虽然我们搭建了一个主从架构,但是每个Redis都要保存相同的数据,这样容易造成水桶效应.而且主从架构频繁TCP连接断开也可能会对服务器和网络带来很大负担。
如果我们使用的是java客户端jedis中的ShardedJedisPool话,那么我们在增加新的Redis服务器之后,我们以前保存在其他Redis服务器上面的数据就有可能访问不到.(因为ShardedJedisPool它是采用hash算法来分布Redis的Key,当我们增加Redis服务器之后,整个hash计算出来的结果已经是不一样了.)
Redis 3.0版本最大的更新就是支持集群,那么接下来我们一起开始搭建Redis集群吧.
预热(Redis cluster架构)
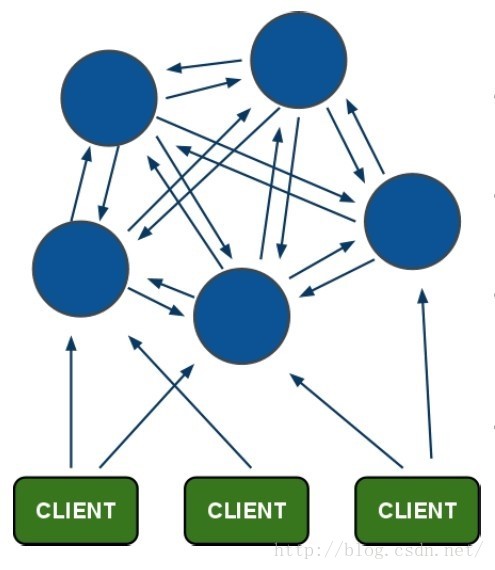
新特性:
① 节点自动发现
② slave->master 选举,集群容错

③ Hot resharding:在线分片
④ 进群管理:clusterxxx
⑤ 基于配置(nodes-port.conf)的集群管理
⑥ ASK转向/MOVED 转向机制.
架构细节:
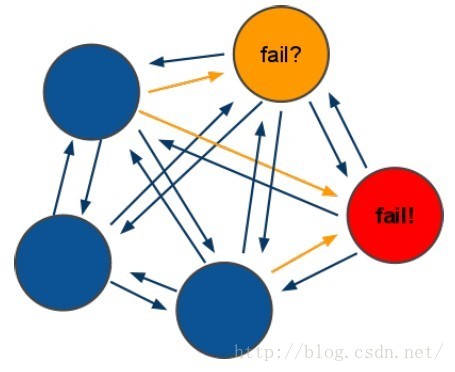
领着选举过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster-node-timeout),认为当前master节点挂掉.
② 什么时候整个集群不可用(cluster_state:fail),当集群不可用时,所有对集群的操作做都不可用,收到((error)CLUSTERDOWN The cluster is down)错误
a: 如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成进群的slot映射[0-16383]不完成时进入fail状态.
b: 如果进群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
准备环境
搭建
首先使用 前面准备的3个Redis配置文件来搭建一个集群
修改每个配置文件
开启集群 cluster-enabledyes
指定集群文件 cluster-config-file nodes-(port).conf
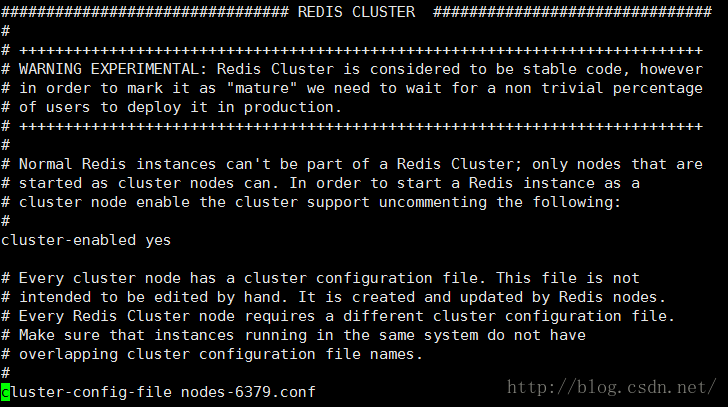


nodes-6379.conf 不需要我们去维护,Redis 会主动去维护该文件
因为3个都是master节点所以需要关闭 slaveof 参数
启动Redis
redis-server /etc/redis.6379.conf
redis-server /etc/redis.6380.conf
redis-server /etc/redis.6381.conf
