CNN研究者总是面临一个共同的话题:如何提升神经网络的表达能力?
分两个方向去探讨:
1)拉长
增加网络层数是最直观的一种方法,但这种方法所面临的是 梯度消失问题,网络越深,梯度的回传越困难。
基于此,MSRA提出了ResNet,通过skipconnection的方式,通过残差思想很好的解决了这个问题。
可以参考论文:Deep Residual Learning forImage Recognition
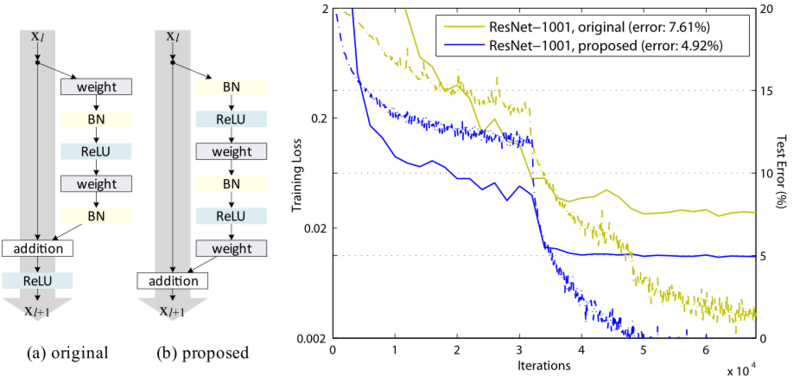
这一版本的 ResNet存在一个问题,作者也open了出来,并且很快提出了解决方案:
Identity Mappings in DeepResidual Networks
去掉了最外面的relu层,实现了Identity mapping,在1001层的网络上表现相当强悍(感叹一下,把一篇文章能解决的问题 凑两次,大神也套路)
2)变宽
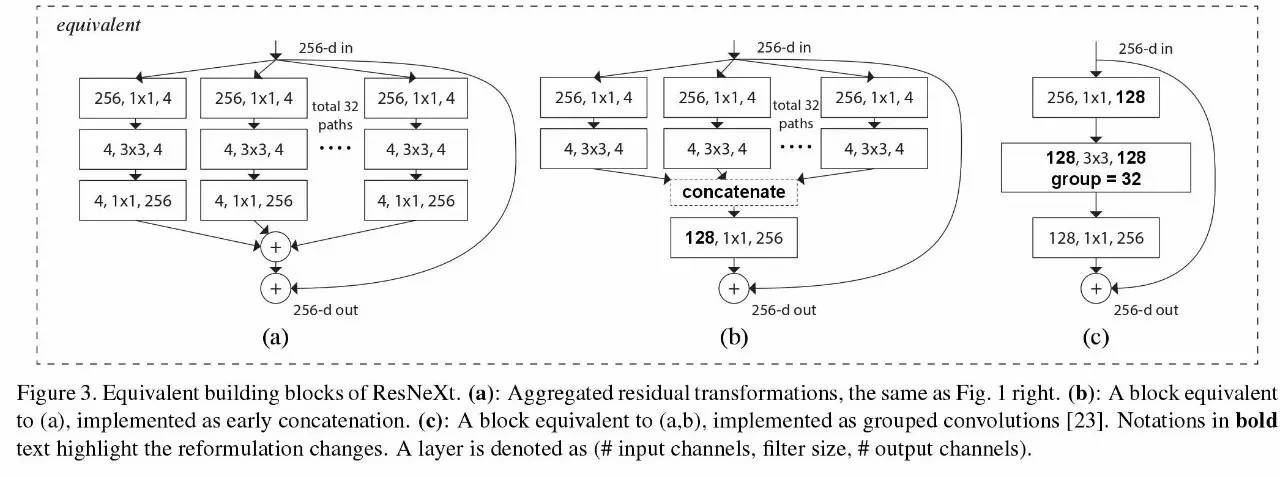
变宽的思路包括很多种,主要做法就是拆分卷积层,每层通过不同的卷积核来引入提取的多样性,通过concat或者其他joint方式来合并,比如Inception、ResNext等。

3)结构优化
结构优化的方向比较多,比如常用的方法:
A)修改激活函数
包括PReLU、LReLU、CReLU、ELU、SELU等
B)定义卷积核
比如1*3的卷积核,膨胀卷积,不规则卷积等;
C)Batch Normalization(BN)和Layer Normalization(LN)、多尺度
D)Weight Normalization
即通过重写权值w来加速深度网络的参数收敛
A Simple Reparameterizationto Accelerate Training of Deep Neural Networks
4)轻量级网络
通过Pruning、量化等方法来压缩网络,在相同计算量的情况下,构造最优的网络。
l DiracNets
本文提出的DiracNet,是属于 Weight Normalization 的一种,先来认识一下dirac函数:
Dirac函数比较简单,公式描述为:
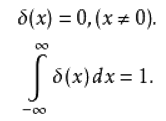
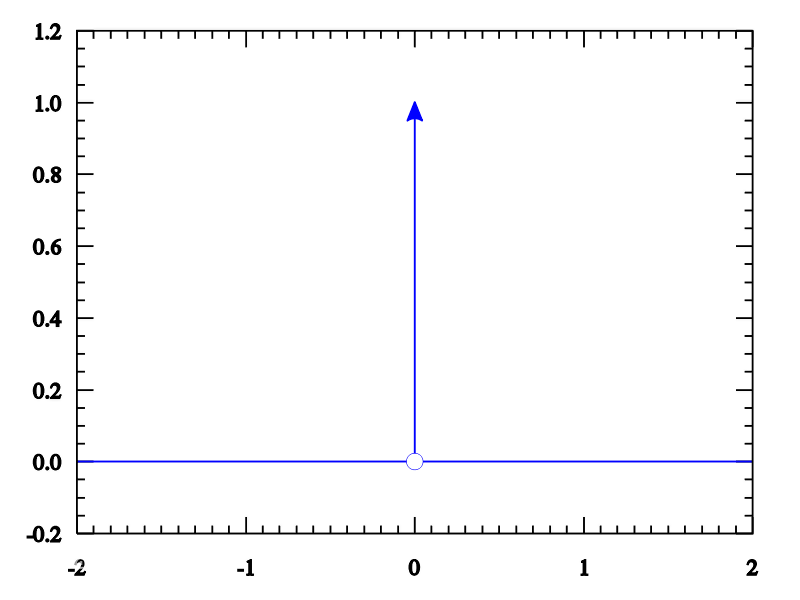
即在x=0点值为1,其它值为0,定义区间上积分为1,示意图:
其中卷积函数定义为(x为input,I为单位矩阵):

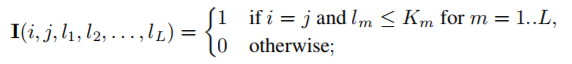
不考虑bias的情况:

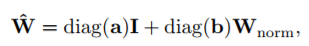
a,b都是通过训练得到,其中a初始化为1.0,b初始化为0.1,
对于每一个滤波器(Filter),W是按照欧式距离归一化后得到的权重向量。