转载请标明出处:
https://blog.csdn.net/xmxkf/article/details/82465726
本文出自:【openXu的博客】
从数据结构的定义看,栈和队列也是一种线性表。其不同之处在于栈和队列的相关运算具有特殊性,只是线性表相关运算的一个子集。更准确的说,一般线性表的插入、删除运算不受限制,而栈和队列上的插入删除运算均受某种特殊限制。因此,栈和队列也称作操作受限的线性表。
1、栈
1.1 栈的定义
栈(Stack)是一种只能在一端进行插入或删除操作的线性表。表中允许进行插入、删除操作的一端称为栈顶(Top)。栈顶的当前位置是动态的,栈顶的当前位置是由一个称为栈顶指针的位置指示器指示。表的另一端称为栈底(Bottom)。当栈中没有数据元素时称为空栈。栈的插入操作称为进栈或入栈(Push),删除操作称为退栈或出栈(Pop)。
栈的主要特点是“后进先出”,即后进栈的元素先弹出。每次进栈的数据元素都放在原当前栈顶元素之前成为新的栈顶元素,每次出栈的数据元素都是当前栈顶元素。栈也称为后进先出表。
1.2 栈的顺序存储结构实现
通常栈可以用顺序的方式存储,分配一块连续的存储区域存放栈中的元素,并用一个变量指向当前的栈顶。采用顺序存储的栈称为顺序栈,Java util包下的Stack就是顺序栈。
顺序栈的操作示意图如下:
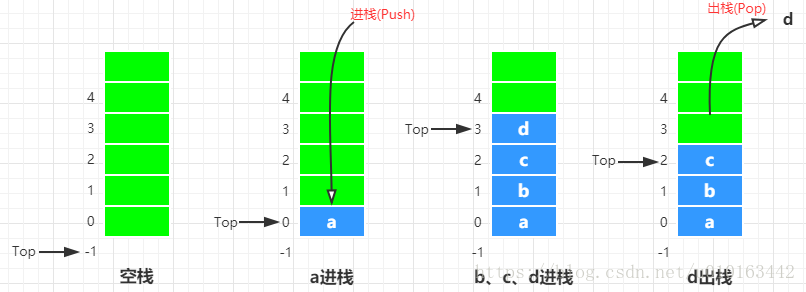
顺序栈的实现如下:
public class StackByArray<T>{
private int top = -1; //栈顶指针,-1代表空栈
private int capacity = 10; //默认容量
private int capacityIncrement = 5; //容量增量
private T[] datas; //元素容器
public StackByArray(int capacity){
datas = (T[])new Object[capacity];
}
public StackByArray(){
datas = (T[])new Object[capacity];
}
/**溢出扩容 */
private void ensureCapacity() {
int oldCapacity = datas.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
datas = Arrays.copyOf(datas, newCapacity);
}
/**进栈,将元素添加到栈顶*/
public synchronized void push(T item) {
//容量不足时扩容
if(top>=datas.length-1)
ensureCapacity();
datas[++top] = item;
}
/**出栈,将栈顶的元素移除并返回该元素*/
public synchronized T pop() {
if(top<0)
new EmptyStackException();
T t = datas[top];
datas[top] = null;
top--;
return t;
}
/**清空栈*/
public synchronized void clear() {
if(top<0)
return;
for(int i = top; i>=0; i--)
datas[i] = null;
top = -1;
}
/**返回栈顶元素*/
public T peek() {
if(top<0)
new EmptyStackException();
return datas[top];
}
/**获取栈中元素个数*/
public int getLength() {
return top+1;
}
/**栈是否为空栈*/
public boolean empty() {
return top<0;
}
/**获取元素到栈顶的距离 */
public int search(T data) {
int index = -1;
if(empty())
return index;
if (data == null) {
for (int i = top; i >= 0; i--)
if (datas[i]==null){
index = i;
break;
}
} else {
for (int i = top; i >= 0; i--)
if (data.equals(datas[i])) {
index = i;
break;
}
}
if (index >= 0) {
return top - index;
}
return index;
}
@Override
public String toString() {
if(empty())
return "[]";
StringBuffer buffer = new StringBuffer();
buffer.append("[");
for(int i = 0; i<=top; i++){
buffer.append(datas[i]+", ");
}
return buffer.subSequence(0, buffer.lastIndexOf(", "))+"]";
}
}1.3 栈的链式存储结构实现