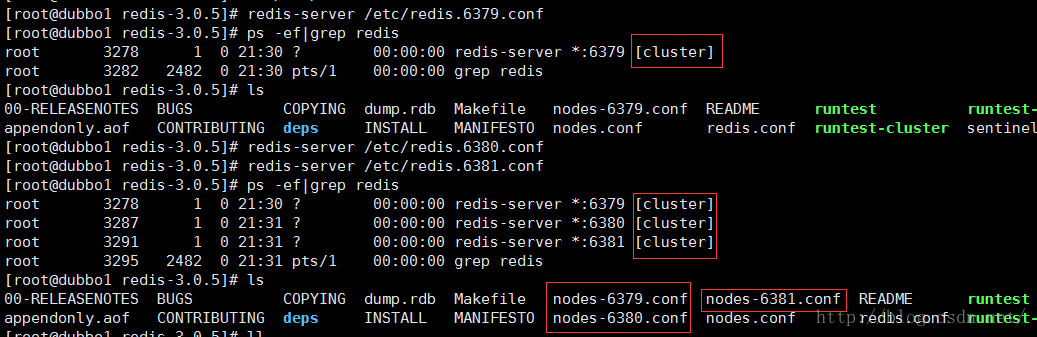
上面只是单独的启动了3个Redis实例,下面我们开始创建集群
集群的创建我们需要一个redis-trib.rb脚本,所以我们需要一个ruby的环境
yum -y install zlib ruby rubygems
gem install redis
进入Redis的安装包目录下面的src
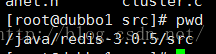
执行命令
./redis-trib.rb create --replicas 0 192.168.247.101:6379 192.168.247.101:6380 192.168.247.101:6381--replicas 0 表示指定从库的数量
注意:这里不要使用127.0.0.1 不然使用jedis的时候会无法连接
其中Redis实例不能有数据,因为集群之后,每个数据都是根据插槽(slots)来计算的
不然会报
[ERR] Node 192.168.247.101:6379 is not empty.Either the node already knows other nodes (check with CLUSTER NODES) or containssome key in database 0.
因为Redis集群之后每次设置值的时候都要先计算key的值获取该key 的插槽值,然后在设置到集群中对应插槽值的Redis实例中
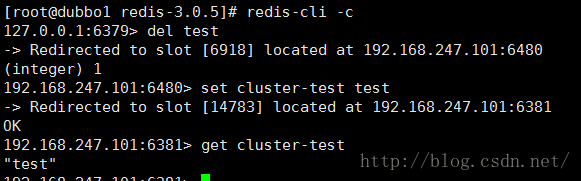
我们用Redis客户端连接试试
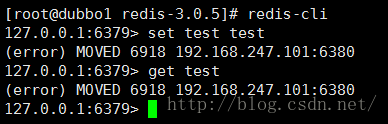
如果没有换一个key试试
在set 和 get 的时候都报错
(error) MOVED 6918192.168.247.101:6380
表示 test的插槽值是6918 , 我们查看上面的集群信息可以看到 6918在6380这个实例上(提示也是这么说的)那么我们用6380连接试试
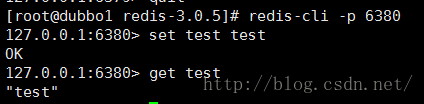
Oh~~~~ 这个时候设置成功了! ╮(╯▽╰)╭
难道我们每次在set的时候都要重新打开一个Redis客户端去吗?
呦呦, redis-cli 提供了一个参数–c
redis-cli -c指定了这个参数之后,redis-cli会根据插槽值做一个重定向,连接到指定的redis实例上面
试试吧 come on
我们获取下刚刚在6380中插入的一个key

你看 我们从6379重定向了6380, 并且获取到了 test 的值
综上所述
Redis集群的数据是根据插槽值来设置进具体的节点中的.但是如果这个key的插槽值不是在当前redis实例的话,他就需要进行重定向.这样一次操作就变成了2次......
