注:此爬虫项目及其数据仅作学术学习使用
Prepare
Python 版本
Python 3.6.5
依赖包
scrapy_redis
redis
mysql-python
kafka-python
hdfs
数据API接口
详见Github
Implement
数据依赖关系
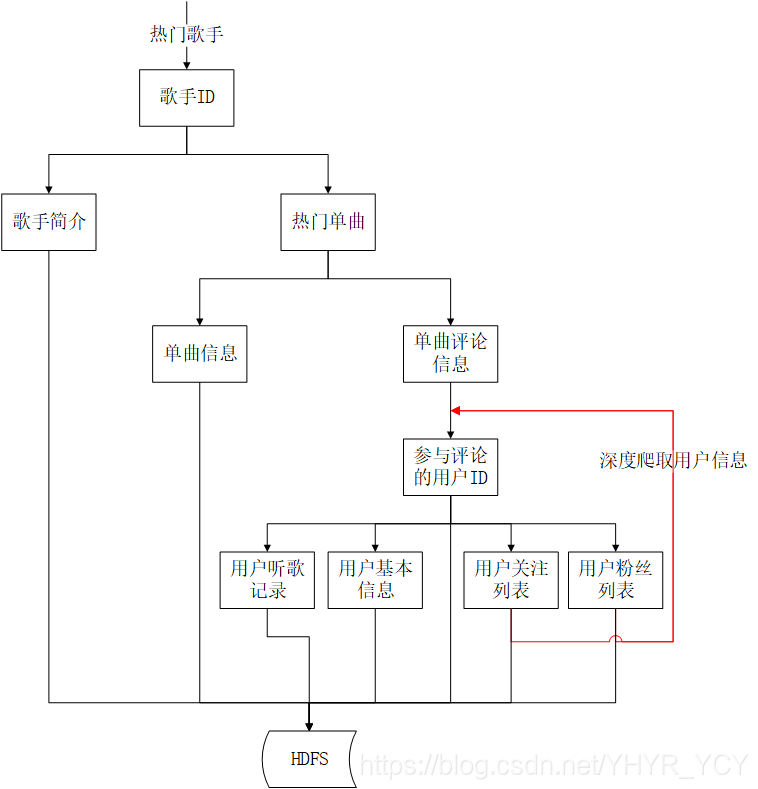
时序
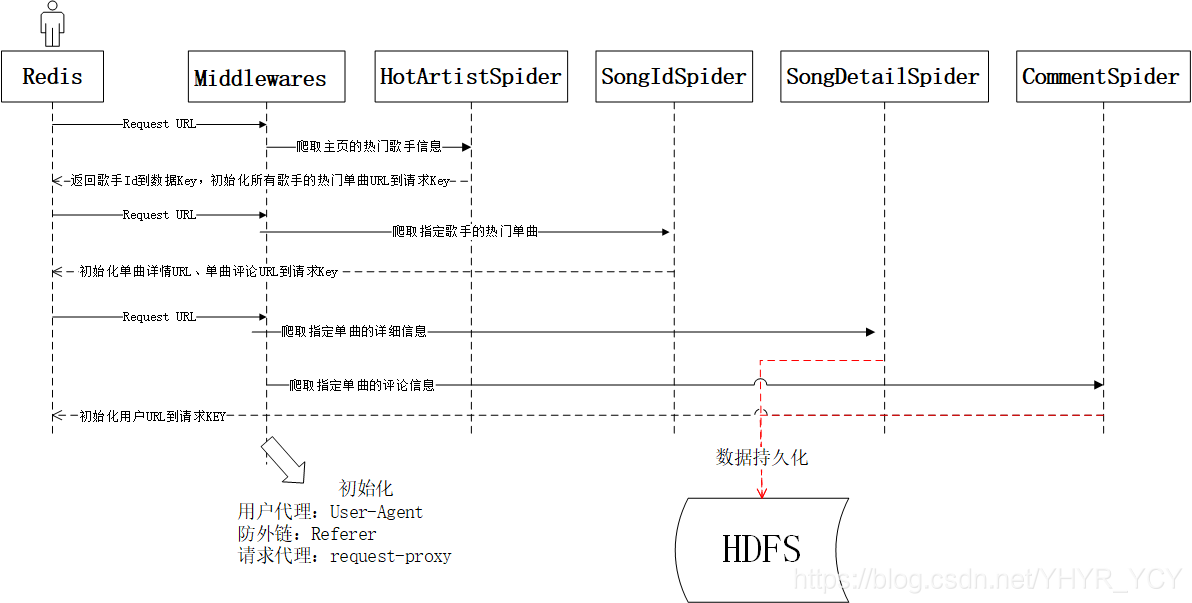
上图详细说明了整个爬虫工程的前一半的数据抽取逻辑;关于用户类数据的抽取在实现逻辑上与上图基本一致。在用户相关数据的爬取上,实现了在尽可能多的爬取用户数据的同时,有效规避重复爬取。实现逻辑如下:
在代码实现层面上,显示的指定用户相关数据的爬取逻辑。优先级为:用户基本信息 > 用户粉丝信息 = 用户关注信息 = 用户听歌记录。即就是只有在爬取到一个用户的基本信息以后,才初始化这个用户的附属信息的URL(例:粉丝列表、关注列表、听歌记录)。这样就可以保证只要爬取用户基本信息时不重复,则附属属性数据的爬取就不会重复。所以在Redis中单独维护一个用户UserId的数据集,每当爬取歌曲的评论数据、用户的粉丝或者关注者数据时,都会先校验当前用户是否在该数据集内;如果不在则初始化用户的基本信息URL到请求队列中,反之则认为该用户已经爬取过。
为了提升用户数据量,在收集歌曲评论中所涉及到的用户信息的同时,深度爬取每个用户所对应的关注和粉丝列表的信息。
数据存储
这里选择将爬取到的数据持久化到HDFS中,便于单机自测;如果想真正的基于多机器实现分布式爬取数据,建议将数据改写到Kafka中;因为HDFS的特性为一次写,多次读;且不支持在统一文件的任意offset进行写操作;因此对于HDFS文件的操作只有append,且不支持并发写操作。如果提升爬虫效率,建议将数据先写入Kafka,然后通过后台脚本通过多线程/多进程进行消费和持久化操作。
Summary
由于我们的数据链路存在一定的依赖关系,但也并非是单线程的地步。所以在具体实现时采用scrapy-redis框架来实现分布式的效果。在请求队列上,可以为每一个Spider在Redis中开辟一个Request队列,这样有效的提升爬取效率。当然要想持续爬取,加代理也是必不可少的。有关免费代理IP的爬取和有效性校验的实现,可详见ProxyIpSpider。
需要注意的是,scrapy-redis不支持在请求队列中实现去重。源码如下所示:
class RedisMixin(object):
"""Mixin class to implement reading urls from a redis queue."""
redis_key = None
redis_batch_size = None
redis_encoding = None
# Redis client placeholder.
server = None
def start_requests(self):
"""Returns a batch of start requests from redis."""
return self.next_requests()
def setup_redis(self, crawler=None):
"""Setup redis connection and idle signal.
This should be called after the spider has set its crawler object.