采用链式存储结构的栈称为链栈,在链栈中规定所有操作都是在链表表头进行的,链栈的优点是不存在栈满上溢的情况。上述顺序栈的实现过程中增加了扩容的功能,所以也能实现不上溢。
链栈的操作示意图如下:
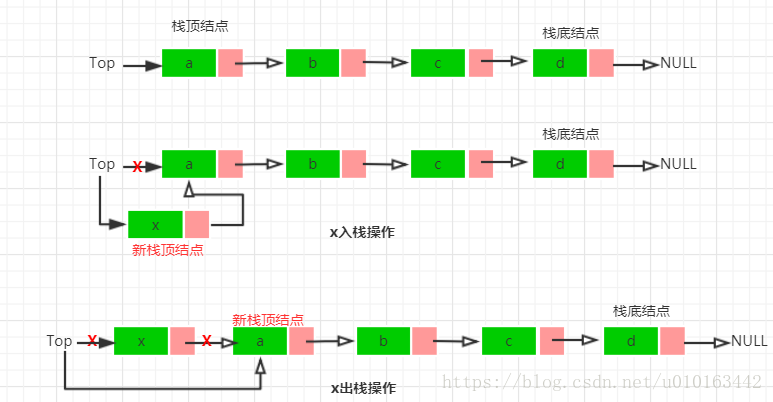
链栈的实现如下:
public class StackByLink<T>{
public LNode<T> top; //栈顶指针,指向栈顶结点
private int size = 0;
/**进栈,将元素添加到栈顶*/
public synchronized void push(T item) {
LNode temp = new LNode();
temp.next = top; //添加的结点的指针域指向当前栈顶结点
top = temp; //更新栈顶结点
size ++;
}
/**出栈,将栈顶的元素移除并返回该元素*/
public synchronized T pop() {
if(top==null)
new EmptyStackException();
LNode < T> next = top.next;
T data = top.data;
top.next = null;
top.data=null;
top = next;
size--;
return data;
}
/**清空栈*/
public synchronized void clear() {
LNode<T> next;
while(top!=null){
next = top.next;
top.data = null;
top.next = null;
top = next;
}
size = 0;
}
/**返回栈顶元素*/
public T peek() {
if(top==null)
new EmptyStackException();
return top.data;
}
/**获取栈中元素个数*/
public int getLength() {
return size;
}
/**栈是否为空栈*/
public boolean empty() {
return top==null;
}
/**获取元素到栈顶的距离 */
public int search(T data) {
int dis = -1;
if(empty())
return dis;
LNode<T> node = top;
if (data == null) {
while(node!=null){
dis ++;
if (node.data == null)
return dis;
}
} else {
while(node!=null){
dis ++;
if (node.data.equals(data))
return dis;
}
}
return dis;
}
@Override
public String toString() {
if(empty())
return "[]";
LNode node = top;
StringBuffer buffer = new StringBuffer();
buffer.append("[");
while(node != null){
buffer.append(node.data+", ");
node = node.next;
}
return buffer.subSequence(0, buffer.lastIndexOf(", "))+"]";
}
}
1.4 两种栈的效率分析
顺序栈和链式栈中,主要的操作算法push(T item)、pop()、 peek()的时间复杂度和空间复杂度都是O(1),从效率上都是一样的,因为栈只对一端进行操作。顺序栈和链式栈实现起来最大的区别就是链式栈不用考虑容量问题,而顺序栈会有上溢的情况,如果加上自动扩容,则push(T item)的时间复杂度将变为O(n)。所以链式栈相比会更加灵活一点。
1.5 栈的应用
栈是一种最常用也是最重要的数据结构质疑,用途十分广泛。在二叉树的各种算法中大量地使用栈,将递归算法转换成非递归算法时也常常用到栈;接下来我们用破解迷宫的算法示例栈的应用。
破解迷宫
给定一个M * N的迷宫图,求一条从指定入口到出口的路径。假设迷宫图如下图所示,白色表示通道,深色表示墙。所求路径必须是简单路径,即路径中不能重复出现同一通道块。为了表示迷宫,设置一个二维数组maze,其中每个元素表示一个方块的状态,0表示是通道,1表示该方块不可走。

在求解时,通常使用“穷举求解”的方法,即从入口出发,顺某一方向向前试探,若能走通,则继续往前走,否则眼原路退回,换一个方向在继续试探,直到所有可能的通道都试探完为止。
为了保证在任何为止上都能沿原路退回,需要用一个后进先出的栈来保存从入口到当前位置的路径。每次取栈顶的方块,试探这个方块下一个可走的方向(上方、右方、下方、左方),如果找到可走的方向,则将该方向下一个方块入栈,如果没有可走的下一个方块,说明该路死了,需要将当前栈顶元素出栈。为了保证试探的可走相邻方块不是已走路径上的方块,比如(i,j)已经入栈,在试探(i+1, j)的下一可走方块时又试探到(i,j),这可能会引起死循环,为此,在一个方块入栈后,将对应数组元素值改为-1(只有0才是可走),当出栈时,再将其恢复至0。
算法实现如下:
public static StackByArray<MazeElem> getMazePathByArrayStack(int[][] maze, int startX,
int startY, int endX, int endY){
int x = startX, y = startY; //用于查找下一个可走方位的坐标
boolean find; //是否找到栈顶元素下一个可走 的 方块
StackByArray<MazeElem> stack = new StackByArray();
//入口元素入栈
MazeElem elem = new MazeElem(startX, startY, -1);
stack.push(elem);
maze[x][y] = -1; //将入口元素置为-1,避免死循环
//栈不为空时循环
while(!stack.empty()){
elem = stack.peek(); //取栈顶元素
if(elem.x == endX && elem.y == endY){
//栈顶元素与出口坐标一样时,说明找到出口了
Log.e(TAG, "迷宫路径如下:\n"+stack);
return stack;
}
find = false;
//遍历栈顶元素的四个方向 ,找 栈顶 元素 下一个可走 方块
while(elem.di < 4 && !find){
elem.di++;
switch ((elem.di)){
case 0: //上方
x = elem.x-1; y = elem.y;
break;
case 1: //右方
x = elem.x; y = elem.y+1;
break;
case 2: //下方
x = elem.x+1; y = elem.y;
break;
case 3: //左方
x = elem.x; y = elem.y-1;
break;
}
//避免OutOfIndex
if(x>=0 && y>=0 && x<maze.length && y<maze[0].length)
find = maze[x][y]==0;
}
if(find){ //找到了下一个可走方向
stack.push(new MazeElem(x, y, -1)); //下一个可走方向入栈
maze[x][y] = -1; //入栈后置为-1,避免死循环
}else{
//栈顶元素没有下一个可走结点,则出栈,并将该方块置为0(可走)
elem = stack.pop();
maze[elem.x][elem.y] = 0;
}
}
return null;
}2、队列
2.1 队列的定义
队列简称队,它也是一种操作受限的线性表,其限制为仅允许在表的一端进行插入,而在表的另一端进行删除。把进行插入的一端称做队尾(rear),进行删除的一端称做队首或队头(front)。向队列中插入新元素称为进队或入队,新元素进入后就成为新的队尾元素;从队列中删除元素称为出队或离队,元素出队后,其直接后继元素就成为队首元素。
由于队列的插入和删除操作分别是在各自的一端进行的,每个元素必然按照进入的次序出队,所以又把队列称为先进先出表。
2.2 队的顺序存储结构实现
队列的顺序存储结构需要使用一个数组和两个整数型变量来实现, 利用数组顺序存储队列中的所有元素,利用两个整数变量分别存储队首元素和队尾元素的下标位置,分别称为队首指针和队尾指针。
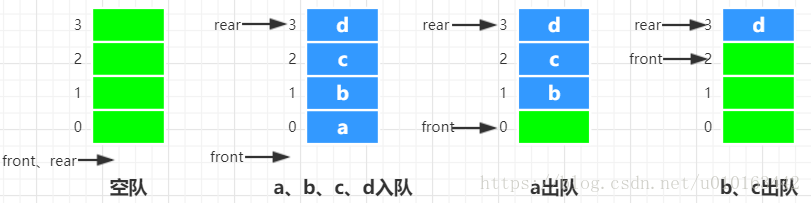
假设队列元素个数最大不超过MaxSize,当队列为初始状态有front==rear,该条件可作为队列空的条件。那么能不能用rear==MaxSize-1作为队满的条件呢?显然不能,如果继续往上图的队中添加元素时出现“上溢出”,这种溢出并不是真正的溢出,因为数组中还存在空位置,所以这是一种假溢出。
为了能充分的使用数组中存储空间,把数组的前端和后端连接起来,形成一个环形的顺序表,即把存储队列元素的表从逻辑上看成一个环,称为环形队列。如下如所示:
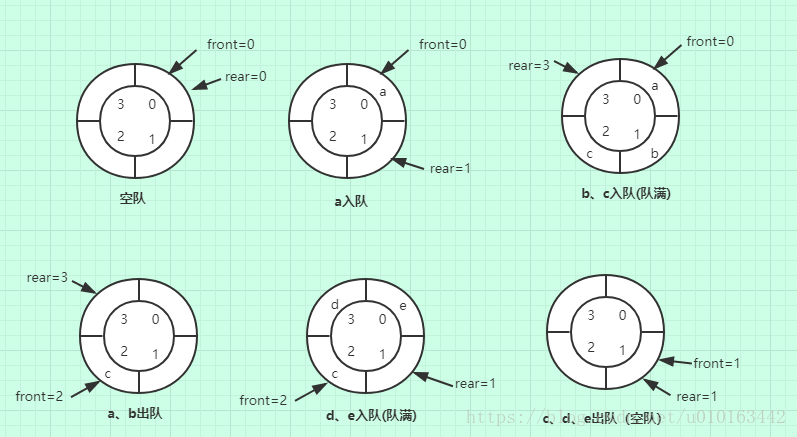
上图对应步骤解析如下:
- 初始化队列时,队首front和队尾rear都指向0;
- a入队时,队尾rear=rear+1指向1;
- bc入队后,rear=3,此时队已满。其实此时队中还有1个空位,如果这个空位继续放入一个元素,则rear=front=0,这和rear=front时队为空冲突,所以为了算法设计方便,此处空出一个位。所以判断队满的条件是(rear+1)%MaxSize == front
- ab出队,队首front=2;
- de入队,此时rear=1;满足(rear+1)%MaxSize == front,所以队满
- cde出队,此时rear=front=1,队空
通过上述分析,我们可以得出,出队和入队操作会使得队首front队尾rear指向新的索引,由于数组为环状,可通过求余%运算来实现:
入队(队尾指针进1):rear = (rear+1)%MaxSize
出队(队首指针进1):front = (front+1)%MaxSize
当满足 rear==front时,队列为空,我们可以在出队操作后,判断此条件,如果满足则说明队列为空了,可以将rear和front重新指向0;