好吧这个就是Redis3.0里面所说的ASK 转向/MOVED 转向机制 ……
个人认为这样子本来一次获取的结果就变成大部分情况下2次操作才能获取,还加了一次重定向, 这样有点不好吧.
我们还是接下去讲吧
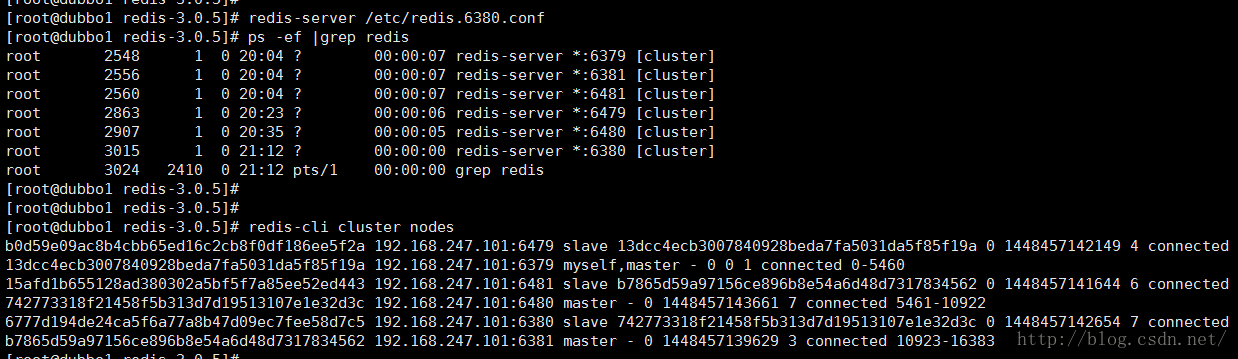
通过 cluster nodes 命令可以查看集群信息

当我们在执行 set test test 的命令时,Redis 的执行步骤:
① 接受命令 set test test
② 通过key (test) 计算出 插槽值,然后根据插槽值 找到对应的节点
③ 重定向到该节点,执行命令
整个Redis提供了16384个插槽,也就是说集群中的每个节点分得的插槽数总和为16384。
redis-trib.rb脚本实现了是将16384个插槽平均分配给了N个节点。
那么 如果有一部分插槽数没有指定, 那这不分插槽数对应的key就不能使用了
插槽数是怎么计算的呢???
key的有效部分使用CRC16算法计算出哈希值,再将哈希值对16384取余,得到插槽值。有效部分:
如果key里面包含了一对{},并且{}里面是有值的,那么有效部分就是{}里面的那些东东
For Example è key_{test} 有效部分就是 test
节点的新增和删除
我们再来一个配置文件6382
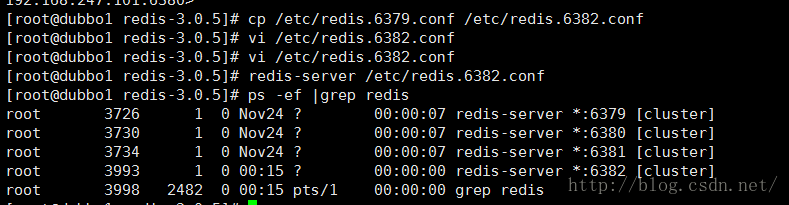
这个时候6382是没有加入集群的

