1.需求背景
说句实话,在我参与的项目中,多线程用处不多,但确实用到了,有时候多线程用好了,的确能大大提高系统的性能与效率。这里我就举例我在项目中用到的需求,若有不当之处,还请多多指教。
需求1:获取各个类型在各个时间段内的数据量
获取结果通过Echarts展示如下图所示:

如果按正常流程编写接口也能查询到对应的数据,或者你会说总共最多9种类型,我可以new Thread9个多线程来同时跑呀!确实是可以,但是朋友,你知道通过new Thread的方式代价是很大的,内存的消耗,资源的分配,如果服务器配置允许还好,如果有限呢,我敢保证你的系统很快就会出问题的。
new Thread的弊端:
a. 每次new Thread新建对象性能差。
b. 线程缺乏统一管理,可能无限制新建线程,相互之间竞争,及可能占用过多系统资源导致死机或oom。
c. 缺乏更多功能,如定时执行、定期执行、线程中断。
线程池的好处:
a. 重用存在的线程,减少对象创建、消亡的开销,性能佳。
b. 可有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞。
c. 提供定时执行、定期执行、单线程、并发数控制等功能。
那既然你都想到了用多个线程来跑,为什么不使用线程池呢?java5之后在java.util.concurrent包下提供很多便捷的并发包。通过使用线程池,可以方便的管理线程的创建与回收,一开始我也是直接new 出了多个线程来搞的,后来的确系统出问题了。在排查问题的过程中,通过jconsole或者jvisualvm发现便能看到很多问题。
需求2:获取事件列表,同时异步获取每个事件的信息量

简单来说,就是先从数据库查询事件的基本信息,对于事件的信息量,需要走检索通过事件配置的关键词和时间段及其他条件获取对应的信息量。对于事件,简单来说,就是相当于配置的一个规则,截张图吧,这样比较直观,容易理解,如下图就是事件配置的页面:
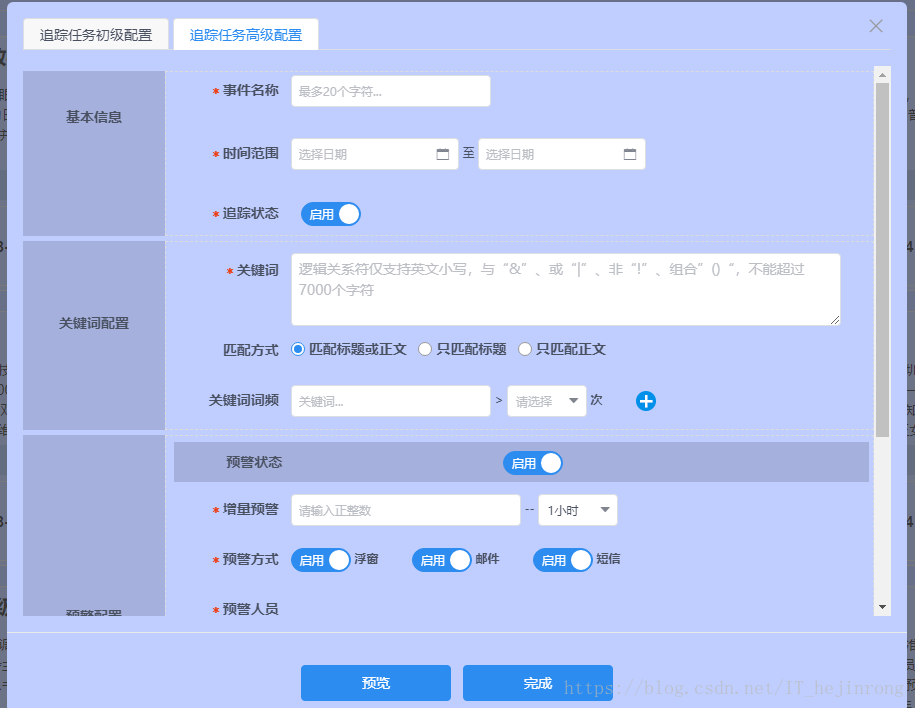
拼接成sql是这样的:select ID from db_11,db_13,db_22,db_21,db_31,db_12,db_41,db_42,db_43 where ( ( db_11.Title,db_13.Title,db_21.Title,db_31.Title,db_12.Title,db_41.Title ) : ( 江歌&(日本|刘鑫|陈世峰) ) | Content: ( 江歌&(日本|刘鑫|陈世峰) ) ) & ( Content@Frq3:(江歌) or Title@Frq3:(江歌) ) & CreateDate:[201712140901,201712150901], 其实这个sql你们可以不用管,反正就是个查询数据量的接口。重点是首先要先查询出事件列表,再去异步查询每个事件的信息量,有人可能会问了,为什么不直接把事件及信息量一起查询出来呢?这种方式为什么不行,我觉得你站在用户体验的角度去想想就明白了,代码都有注释,这里我用到了并发包下的newFixedThreadPool(创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待),这里我根据我的机器配置设置了一个定值THREADNUM = 10,意思就是最多同时启用10个线程,若事件有15个,会先同时处理10个,其余5个等待,其他线程哪个处理完了就继续接收任务进行处理,如果你的服务器配置够高,线程数可以设置为事件个数。
public Object queryEventTaskInfoCounts(String eventIds, Long organId) { //如果前端传入事件id,则说明查询单个事件的信息量 if(StringUtils.isNotBlank(eventIds)) { SearchFilter searchFilter = dealWithEventTaskParams(Long.valueOf(eventIds), organId); return ftsSearchService.ftsCount(searchFilter); } StringBuffer eventTaskIds = new StringBuffer(""); //查询指定机构下启用的事件 List<EventTrack> eventTrackList = baseMapper.selectList(new EntityWrapper<EventTrack>().addFilter("status = {0} and organid = {1}", 1, organId)); if(eventTrackList != null && eventTrackList.size() > 0) { for(EventTrack event : eventTrackList) { eventTaskIds.append(event.getId()).append("#"); } } if(StringUtils.isBlank(eventTaskIds.toString())) { log.info("事件id集合为空,查询结束"); return null; } eventIds = eventTaskIds.toString(); //创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待 ExecutorService exe = Executors.newFixedThreadPool(THREADNUM); List<Future<Map<Long, Long>>> futureList = new ArrayList<>(); List<EventTrack> resultList = new ArrayList<>(); String[] eventIdArr = eventIds.split("#"); //先把获取每个事件的信息量任务提交到线程池 for(String id : eventIdArr) { //这里用到了Callable,需要返回结果,一个事件一个Callable任务 Callable<Map<Long, Long>> worker = new EventCallable(Long.valueOf(id), organId); //提交到线程池 Future<Map<Long, Long>> submit = exe.submit(worker); futureList.add(submit); } for(Future<Map<Long, Long>> future : futureList) { try { //此时这里会一直阻塞,直到所有线程任务都处理完了才会继续往下走 Map<Long, Long> resultMap = future.get(); for(Map.Entry<Long, Long> map : resultMap.entrySet()) { EventTrack eventTrack = new EventTrack(map.getKey(), map.getValue()); //加入到返回集合中 resultList.add(eventTrack); } } catch (InterruptedException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } exe.shutdown(); return resultList; } /** * 查询事件信息量的内部类 */ class EventCallable implements Callable<Map<Long, Long>> { private Long eventId; private Long organId; public EventCallable(Long eventId, Long organId) { this.eventId = eventId; this.organId = organId; } @Override public Map<Long, Long> call() throws Exception { //封装查询参数 SearchFilter searchFilter = dealWithEventTaskParams(eventId, organId); Map<Long, Long> resultMap = new HashMap<>(); //请求检索获取数据量 Long infoCount = ftsSearchService.ftsCount(searchFilter); resultMap.put(eventId, infoCount); return resultMap; } }
我在项目中用到多线程最多都是查询,至于新增或修改可能就需要考虑同步和锁的问题了,我在这里用到的只是并发包下其中一个,还有如下:
Java通过Executors提供四种线程池,分别为:
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。