Java语言的特点
- 简单:java语言不使用指针,而是引用,并提供废料收集,让程序员不必为内存管理而担忧
- 面向对象:java只支持类的单继承、接口之间的多继承、类与接口之间的实现机制(关键字为implements)
- 健壮:强类型转换、异常处理、垃圾回收机制都是java程序健壮型的保障
- 可移植:java系统本身具有很强的可移植性,java编译器是用Java实现的,java的运行环境是用ANSI C实现的
- 多线程:java线程创建通常有两种方式,一种是继承Thread,一种是实现Runnable
变量类型
- 成员变量:在类中,方法体之外定义的变量,存在堆内存中
- 局部变量:在方法、构造方法、语句块定义的变量,存在栈内存中
- 静态变量(类变量):在类中,方法体之外定义的变量,但必须由static关键字修饰,存在静态存储区(方法区)
基本数据类型
- 四种数字类型:byte(1个字节)、short(2个字节)、int(4个字节)、long(8个字节)
- 两种浮点型:float(4个字节)、double(8个字节)
- 一种布尔型:boolean(false和true)
- 一种字符型:char(2个字节)
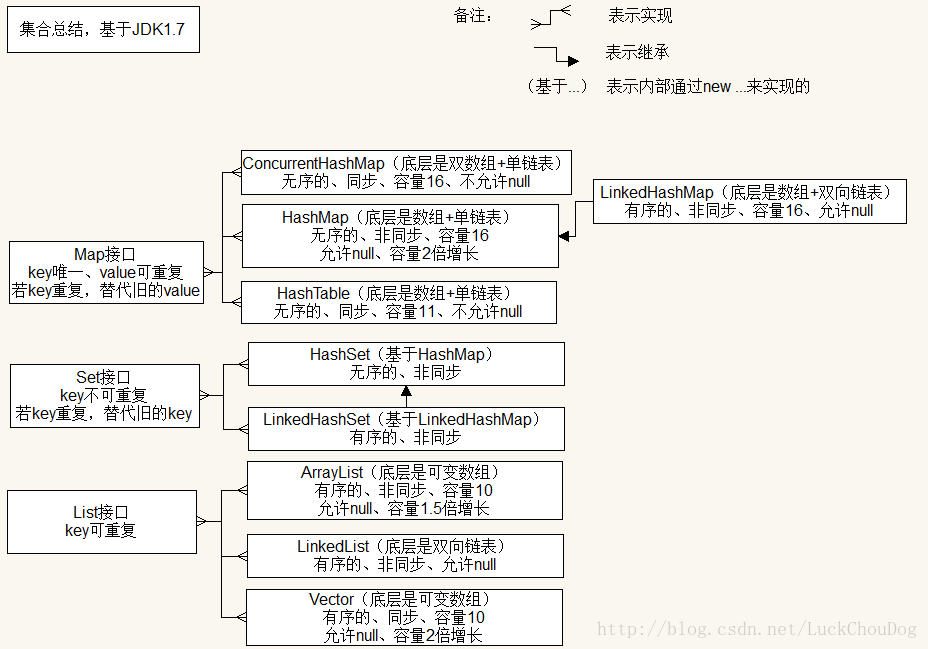
集合
- Collection接口:提供子类接口继承,List和Set继承自Collection接口
- List接口:有序、key和value可重复,可以动态增长,查找效率高、插入删除效率低。(实现类:ArrayList、LinkedList、Vector)
- Set接口:无序、key和value不可重复,查找效率慢、插入删除效率高。(实现类:HashSet、TreeSet)
- Map接口:无序、key唯一、value可重复。(实现类:HashMap、TreeMap、Hashtable)
- 注意:TreeSet和TreeMap都是有序的
Java的四个基本特性
- 抽象:把现实生活某一类东西提取出来,成为该类东西的共有特性。抽象一般分为数据抽象和过程抽象,数据抽象是对象的属性,过程抽象是对象的行为特征
- 封装:把客观事物进行封装成抽象类,该类的数据和方法只让可信的类操作,对不可信的类隐藏。封装分为属性的封装和方法的封装
- 继承:从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力
- 多态:同一个行为具有多个不同表现形式或形态的能力,多态的前提是类与类之间必须存在关系,要么继承,要么实现
String和StringBuffer、StringBuilder的区别
- 可变性
String类是用字符数组保存字符串,即private final char value[],所以String对象不可变
StringBuffer类与StringBuilder类都是继承AbstractStringBuilder类,AbstractStringBuilder是用字符数组保存字符串,即char value[],所以StringBuffer与StringBuilder对象是可变的 - 线程安全性
String类对象不可变,所以理解为常量,线程安全
StringBuffer类对方法加了同步锁,线程安全
StringBuilder类对方法未加同步锁,线程不安全 - 性能
String类进行改变的时候,都会产生新的String对象,然后将指针指向新的String对象
StringBuffer进行改变的时候,都会复用自身对象,性能比String高
StringBuilder行改变的时候,都会复用自身对象,相比StringBuffer能获得10%~15%左右的性能提升,但是得承担多线程的不安全的风险
hashCode和equals方法的关系
equals相等,hashCode必相等;hashCode相等,equals不一定相等
你了解重新调整HashMap大小存在什么问题吗?