我们通过redis-trib.rb脚本来添加
./redis-trib.rb add-node 192.168.247.101:6382 192.168.247.101:6379表示将新加入的6382节点添加至6379这个集群中来
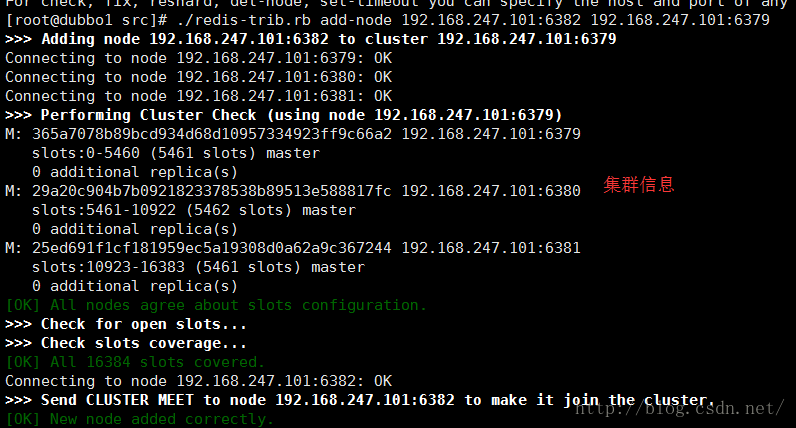
添加成功
查看下集群信息

虽然6382已经添加进集群了但是6382没有分配的插槽值,这个时候他好像没有什么卵用,所以接下来就要给他分配插槽值了
通过命令重新分配插槽数
./redis-trib.rb reshard 192.168.247.101:6382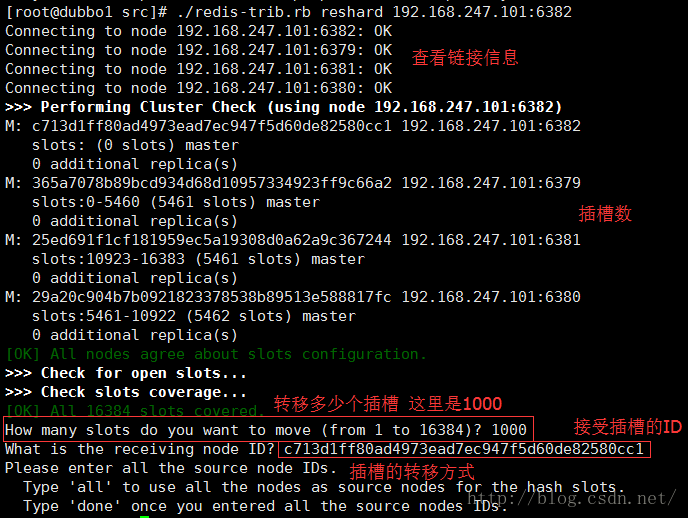
插槽的转移方式:
all : 从其他每个拥有插槽节点中随机抽取几个到 接收插槽的节点
done : 从指定id的节点中转移插槽到 接收插槽的节点 可以使多个,以done结束
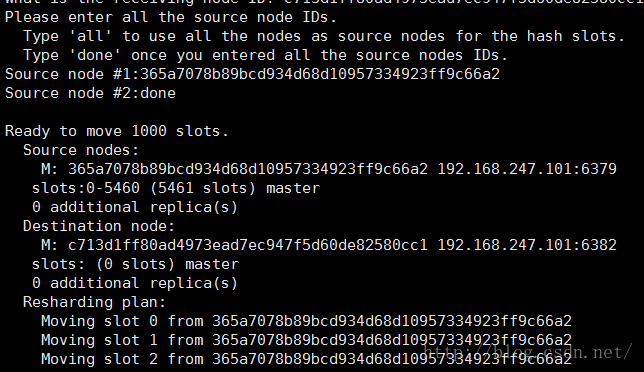
最后输入yes确定
OK 到了这里节点已经新增成功了. look look

节点增加成功.
这个插槽数还是很重要的嘛
下面开始删除刚刚添加上来的6382节点
如果删除节点的话, 我们要先把6382节点上面的插槽数给转移到别的节点上面,然后在通过redis-trib.rb脚本来删除节点,不然这个插槽数就没有咯,而对应的key也失效.