当需要入队操作时,首先通过(rear+1)%MaxSize == front判断是否队满,如果队满,则需要空充容量,否则会溢出。对于环形队列的讲解就到这里,下面是实现代码:
public class QueueByArray<T>{
private int front = 0; //队首指针(出队)
private int rear = 0; //队尾指针(入队)
private int size; //元素个数
private int capacity = 10; //默认容量
private int capacityIncrement = 5; //容量增量
private T[] datas; //元素容器
public QueueByArray(int capacity){
datas = (T[])new Object[capacity];
}
public QueueByArray(){
datas = (T[])new Object[capacity];
}
public int getFront() {
return front;
}
public void setFront(int front) {
this.front = front;
}
public int getRear() {
return rear;
}
public void setRear(int rear) {
this.rear = rear;
}
/**获取队中元素个数*/
public int getSize() {
return rear - front;
// return size;
}
/**是否为空队*/
public boolean isEmpty() {
return rear==front;
}
/**入队*/
public synchronized boolean enQueue(T item) {
if(item==null)
throw new NullPointerException("item data is null");
//判断是否满队
if((rear+1) % datas.length == front){
//满队时扩容
ensureCapacity();
}
//添加data
datas[rear] = item;
//更新rear指向下一个空元素的位置
rear = (rear+1) % datas.length;
size++;
return true;
}
/**双端队列 从队首入队*/
public synchronized boolean enQueueFront(T item) {
if(item==null)
throw new NullPointerException("item data is null");
//判断是否满队
if((rear+1) % datas.length == front){
//满队时扩容
ensureCapacity();
}
//使队首指针指向上一个空位
front = (front-1+datas.length)%datas.length;
//添加data
datas[front] = item;
size++;
return true;
}
/**溢出扩容 */
private void ensureCapacity() {
int oldCapacity = datas.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
T[] oldDatas = datas;
datas = (T[])new Object[newCapacity];
int j = 0;
//将原数组中元素拷贝到新数组
for (int i = front; i!=this.rear ; i = (i+1) % datas.length) {
datas[j++] = oldDatas[i];
}
//front指向新数组0的位置
front = 0;
//rear指向新数组最后一个元素位置
rear = j;
}
/**出队*/
public synchronized T deQueue() {
if(isEmpty())
return null;
T t = datas[front];
datas[front] = null;
//front指向新的队首元素
front = (front+1) % datas.length;
size --;
return t;
}
/**双端队列 从队尾出队*/
public synchronized T deQueueRear() {
if(isEmpty())
return null;
//队尾指针指向上一个元素位置
rear = (rear-1+datas.length)%datas.length;
T t = datas[rear];
datas[rear] = null;
size --;
return t;
}
/**清空队列*/
public synchronized void clear() {
while(!isEmpty()){
deQueue();
}
front = rear = 0;
}
/**返回队首元素*/
public T peek() {
if(isEmpty())
return null;