"""
if self.server is not None:
return
if crawler is None:
# We allow optional crawler argument to keep backwards
# compatibility.
# XXX: Raise a deprecation warning.
crawler = getattr(self, 'crawler', None)
if crawler is None:
raise ValueError("crawler is required")
settings = crawler.settings
if self.redis_key is None:
self.redis_key = settings.get(
'REDIS_START_URLS_KEY', defaults.START_URLS_KEY,
)
self.redis_key = self.redis_key % {'name': self.name}
if not self.redis_key.strip():
raise ValueError("redis_key must not be empty")
if self.redis_batch_size is None:
# TODO: Deprecate this setting (REDIS_START_URLS_BATCH_SIZE).
self.redis_batch_size = settings.getint(
'REDIS_START_URLS_BATCH_SIZE',
settings.getint('CONCURRENT_REQUESTS'),
)
try:
self.redis_batch_size = int(self.redis_batch_size)
except (TypeError, ValueError):
raise ValueError("redis_batch_size must be an integer")
if self.redis_encoding is None:
self.redis_encoding = settings.get('REDIS_ENCODING', defaults.REDIS_ENCODING)
self.logger.info("Reading start URLs from redis key '%(redis_key)s' "
"(batch size: %(redis_batch_size)s, encoding: %(redis_encoding)s",
self.__dict__)
self.server = connection.from_settings(crawler.settings)
# The idle signal is called when the spider has no requests left,
# that's when we will schedule new requests from redis queue
crawler.signals.connect(self.spider_idle, signal=signals.spider_idle)
def next_requests(self):
"""Returns a request to be scheduled or none."""