开始转移插槽数
./redis-trib.rb reshard 192.168.247.101:6382就是刚刚新增节点分配插槽数数一样的 O.o 只是相反了一下
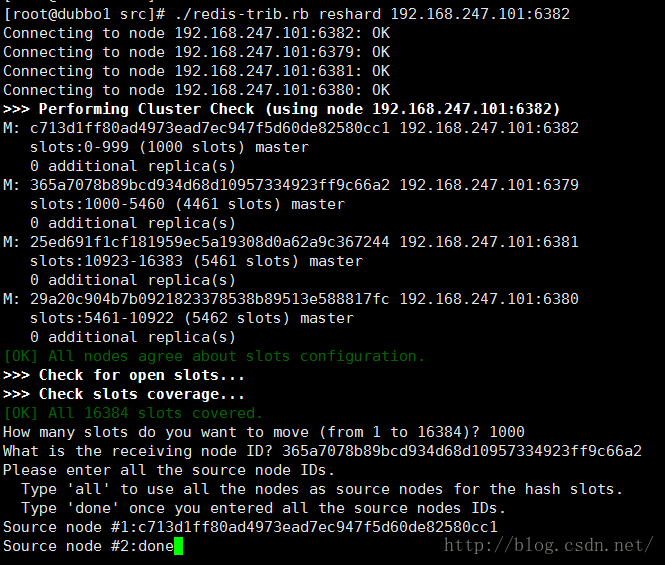
然后就可以开始删除了
./redis-trib.rb del-node 192.168.247.101:6382 c713d1ff80ad4973ead7ec947f5d60de82580cc1最后面那个是6382在集群中的ID
OK 节点已经删除成功
高可用集群
我们用3个master节点创建了一个集群,但是如果我们其中的一个master宕机了,那么他对应插槽值的key全部都会失效,集群就不可用.Redis集群为我们提供了故障机制
故障机制:
① 集群中的每个节点都会定期的向其它节点发送PING命令,并且通过有没有收到回复判断目标节点是否下线
② 集群中每一秒就会随机选择几个节点,然后选择其中最久没有响应的节点放PING命令
③ 如果一定时间内目标节点都没有响应,那么该节点就认为目标节点疑似下线
④ 当集群中的节点超过半数认为该目标节点疑似下线,那么该节点就会被标记为下线
⑤ 当集群中的任何一个节点下线,就会导致插槽区有空档,不完整,那么该集群将不可用
⑥ 如果该下线的节点使用了主从模式,那么该节点(master)宕机后,集群会将该节点的从库(slave)提升为(master)继续完成集群服务.
该节点是一个高可用的节点哦!!!
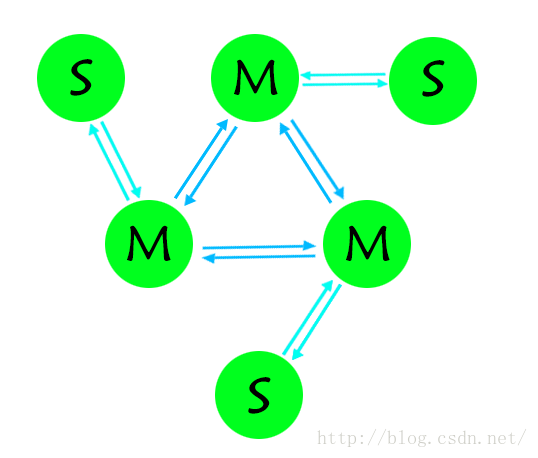