return datas[front];
}
public T getElement(int index) {
if(isEmpty() || index>=datas.length)
return null;
T t = datas[index];
return t;
}
@Override
public String toString() {
if(isEmpty())
return "[]";
StringBuffer buffer = new StringBuffer();
buffer.append("[");
int mFront = front;
while(mFront!=rear){
buffer.append(datas[mFront]+", ");
mFront = (mFront+1) % datas.length;
}
return buffer.subSequence(0, buffer.lastIndexOf(", "))+"]";
}
}
2.3 双端队列
如果允许在环形队列的两端都可以进行插入和删除操作,这样的队列称为双端队列。上面的环形队列中,只能从队尾入队,队首出队,在双端队列中,队首和队尾都能出队入队。相关算法如下:
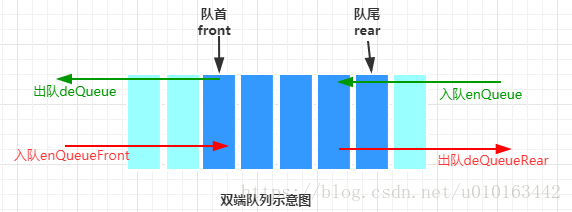
/**双端队列 从队首入队*/
public synchronized boolean enQueueFront(T item) {
if(item==null)
throw new NullPointerException("item data is null");
//判断是否满队
if((rear+1) % datas.length == front){
//满队时扩容
ensureCapacity();
}
//使队首指针指向上一个空位
front = (front-1+datas.length)%datas.length;
//添加data
datas[front] = item;
size++;
return true;
}
/**双端队列 从队尾出队*/
public synchronized T deQueueRear() {
if(isEmpty())
return null;
//队尾指针指向上一个元素位置
rear = (rear-1+datas.length)%datas.length;
T t = datas[rear];
datas[rear] = null;
size --;
return t;
}
2.4 队列的链式存储结构实现
链式存储结构有单链表和双链表,对于链队的实现,使用单链表就足以满足需求(双链表由于多了前驱指针,存储密度不如单链表,造成空间浪费)。下面我们使用单链表实现链队,操作示意图如下:
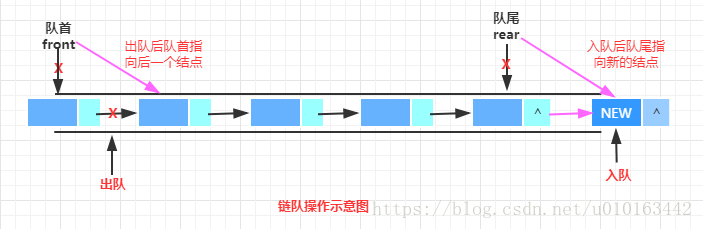
从上图中,我们可以知道如下几点:
- 使用front指向队首结点,rear指向队尾结点;
- 当队为空时,front = rear = null,并约定以此作为队列为空的判断条件;
- 入队时,使当前队尾结点的后继指针指向新结点rear.next = newNode,然后使队尾指针rear指向新结点
- 出队时,删除队首结点,使front = front.next
- 链队不会出现溢出的情况,这比使用数组实现的顺序队列更加灵活
链队的分析就到这里,接下来我们实现链队的基本操作算法:
public class QueueByLink<T>{
private LNode<T> front; //队首指针
private LNode<T> rear; //队尾指针
private int size; //元素个数
/**获取队中元素个数*/
public int getSize() {
return size;
}
/**队列是否为空*/
public boolean isEmpty() {
return front==null && rear==null;
}
/**入队*/
public synchronized boolean enQueue(T item) {
if(item==null)
throw new NullPointerException("item data is null");
LNode<T> newNode = new LNode();
newNode.data = item;
if (front == null) {
//向空队中插入,需要将front指针指向第一个结点
front = newNode;
} else {
//非空队列,队尾结点的后继指针指向新结点
rear.next = newNode;
}
rear = newNode; //队尾指针指向新结点
size ++;
return true;
}
/**出队*/
public synchronized T deQueue() {
if(isEmpty())
return null;
T t = front.data;
front = front.next;
if (front == null) //如果出队后队列为空,重置rear
rear = null;
size--;
return t;
}
/**返回队首元素*/
public T peek() {