当多线程的情况下,可能产生条件竞争。当重新调整HashMap大小的时候,确实存在条件竞争,如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的数组位置的时候,HashMap并不会将元素放在LinkedList的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了
HashMap与HashSet的区别
| HashMap | HashSet |
|---|---|
| HashMap实现了Map接口 | HashSet实现了Set接口 |
| HashMap储存键值对 | HashSet仅仅存储对象 |
| 使用put()方法将元素放入map中 | 使用add()方法将元素放入set中 |
| HashMap中使用键对象来计算hashcode值 | HashSet使用成员对象来计算hashcode值 |
| HashMap比较快,因为是使用唯一的键来获取对象 | HashSet较HashMap来说比较慢 |
Hashtable与HashMap的区别
| Hashtable | HashMap |
|---|---|
| 方法是同步的 | 方法是非同步的 |
| 基于Dictionary类 | 基于AbstractMap,而AbstractMap基于Map接口的实现 |
| key和value都不允许为null,遇到null,直接返回 NullPointerException | key和value都允许为null,遇到key为null的时候,调用 putForNullKey方法进行处理,而对value没有处理 |
| hash数组默认大小是11,扩充方式是old*2+1 | hash数组的默认大小是16,而且一定是2的指数 |
LinkedHashMap与HashMap的区别
| LinkedHashMap | HashMap |
|---|---|
| 有序的,有插入顺序和访问顺序 | 无序的 |
| 内部维护着一个运行于所有条目的双向链表 | 内部维护着一个单链表 |
TreeMap和HashMap的区别
| TreeMap | HashMap |
|---|---|
| 有序的 | 无序的 |
| 不允许null | 允许null |
| 实现Comparable接口 | 不实现Comparable接口 |
| 底层是红黑二叉树,线程不同步 | 底层是哈希表,线程不同步 |
TreeSet和HashSet的区别
| TreeSet | HashSet |
|---|---|
| 有序的 | 无序的 |
| 不允许null | 允许null |
| 底层是红黑二叉树,线程不同步 | 底层是哈希表,线程不同步 |
| TreeSet是通过TreeMap实现的,用的只是Map的key | HashSet是通过HashMap实现的,用的只是Map的key |
Error和Exception区别
Error类和Exception类的父类都是throwable类
- Error:一般指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢等。对于这类错误导致的应用程序中断,仅靠程序本身无法恢复和和预防,遇到这样的错误,建议让程序终止
- Exception:表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常
Unchecked Exception和Checked Exception区别
- Unchecked Exception
- 指的是不可被控制的异常,或称运行时异常,主要体现在程序的瑕疵或逻辑错误,并且在运行时无法恢复
- 包括Error与RuntimeException及其子类,如:OutOfMemoryError,IllegalArgumentException, NullPointerException,IllegalStateException,IndexOutOfBoundsException等
- 语法上不需要声明抛出异常也可以编译通过
- Checked Exception
- 指的是可被控制的异常,或称非运行时异常
- 除了Error和RuntimeException及其子类之外,如:ClassNotFoundException, NamingException, ServletException, SQLException, IOException等
- 需要try catch处理或throws声明抛出异常
Synchronized和Lock的区别
- 相同点:
Lock能完成Synchronized所实现的所有功能 - 不同点:
Synchronized是基于JVM的同步锁,JVM会帮我们自动释放锁。Lock是通过代码实现的,Lock要求我们手工释放,必须在finally语句中释放。
Lock锁的范围有局限性、块范围。Synchronized可以锁块、对象、类
Lock功能比Synchronized强大,可以通过tryLock方法在非阻塞线程的情况下拿到锁
进程和线程的区别
- 地址空间和其他资源:进程间相互独立,进程中包括多个线程,线程间共享进程资源,某进程内的线程在其他进程内不可见
- 通信:进程间通信通过IPC机制,线程间通信通过数据段(如:全局变量)的读写,需要进程同步和互斥手段的辅助,以保证数据的一致性
- 调度和切换:进程是资源分配单位,线程是cpu调度单位,跟cpu真正打交道的是线程,线程上下文切换比进程上下文切换要快得多