创建主从集群
复制3个配置文件

修改成各自的port
接下来我们就可以操刀啦
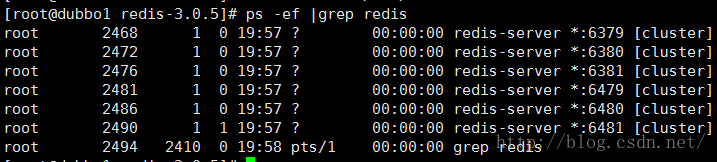
启动6个Redis实例
开始创建集群,指定从库数量1
./redis-trib.rb create --replicas 1 192.168.247.101:6379 192.168.247.101:6380 192.168.247.101:6381 192.168.247.101:6479 192.168.247.101:6480 192.168.247.101:6481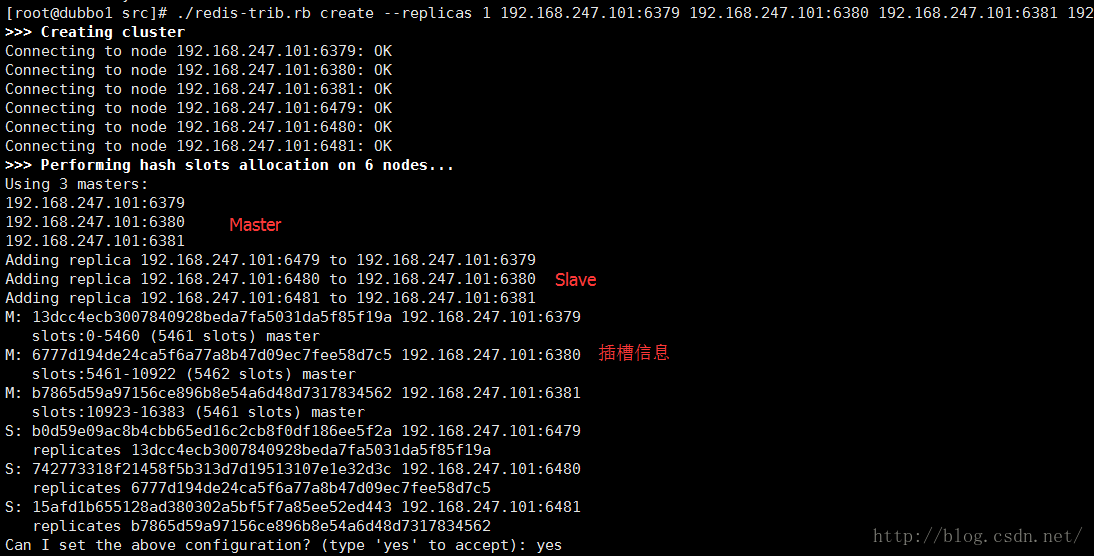
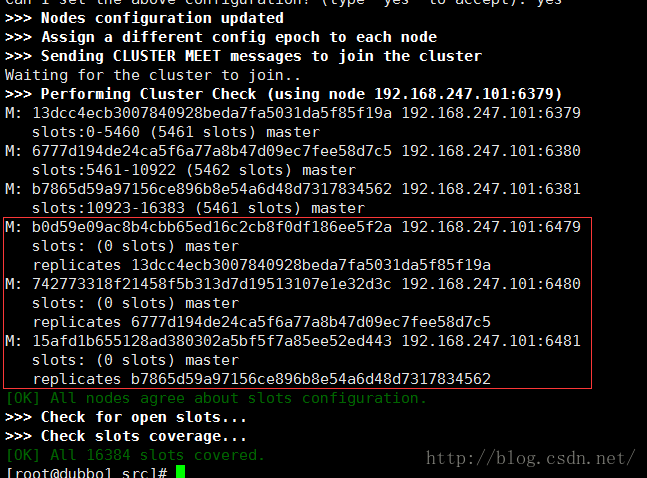
啦啦啦 启动成功了.
(因为上次是直接关机的,没有一个一个删除节点,所以启动的时候报错了,我吧那个node-[port].conf的文件全部删除了就OK了)
这个是集群的信息

下面看下他的故障性能是咋样的
来个普通的get set 试试
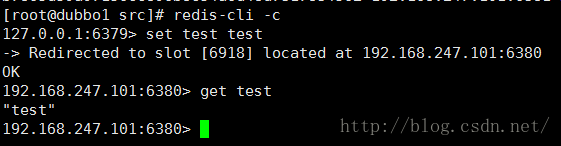
不错一切都是OK的
这个key设置到了6380上面,那么我们看下6380的Slave(6480) 有没有数据
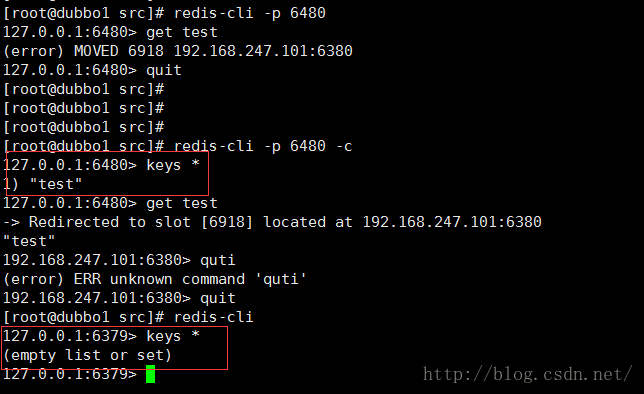
我不清楚他发生了什么,他明明是有这个key的,但是获取的时候却需要重定向,真是够了.
