概述
深度学习也是机器学习的一种,是由前向神经网络或者多层感知机算法演化而来,由于计算资源和可计算数据增加,神经网络的效果逐渐浮现出来,从而迎来了蓬勃发展。本节主要介绍深度学习中基础网络结构前向神经网络(Feedword Netural Network)
FNN基本概念
机器学习都是在学习一种变换,深度学习也不例外,即
FNN理论上能够拟合各种不同类型函数表达。
FNN采取的思路是对输入x进行各种非线性变换,直到达到较好的效果。
例如
基于梯度学习算法
基于梯度的学习算法是机器学习中非常常用的方法,在深度学习中也不例外。比较经典的梯度反向传播算法也是其中的一种,根据以往机器学习的经验,需要解决一下问题。
价值函数
在大多数的情形下,深度学习模型能够学习到
通用的价值函数可以表达为
可以根据不同的概率分布选择模型表示。
输出单元
FNN包括三种比较重要的层次,输入层常常表示为一维向量或者多维向量;中间层也叫隐藏层;输出层。
常见的输出单元有
1. 线性单元,即输出表示为
2. Sigmoid单元:即
3. SoftMax单元:即
4. 其他输出单元
隐藏单元
隐藏层是FNN中非常重要的结构,隐藏单元的选择关乎模型好坏,而且对学习效率影响也非常大。
隐藏层常常表示为:先对输入进行线性变换,然后通过一个激活函数进行非线性变换,其中激活函数的选择决定整个隐藏层。即
修正线性单元(ReLU)
修正线性单元(Rectified Linear Units)的激活函数为
- ReLU的一个最大优势在于计算效率非常高。
- 工程实际中常常将b设置为一个较小的整数,例如0.1
- ReLU的问题在于如果某个实例的激活值为0,则该参数无法通过梯度的方法进行学习,因此有很多变形解决该问题
- ReLU的泛化变形可以为
h=g(z,α)=max(0,zi)+αmin(0,zi),即但激活值为负时,添加负数项 - 绝对值修正(Absolute Value Rectification)将参数
α=−1 - Leaky ReLU将参数设置为0.01
- Pamametric ReLU 将
α 当做参数进行学习。- Maxout Units是更进一步的泛化,将z分成若干个组分别进行最大值操作,
g(zi)=maxj∈G(i)zj
Sigmoid 单元
Sigmoid单元
反正切单元
这两个比较常用的原因在于该单元可以将数值变换到[0,1]或者[-1, 1]但是其计算复杂度较高。
其他隐藏单元
例如
网络架构设计
FNN常见的网络架构设计是线性架构,即每一层的输入都是来自于其父节点,例如
依次类推直到输出。
- 这类结构仅仅需要设计的参数包层数以及每一层的宽度,即隐藏节点的个数
- 根据”统一近似理论“只要要拟合的函数满足一定测度分布,FNN就能表达出来。即FNN能拟合所有的映射,从有限维度到另外一个有效维度。
- “天下没有免费的午餐”,虽然FNN能拟合所有的函数,但不能保证学习算法能够学习到相关参数。
- FNN这种基础的线性结构,后续还会针对特定问题构造不同的网络结构,例如CNN、RNN等
反向传播算法
Back-Propagation反向传播算法是训练FNN最重要的方法,由于映射函数的复杂性,通过梯度学习算法进行求解时,梯度不好计算,因此研究学者提出通过BP算法进行梯度的传播求解。
其主要步骤包括
1)通过前向传播计算网络中各个节点的激活值。
2)将梯度通过反向传播算法进行传播,得到各个参数的梯度值。
3)采用梯度下降法进行模型参数的更新。
4)迭代执行上述步骤,直到收敛。
这是一个非常标准的梯度下降过程,不同的地方在于梯度的计算过程,后面会详细介绍。
可计算图
神经网络可以通过可计算图语言进行表达(Computational Graph Language).
计算图包括以下几个部分节点(可以是标量、向量或者张量)、操作符(加减乘除等各类操作),示例如下:
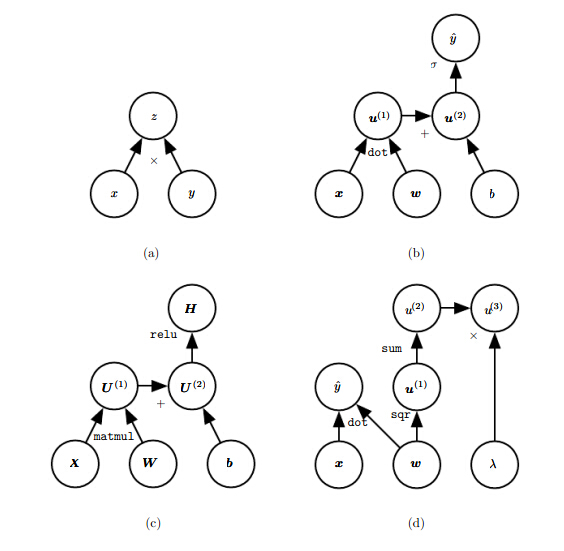
- 图a 表达的是
z=x∗y - 图b 表达的是
y=σ(wx+b) - 图c表达的是
h=g(wx+b) - 图d表达的是
y=wx+λ||w||
微分的链式法则
反向传播算法梯度的计算主要是利用链式法则进行的推导,在微积分中是最基础的知识。
对于标量的嵌套函数的微分常常表示为
对于向量的嵌套函数常常表示为
通过向量的方式进行表达,则可以表示为
对于张量可以展开成一维向量进行求解。
反向传播算法应用于FNN
前向传播过程

反向传播过程

其中前向传播计算各个节点的激活值
反向传播计算各个节点的梯度值
最终的算法还需要一个迭代过程进行串联起来。
符号表示
符号表示是指所有相关的操作都在符号上进行,在未进行赋值前都是抽象表示。
可计算图大概有两种进行BP算法的思路
”符号-数值导数推导“:输入包括一个计算图和输入变量值,返回各个节点的梯度值,代表软件Torch和Caffe
“符号-符号导数推导”:输入包括一个计算图,通过增加额外的节点提供另外的符号表示进行梯度的推导,主要不同在于输出还是一个可计算图,用于计算各个节点的梯度。示例如下:
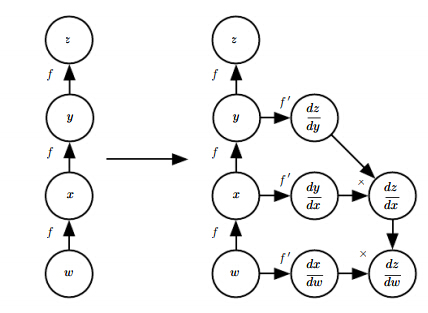
即通过加入额外的节点表达梯度计算过程。
反向传播泛化
理论上任何可计算图只要表示成有向无环图均可以采用BP算法进行求解。
总结
FNN是深度学习中最基础的网络结构,需要着重了解
1. FNN的基础网络结构,标准线性结构
2. 常用隐藏单元和输出单元
3. 模型训练算法-经典的BP算法
4. 了解常见开源实现BP算法的思路
5. 设计自己的网络结构并应用。