内存溢出和内存泄漏的区别
- 内存溢出:指程序在申请内存时,没有足够的空间供其使用
- 内存泄漏:指程序分配出去的内存不再使用,无法进行回收
xml解析方式
- Dom解析:将XML文件的所有内容读取到内存中(内存的消耗比较大),然后允许您使用DOM API遍历XML树、检索所需的数据
- Sax解析:Sax是一个解析速度快并且占用内存少的xml解析器,Sax解析XML文件采用的是事件驱动,它并不需要解析完整个文档,而是按内容顺序解析文档的过程
- Pull解析:Pull解析器的运行方式与 Sax 解析器相似。它提供了类似的事件,可以使用一个switch对感兴趣的事件进行处理
GC简述
当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。通常,GC采用有向图的方式记录和管理堆(heap)中的所有对象,通过这种方式确定哪些对象是”可达的”,哪些对象是”不可达的”。当GC确定一些对象为”不可达”时,GC就有责任回收这些内存空间。但是,为了保证 GC能够在不同平台实现的问题,Java规范对GC的很多行为都没有进行严格的规定
静态代码块、构造代码块、构造方法的执行顺序
- 父静态代码块
- 子静态代码块
- 父代码块
- 父构造函数
- 子代码块
- 子构造函数
网络请求之Get和Post的区别
- 传递方式:Get通过地址栏传输,Post通过报文传输
- 传递长度:Get提交数据最多1024字节,Post则没有限制
- 传递用途:Get是从服务器中获取数据,Post是向服务器发送数据
TCP和UDP的区别
| TCP | UDP |
|---|---|
| 面向连接,需要三次握手进行连接 | 面向非连接 |
| 传输可靠,采用字节流传输 | 传输不可靠,采用报文传输 |
| 能传输大量的数据 | 能传输少量数据 |
| 传输速度慢 | 传输速度快 |
| 连接方式有点对点连接 | 连接方式有一对一,一对多,多对多 |
| 提供超时重发,丢弃重复数据,流量控制等功能 | 没有超时重发等机制 |
HTTP和HTTPS的区别
| HTTP | HTTPS |
|---|---|
| URL以http://开头 | URL以https://开头 |
| 不安全的 | 安全的 |
| 默认端口是80 | 默认端口是443 |
| 工作于OSI模型中的应用层 | 工作于OSI模型中的传输层 |
| 传输的数据无需加密 | 传输的数据进行加密 |
| 传输速度快 | 传输速度慢 |
| 访问无需证书 | 访问需要认证证书 |
分析事件传递
- dispatchTouchEvent(分发事件)
return true:表示该View内部消化掉了所有事件
return false:表示事件在本层不再继续进行分发,并交由上层控件的onTouchEvent方法进行消费
return super.dispatchTouchEvent(ev):默认事件将分发给本层的事件拦截onInterceptTouchEvent 方法进行处理 - onInterceptTouchEvent(拦截事件)
return true:表示将事件进行拦截,并将拦截到的事件交由本层控件 的 onTouchEvent 进行处理
return false:表示不对事件进行拦截,事件得以成功分发到子View
return super.onInterceptTouchEvent(ev):默认表示不拦截该事件,并将事件传递给下一层View的dispatchTouchEvent - onTouchEvent(消费事件)
return true:表示onTouchEvent处理完事件后消费了此次事件
return fasle:表示不响应事件,那么该事件将会不断向上层View的onTouchEvent方法传递,直到某个View的onTouchEvent方法返回true
return super.dispatchTouchEvent(ev):表示不响应事件,结果与return false一样
简要的谈谈Android的事件分发机制?
当点击事件发生时,首先Activity将TouchEvent传递给Window,再从Window传递给顶层View。TouchEvent会最先到达最顶层 view 的 dispatchTouchEvent ,然后由 dispatchTouchEvent 方法进行分发,如果dispatchTouchEvent返回true ,则交给这个view的onTouchEvent处理,如果dispatchTouchEvent返回 false ,则交给这个 view 的 interceptTouchEvent 方法来决定是否要拦截这个事件,如果 interceptTouchEvent 返回 true ,也就是拦截掉了,则交给它的 onTouchEvent 来处理,如果 interceptTouchEvent 返回 false ,那么就传递给子 view ,由子 view 的 dispatchTouchEvent 再来开始这个事件的分发。如果事件传递到某一层的子 view 的 onTouchEvent 上了,这个方法返回了 false ,那么这个事件会从这个 view 往上传递,都是 onTouchEvent 来接收。而如果传递到最上面的 onTouchEvent 也返回 false 的话,这个事件就会“消失”,而且接收不到下一次事件。
为什么View有dispatchTouchEvent方法?
