版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u010251278/article/details/53427677
在一篇论文[1]中,该论文的作者给出了在满足某种条件下的数学推算。

假设每个节点通信周期都能选择(感染)一个新节点,则Gossip算法退化为一个二分查找过程,每个周期构成一个平衡二叉树,收敛速度为O(n2 ),对应的时间开销则为O(logn )。这也是Gossip理论上最优的收敛速度。但在实际情况中最优收敛速度是很难达到的,假设某个节点在第i个周期不被感染的概率为pi ,第i+1个周期不被感染的概率为pi+1 ,且每个周期只感染一个节点,则pull的方式:

而push为:
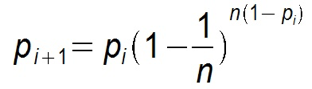
显然pull的收敛速度大于push,也即一个节点不被感染的概率更快趋于0!
Reference:
[1] Terry,D. B., Demers, A. J., Greene, D. H., Hauser, C., Irish, W., & Larson, J.,et al. (1988). Epidemic algorithms for replicated database maintenance. AcmSigops Operating Systems Review, 22(1), 8-32.