围是8140~FEFE(去掉XX7F),能够表示21003个汉字。
UTF-8
ISO试图建立一张能够囊括世界上所有语言的超级码,即Unicode(Universal Code 统一码)。关于Unicode的详细规范,请大家参阅官方文档。UTF-16(16-bit Unicode Transformation Format)具体定义了Unicode字符在计算机中的存取方法,它采用两个字节表示任一字符。这么做虽然简单和方便,但是也带来一个问题:有的字符明明可以用一个字节就可以表示了却非要用两个字节表示,造成了极大的浪费。在这个背景之下诞生了UTF-8。
UTF-8采用了变长技术,不同类型的字符可由1—6个字节组成。常用的英文字母和数字已经常见符号被编码成1个字节,汉字通常是3个字节,很生僻的字符将会被编码成4-6个字节
练习1
请显示本机环境下EOF和0—9字符所对应的值(编码)
#include <stdio.h>
#include <stdlib.h>
int main()
{
int i;
printf("EOF=%d\n",EOF);
for(i=0;i<10;i++){
printf("%d=%d\n",i,'0'+i);
}
return 0;
}
运行结果如下:
EOF=-1
0=48
1=49
2=50
3=51
4=52
5=53
6=54
7=55
8=56
9=57
从这里我们验证了,在本机环境下EOF的值为-1.
或许有人对于代码printf("%d=%d\n",i,'0'+i);中的'0'+i有些困惑。别急,还记得ASCII码表中字符0(即’0’)所对应的十进制是48、字符1(即’1’)所对应的十进制是49、字符2(即’2’)所对应的十进制是50…以此类推,它们依次在前者的基础上加1;所以,在此巧妙的利用该特性——当i属于0至9时'0'+i表示的就是i所对应的值。
在该示例中,有人或许有点疑问:怎么输入EOF呢?或者说在DOS中怎么终止输入呢?方法如下:
- 最后一行的末尾(此时未换行)输入ENTER键
- 在新的一行同时按下ctrl+z后再输入时ENTER键即可。
- OK
练习2
请统计文本中各个数字的出现次数
#include <stdio.h>
#include <stdlib.h>
int main()
{
int i,ch;
int count[10]={0};
while((ch=getchar())!=EOF){
if(ch>='0'&&ch<='9'){
count[ch-'0']++;
}
}
puts("各数字出现的次数如下:");
for(i=0;i<10;i++){
printf("'%d':%d\n",i,count[i]);
}
return 0;
}
在该示例中建立了长度为10的数组count用于存放0—9每个数字出现的次数,即数字0出现的次数存放于count[0]中、数字1出现的次数存放于count[1]中、数字2出现的次数存放于count[2]中…以此类推。所以,count[ch-'0']++;中的ch-'0'刚好是该字符(即ch)在数组中存放位置的下标值。