版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Lockey23/article/details/81570203
环境准备:
系统:ubuntu 16.10(3 servers)
Virtualization: vmware
Operating System: Ubuntu Zesty Zapus (development branch)
Kernel: Linux 4.8.0-22-generic
Architecture: x86-64
解析配置:
lockey@ubuntu-lockey:~$ cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 ubuntu-lockey
192.168.137.129 master
192.168.137.130 slave1
192.168.137.131 slave2
基本的步骤请参考厦门大学数据库实验室文章:
虽然本人实验版本为Hadoop 2.9.1,但是同一个大版本差别不大,我也是照着上边的博客配出来的
以下主要对部分配置做一下解说:
lockey@ubuntu-lockey:/usr/local/hadoop$ cat etc/hadoop/slaves
#此配置文件主要指定了两个slave的名称(ip对应如上)
slave1
slave2
core-site.xml
#看名字就知道这是核心配置,指明了HDFS的URI以及临时目录,对于临时目录如果没有请创建
<configuration>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
</configuration>hdfs-site.xml
#此配置指明了副本个数,因为是集群,所以当然根据集群中节点个数来配置;还有就是namenode的目录,如果没有也要创建
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/name</value>
</property>
</configuration>
mapred-site.xml(复制mapred-site.xml.template,再修改文件名)
#指明mapreduce中资源调度框架为yarn
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml
#针对资源调度框架的具体配置,包含节点管理以及资源调度
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
按照厦门大学数据库实验室博客进行到底,然后对应上边的配置修改好自己的配置,那么就可以进入你的Hadoop目录然后对namenode进行格式化(初次必须),然后启动你的集群了:
lockey@ubuntu-lockey:/usr/local/hadoop$ pwd
/usr/local/hadoop
lockey@ubuntu-lockey:/usr/local/hadoop$ ./sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-lockey-namenode-ubuntu-lockey.out