只能知道他有key,却获取不到数据,只能重定向到6380上面获取……
先把这个Slave干掉,看下对集群有没有影响
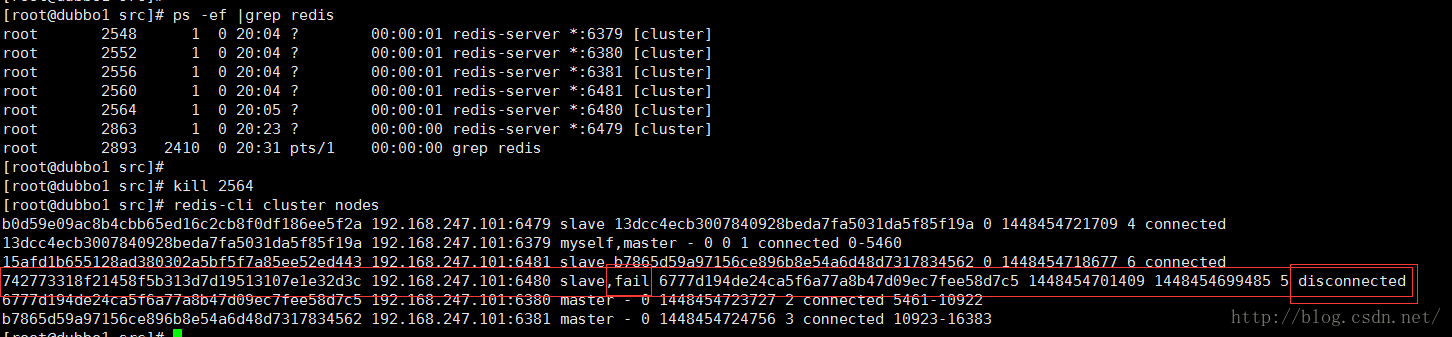
干掉之后 ,提示这个节点已经不能用了
试试看集群现在的使用情况
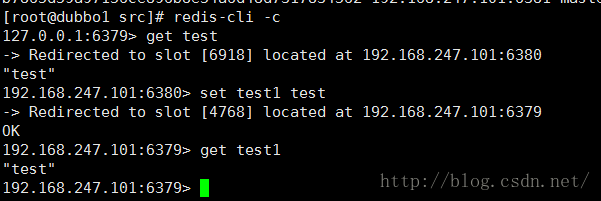
还是能在那里愉快的蹦跶的,一个master的slave挂掉对它真是一点影响都没有
恢复6480节点,看下6480的恢复情况
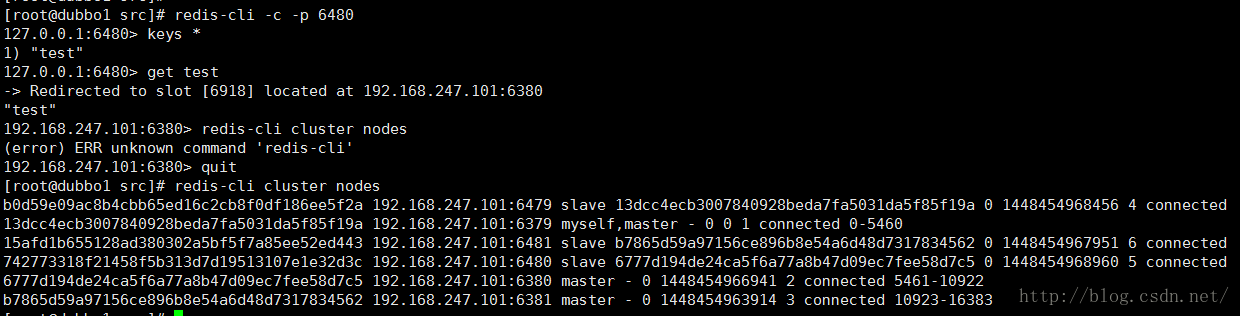
恢复情况良好,并且集群信息提示也是连接状态
使用必杀技干掉6480的老大试试
干掉之后要等他们讨论一会 slave才会顶上变成master

slave 6480已经变身成master了,并且插槽数也已经转移
看了下集群还是杠杠滴,而且6380上面的数据都已经到6480上面了
重新连接之后,6380已经变成slave ,恢复不过来了
注意哦:
① 多键的命令操作(如MGET、MSET),如果每个键都位于同一个节点,则可以正常支持,否则会提示错误
② 集群中的节点只能使用0号数据库,如果执行SELECT切换数据库会提示错误