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
fetch_one = self.server.spop if use_set else self.server.lpop
# XXX: Do we need to use a timeout here?
found = 0
# TODO: Use redis pipeline execution.
while found < self.redis_batch_size:
data = fetch_one(self.redis_key)
if not data:
# Queue empty.
break
req = self.make_request_from_data(data)
if req:
yield req
found += 1
else:
self.logger.debug("Request not made from data: %r", data)
if found:
self.logger.debug("Read %s requests from '%s'", found, self.redis_key)
def make_request_from_data(self, data):
"""Returns a Request instance from data coming from Redis.
By default, ``data`` is an encoded URL. You can override this method to
provide your own message decoding.
Parameters
----------
data : bytes
Message from redis.
"""
url = bytes_to_str(data, self.redis_encoding)
return self.make_requests_from_url(url)
def schedule_next_requests(self):
"""Schedules a request if available"""
# TODO: While there is capacity, schedule a batch of redis requests.
for req in self.next_requests():
self.crawler.engine.crawl(req, spider=self)
def spider_idle(self):
"""Schedules a request if available, otherwise waits."""
# XXX: Handle a sentinel to close the spider.
self.schedule_next_requests()
raise DontCloseSpider
class RedisCrawlSpider(RedisMixin, CrawlSpider):
"""Spider that reads urls from redis queue when idle.
Attributes
----------
redis_key : str (default: REDIS_START_URLS_KEY)
Redis key where to fetch start URLs from..
redis_batch_size : int (default: CONCURRENT_REQUESTS)
Number of messages to fetch from redis on each attempt.
redis_encoding : str (default: REDIS_ENCODING)
Encoding to use when decoding messages from redis queue.
Settings
--------
REDIS_START_URLS_KEY : str (default: "<spider.name>:start_urls")
Default Redis key where to fetch start URLs from..
REDIS_START_URLS_BATCH_SIZE : int (deprecated by CONCURRENT_REQUESTS)
Default number of messages to fetch from redis on each attempt.
REDIS_START_URLS_AS_SET : bool (default: True)
Use SET operations to retrieve messages from the redis queue.
REDIS_ENCODING : str (default: "utf-8")
Default encoding to use when decoding messages from redis queue.
"""
@classmethod
def from_crawler(self, crawler, *args, **kwargs):
obj = super(RedisCrawlSpider, self).from_crawler(crawler, *args, **kwargs)
obj.setup_redis(crawler)
return obj
当启动一个Spider后,就会读取Redis中指定key下的url信息。如果当前key下没有相应的value就等待;当有值时,则会调用next_requests方法来获取数据;查看方法next_requests的源码不难看出,无论你当前的key的数据类型是什么,最终都会pop掉,从而导致Redis中不在有这个值。这也就是上述中提到的为什么要自己通过维护userId数据集来实现抽取的唯一性,而不是用这个请求队列作为唯一性校验的原因。对于一个正常的设计,应该是在项目运行一段时间后会出现所有的Spider都处于挂起等待的状态,此时所涉及到的所有请求队列应该均为空;否则就有可能因为设计问题导致无限死循环,从而出现永不休止的爬取相同数据。
Scrapy-Redis自带的去重功能目前还未研究,效果如何暂不做评论;不过网上有很多关于修改源码通过实现去重逻辑,有兴趣的可查阅有关BloomFilter相关的资料。
答谢
感谢sqaiyan在数据API上给予的灵感
感谢LiuXingMing在分布式爬虫实现上给予的灵感
项目源码详见个人Github,欢迎Start、Issue