slave1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-lockey-datanode-ubuntu-lockey.out
slave2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-lockey-datanode-ubuntu-lockey.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-lockey-secondarynamenode-ubuntu-lockey.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-lockey-resourcemanager-ubuntu-lockey.out
slave1: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-lockey-nodemanager-ubuntu-lockey.out
slave2: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-lockey-nodemanager-ubuntu-lockey.out
lockey@ubuntu-lockey:/usr/local/hadoop$ jps
15462 Jps
15063 SecondaryNameNode
14840 NameNode
15210 ResourceManager
在slave1以及slave2上查看有如下结果(两个slave节点输出类似,都包含了三个服务):
lockey@ubuntu-lockey:~$ jps
6593 DataNode
6874 Jps
6733 NodeManager
然后我们将通过web界面来查看具体的情况:
以下为master上的信息输出,我们可以看到是Actice的,然后也可以看到文件系统的使用情况以及节点的状态,端口50070:
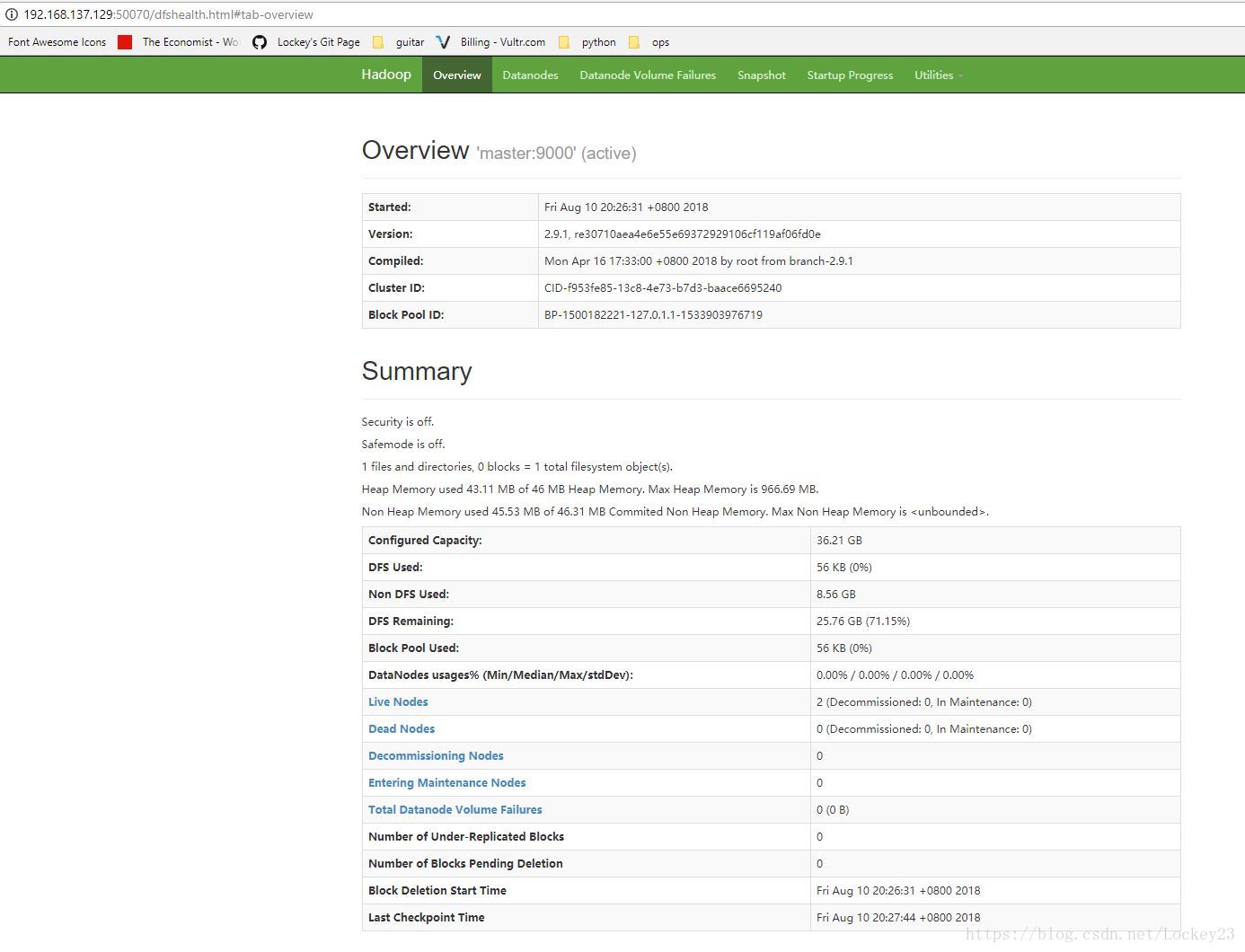
然后再选一个节点看一下情况,端口50075:
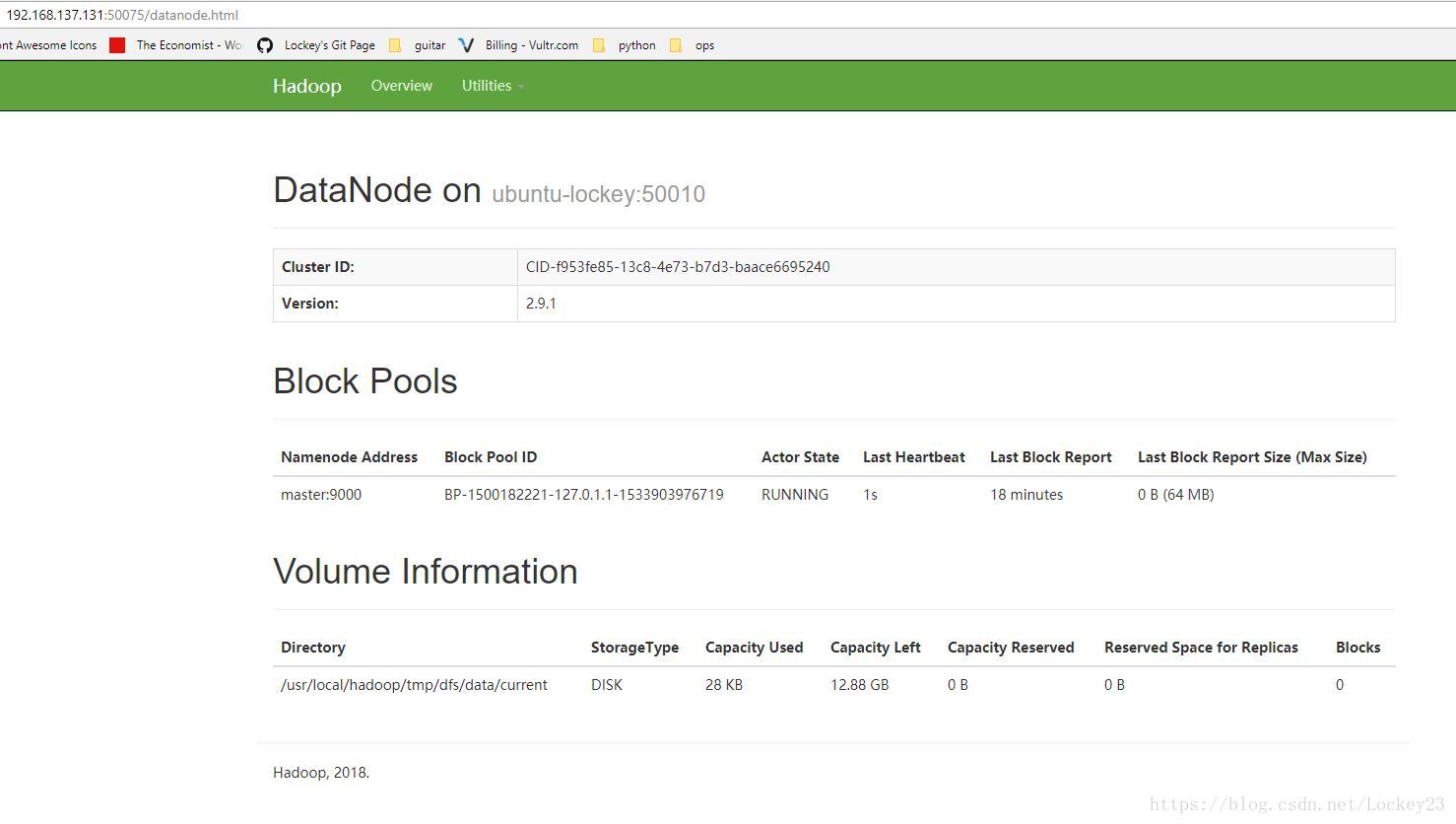
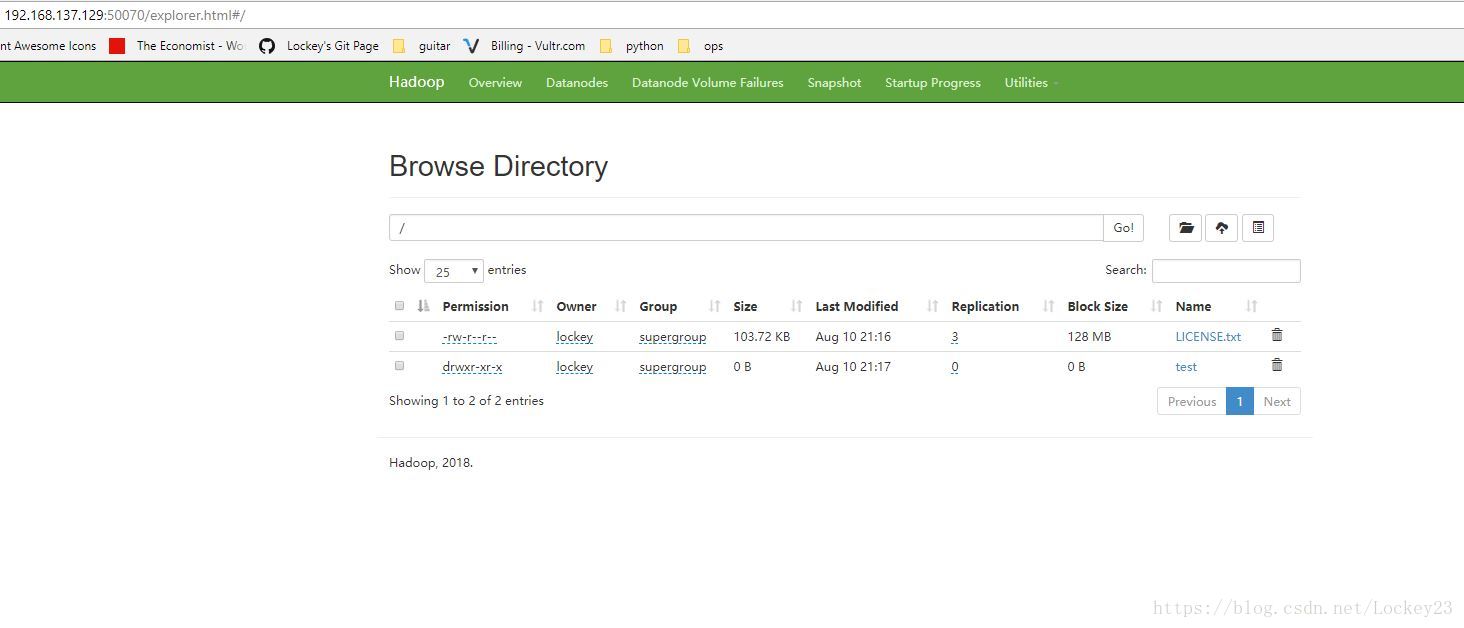
我们往上边存一些文件进去,可以看到副本为3:
lockey@ubuntu-lockey:/usr/local/hadoop$ hadoop fs -put LICENSE.txt /
lockey@ubuntu-lockey:/usr/local/hadoop$ hadoop fs -mkdir /test
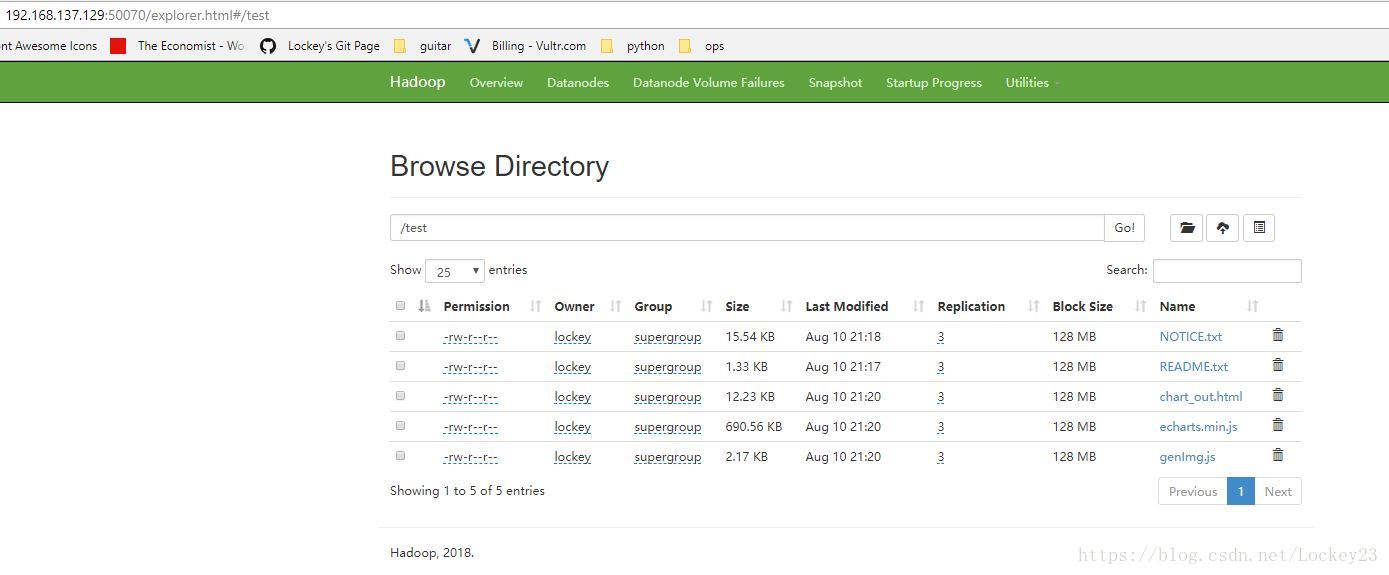
lockey@ubuntu-lockey:/usr/local/hadoop$ hadoop fs -put README.txt /test
lockey@ubuntu-lockey:~$ hadoop fs -put echarts.min.js genImg.js chart_out.html /test
到这里Hadoop小集群环境就搭建完毕了,我们下一篇将整合spark