return isEmpty()? null:front.data;
}
/**清空队列*/
public synchronized void clear() {
while(!isEmpty()){
deQueue();
}
front = rear = null;
size = 0;
}
@Override
public String toString() {
if(isEmpty())
return "[]";
StringBuffer buffer = new StringBuffer();
buffer.append("[");
LNode mFront = front;
while(mFront!=null){
buffer.append(mFront.data+", ");
mFront = mFront.next;
}
return buffer.subSequence(0, buffer.lastIndexOf(", "))+"]";
}
}
2.5 队列的应用
队列的使用也是非常广泛的,比如android中MessageQueue就是利用队列实现的。这里我们继续使用1.5中迷宫破解问题示例队列的应用。
破解迷宫
在1.5中使用栈来破解迷宫,是利用穷举的思想,尝试沿着一条路走下去,走不通回退,继续尝试下一条路,直到找到出口。通过这种方式求出的路径不一定是最短路径,这跟尝试的方向有关系(上左下右),如果向上走时能一直走到出口,则会忽略掉左下右等方向的更短的路径。
这里我们使用队列来求解,假设当前点位为(x, y),在队列中的索引为front,遍历该位置的四个方位,如果方位可走则入队,并记录这个方位元素的前驱为front。如下图所示,当前点位上方的点位不可走,不入队;右方可走,入队;下方可走入队;左方可走入队;然后将front++,这时候当前点位变成(x, y+1),继续遍历它的四个方位,淘汰掉不可走的,可走的方位都会入队……。这样一层一层向外扩展可走的点,所有可走的点位各个方向都会尝试,而且机会相等,直到找到出口为止,这个方法称为“广度优先搜索方法”。然后我们从出口反向找其上一个方块的下标,直到下标为0,这个反向过程就能找到最短路径。由于此处需要通过索引获取队列元素,所以使用顺序队列来实现,因为链式存储结构查找不方便。
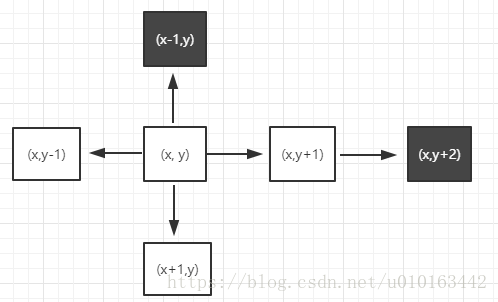
当然最短路径可能不止一条,具体求得的是那一条也是跟方位遍历顺序有关系的,这里就不做讨论。下面看看算法的实现:
public static QueueByArray<MazeElem> getMazePathByArrayQueue(int[][] maze, int startX,
int startY, int endX, int endY){
int x, y, di;
QueueByArray<MazeElem> queue = new QueueByArray();
//入口元素进队
MazeElem elem = new MazeElem(startX, startY, 0,-1);
queue.enQueue(elem);
maze[startX][startY] = -1; //将入口元素置为-1,避免回过来重复搜索
int front = 0; //记录当前操作的可走方块在队列中的索引
//队列不为空且未找到路径时循环
while(front<=queue.getRear()){
x = queue.getElement(front).x;
y = queue.getElement(front).y;
if(x == endX && y == endY){ //找到了出口
int k = front, j;
//反向找到最短路径,将该路径上的方块的pre设置为-1
do{
j = k;
k = queue.getElement(k).pre; //上一个可走方块索引
queue.getElement(j).pre = -1; //将路径上的元素的pre值为-1
}while(k!=0);
//返回队列,队列中pre为-1的元素,构成最短路径
return queue;
}
for(di = 0; di<4; di++){ //循环扫描每个方位,把每个可走的方块插入队列中
switch (di){
case 0: //上
x = queue.getElement(front).x-1;
y = queue.getElement(front).y;
break;
case 1: //右
x = queue.getElement(front).x;
y = queue.getElement(front).y+1;
break;
case 2: //下
x = queue.getElement(front).x+1;
y = queue.getElement(front).y;
break;
case 3: //左
x = queue.getElement(front).x;
y = queue.getElement(front).y-1;
break;
}
if(x>=0 && y>=0 && x<maze.length && y<maze[0].length){
if(maze[x][y] == 0){
//将该相邻方块插入队列