因为View可以注册很多事件的监听器,如长按、滑动、点击等,它也需要一个管理者来分发
Android下的数据存储方式有那些?
- 内部存储,直接存储在内部文件中
- 外部存储,首先要判断外部存储条件是否可用,然后进行存储
- SP存储,底层是Xml实现的,以键值对形式存储内部的数据,适宜于轻量级的存储,存储的数据类型有,boolean,String,int
- 数据库存储,SQlite存储,轻量级的数据库,强大的增删改查功能
- 内容提供者,ContentProvider,将自己愿意暴露的一部分数据供外部使用操作
- 网络存储,等
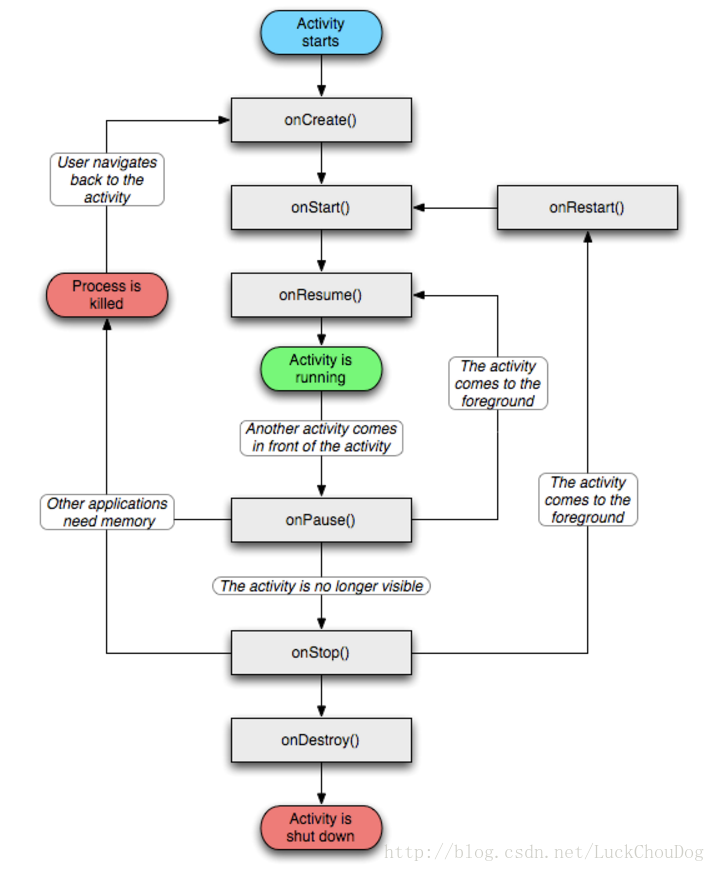
Activity生命周期
Activity四种启动模式?
Activity的启动模式指,可以根据实际开发需求为Activity设置对应的启动模式,从而可以避免创建大量重复的Activity等问题。
1. standard
standard为Activity的默认启动模式,可以不用写配置。在这个模式下,都会默认创建一个新的实例。因此,在这种模式下,可以有多个相同的实例,也允许多个相同Activity叠加。(点back键会依照栈顺序依次退出)
2. singleTop
singleTop模式下,Activity可以有多个实例,但是不允许多个相同Activity叠加。即,如果Activity在栈顶的时候,启动相同的Activity,不会创建新的实例,而会调用其onNewIntent方法。
3. singleTask
singleTask表示只有一个实例。在同一个应用程序中启动他的时候,若Activity不存在,则会在当前task创建一个新的实例,若存在,则会把task中在其之上的其它Activity destory掉并调用它的onNewIntent方法。如果是在别的应用程序中启动它,则会新建一个task,并在该task中启动这个Activity,singleTask允许别的Activity与其在一个task中共存,也就是说,如果我在这个singleTask的实例中再打开新的Activity,这个新的Activity还是会在singleTask的实例的task中。
4. singleInstance
只有一个实例,并且这个实例独立运行在一个task中,这个task只有这个实例,不允许有别的Activity存在。