1、Hadoop介绍
Hadoop主要是一个分布式基础架构,用户可以不用了解详细分布式的底层细节实现,只需要编写简单的逻辑程序,便可以实现分布式计算。其大致可以分为三部分:HDFS文件集群、MapReduce数据处理、yarn资源调度集群。
HDFS文件集群:负责文件如何保存读取,例如如何将一个文件分为block,分别存在哪些计算机中?以及读取的时候如何根据namenode的信息在datanode中进行block的读取以及拼接成一个完整的文件;
MapReduce数据处理:Hadoop对数据处理只要有两个方面,一个是map,负责如何进行数据处理,例如一个简单的word count程序,map就是负责将不同的单词作为key,而该词出现的次数作为value进行处理,map一次读取一行,所以说这里map的程序很简单,这里你不用考虑如何进行分布式读取,以及读取了多少个数据,只需要只要你输入的文件格式是什么样的,输出什么样便可以,reduce程序接受map阶段的输出作为它的输入,还是举个例子,比如我收到了上一个阶段的输出,maper1 <hello,1,1,1,1,1,>,<hi,1,1,1>, maper2<hello,1,1,>,<hi,1>,reduce的程序也很简单,就是将hello的次数递归进行累加便可,最后reduce的输出为<hello,7>,<hi,5>。
yarn集群:当你将任务提交了之后,那么这些文件如何进行处理呢?我们的MapReduce程序只是进行了任务的逻辑程序的编写,如何运行呢?怎么分配资源呢?不同的节点怎么都会有我们的逻辑处理程序呢?这里就需要yarn资源调度集群了。
理解一门技术虽好的方式是知道它要解决什么样的问题,如何实现这些问题?因此这时候你可能就对Hadoop有了一个简单的理解,这时候就可以深入的学习了。
2、Hadoop安装
Hadoop的安装还是比较费劲的,没有封装的很好,但是很考验大家,安装也是一个学习的过程。
很多人会纠结安装虚拟机,还是直接在linux下搭建,其实是都可以的,看个人的喜好,不论在哪安装,步骤都想差不多。
这篇安装文档写的挺好的,推荐给大家http://www.powerxing.com/install-hadoop/
推荐安装流程:
首先会是java的安装,因为接下来MapReduce程序的编写都是java写的,因此你需要先安装一个java的环境,其次安装eclipse,eclipse是java的开发软件,在里面可以实现想visual studio 一样的开发功能,eclipse直接装java开发那个便可以。接下来就是Hadoop的安装了,记住一定要下载2.X版本的,以为只有这个版本才有了真正的yarn资源调度,这是一个很大的改进。之所以所Hadoop安装比较麻烦的是他的配置,初学者不知道那些配置有什么用,不配会不会出错?此处的配置主要是针对伪分布式搭建来说的,本地模式一般不用额外的配置,其中主要是core-site.xml和hdfs-site.xml的配置,为什么要配置这两个文件呢?主要还是开发的时候,我们一般会用到文件管理,而文件管理实例的生成需要读取conf内容,而conf里面的关键内容在这两个.xml文件中,因此需要额外进行修改配置。一般情况下,我们都是远程进行登录Linux服务器,其中都是通过SSH进行通讯的,因此我们要设置SSH免密登录,否则每次每台机器都要输入密码。
配置完成后,还有一步要做,否则无法在根目录下进行Hadoop相关命令的操作。
在/etc/profile文件中添加hadoop的安装路径,sudo vim /etc/profile 在最后加入

export HADOOP_HOME=本机的hadoop安装路径(bin 或者 sbin目录的上一级便可)
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
最后 source /etc/profile 是刚刚的改动生效便可。
Hadoop的启动及指令:
运行该脚本,/usr/local/hadoop/sbin/start-dfs.sh和start-yarn.sh
通过jps指令可以看出Hadoop已经启动了,有下面这几个进程在运行。
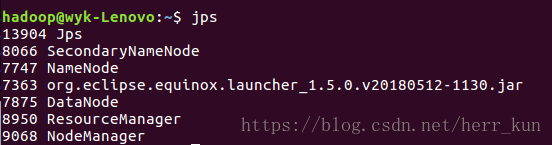
然后便可以进行一些指令的练习编写了,分享一个截图:其中可以看到有ls chmod等Linux下常见的命令,很好上手。

3、第一程序,从HDFS文件系统上进行文件下载
首先你要想进行下载,我们就要先上传一个文件:
命令:hadoop fs -put XXXXXX(file) hdfs://localhost:9000/
通过在浏览其中打开hdfs://localhost:50070/网页,找到utilities ,打开browse directory,如下图所示:可以看到我们上传的文件。

接下来主要是eclipse下java程序的编写,这里暂时不涉及到MapReduce程序的编写,直接上图解释:

首先左侧最下方为我们自己添加的Hadoop库,还有core-site.xml和hdfs-site.xml的添加,conf会进行读取。
最后运行,会在目录下看到我们想要的文件。
其中有一点需要注意,程序中我设置的是/tmp目录,其他目录因为权限设置,不能随意写入,这个是777权限。
剧中。。。。。