queue.enQueue(new MazeElem(x, y, 0, front));
maze[x][y] = -1; //赋值为-1,避免回过来重复搜索
}
}
}
front ++;
}
return null;
}3、优先级队列
优先级队列是一种特殊的队列,其元素具有优先级别,在遵循普通队列“先进先出”原则的同时,还有优先级高的元素先出队的调度机制。比如操作系统中进程调度管理就是利用优先队列的思想,在同级进程中按照“先来先处理”的原则,对于某些高优先级别的特殊进程则可插队,优先级高的先处理。这就像火车站取票一样,首先得排队,先来的先取票,但是某些人的票离发车时间很近了,他的紧急程度很高,即使来的晚,他们可以说说好话插个队。
优先级队列可分为“降序优先级队列”和“升序优先级队列”。“降序优先级队列”优先级高的先出队;“升序优先级队列”则是优先级底的先出队。像进程调度管理、火车站取票等都是降序优先级队列,一般情况下我们所说的优先队列都是指降序优先级队列。
优先级队列的实现和普通队列一样,可以使用顺序存储结构实现,也可以使用链式存储结构实现等等。我们只需要简单的修改普通队列的算法就能实现优先级队列,比如在入队的时候,将新元素插入到对应优先级的位置;或者在出队的时候,查找队列中优先级高的先出。对比两种方案,发现使用第一种方案入队时就将结点插入到合适的位置更加方便,由于需要插入,采用链式存储结构将会更加方便。下面我们简单的利用链式存储结构实现优先级队列。
/**
* autour : openXu
* date : 2018/7/31 10:03
* className : PriorityQueue
* version : 1.0
* description : 优先级队列
*
* ———————————————
* front(队首)<<< 高 (优先级) 低 <<< (队尾)rear
* ———————————————
*
*/
public class PriorityQueue<T extends Comparable<T>> extends DLinkList<T> {
private ODER_TYPE oderType = ODER_TYPE.desc; //默认降序优先队列
public enum ODER_TYPE{
desc, //降序
asc, //升序
}
public PriorityQueue(ODER_TYPE oderType) {
this.oderType = oderType;
}
/**入队*/
public synchronized boolean enQueue(T item) {
if(item==null)
throw new NullPointerException("item data is null");
DNode<T> newNode = new DNode<>();
newNode.data = item;
//如果队列为空,或者添加的元素优先级比队尾元素还低,则直接添加到队尾
if(isEmpty() || item.compareTo(last.data) <= 0) {
if (last == null) //空表
first = newNode;
else {
last.next = newNode;
newNode.prior = last;
}
last = newNode;
size++;
return true;
}
DNode<T> p = first;
//查找插入点 , p为从队首开始第一个小于插入值的元素,需要插入到p前面
while (p != null && item.compareTo(p.data) <= 0)
p = p.next;
newNode.next = p;
newNode.prior = p.prior;
if(p.prior==null){ //p为队首结点
first = newNode;
}else{
p.prior.next = newNode;
}
p.prior = newNode;
size++;
return true;
}
/**出队*/
public synchronized T deQueue() {
if(isEmpty())
return null;
return oderType == ODER_TYPE.desc ? remove(0):remove(length()-1);
}
/**返回队首元素,不执行删除操作*/
public T peek() {
return isEmpty()? null:
oderType == ODER_TYPE.desc ? get(0):get(length()-1);
}
@Override
public String toString() {
if(isEmpty())
return "[]";
StringBuffer buffer = new StringBuffer();
buffer.append("[");
DNode mFirst = first;
while(mFirst!=null){
buffer.append(mFirst.data+", ");
mFirst = mFirst.next;
}
return buffer.subSequence(0, buffer.lastIndexOf(", "))+"]";
}
}