一、VRRP概述
随着Internet的发展,人们对网络的可靠性的要求越来越高。对于局域网用户来说,能够时刻与外部网络保持联系是非常重要的。通常情况下,内部网络中的所有主机都设置一条相同的缺省路由,指向出口网关,实现主机与外部网络的通信。局域网客户端判定哪个路由器应该为其到达目标主机的下一跳网关的方式有动态及静态决策两种方式,其中动态路由发现方式有如下几种:
- Proxy ARP —— 客户端使用ARP协议获取其想要到达的目标,而后,由某路由以其MAC地址响应此ARP请求;
- Routing Protocol —— 客户端监听动态路由更新(如通过RIP或OSPF协议)并以之重建自己的路由表;
- ICMP IRDP (Router Discovery Protocol) 客户端 —— 客户端主机运行一个ICMP路由发现客户端程序;
动态路由发现协议的不足之处在于它会导致在客户端引起一定的配置和处理方面的开销,并且,如果路由器故障,切换至其它路由器的过程会比较慢。解决此类问题的一个方案是为客户端静态配置默认路由设备,这大大简化了客户端的处理过程,但也会带来单点故障类的题。当出口网关发生故障时,主机与外部网络的通信就会中断,LAN客户端仅能实现本地通信。
VRRP诞生
IETF(Internet Engineering Task Force)推出了VRRP(Virtual Router Redundancy Protocol)虚拟路由冗余协议,来解决局域网主机访问外部网络的可靠性问题。VRRP可以通过在一个路由器组(一个VRRP组)之间共享一个虚拟IP(VIP),此时仅需要客户端以VIP作为其默认网关即可。可以认为VRRP是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个MASTER和多个BACKUP,MASTER上有一个对外提供服务的VIP(该路由器所在局域网内其他机器的默认路由为该VIP),MASTER会发组播,当BACKUP收不到vrrp包时就认为MASTER宕掉了,这时就需要根据VRRP的优先级来选举一个BACKUP当MASTER,及时将业务切换到其它设备,从而保持通讯的连续性和可靠性,消除了静态路由配置的单点故障。VRRP协议对应的是RFC3768,该协议仅适用于IPv4。
基本概念

工作原理
1、一个VRRP路由器有唯一的标识:
VRID,范围为0-255该路由器对外表现为唯一的虚拟MAC地址,地址的格式为00-00-5E- 00-01-[VRID]主控路由器负责对ARP请求用该MAC地址做应答这样,无论如何切换,保证给终端设备的是唯一一致的IP和MAC地址,减少了切换对终端设备的影响。
2、VRRP控制报文只有一种:
VRRP通告(advertisement)它使用IP多播数据包进行封装,组地址为224.0.0.18,发布范围只限于同一局域网内。这保证了VRID在不同网络中可以重复使用。为了减少网络带宽消耗,只有主控路由器才可以周期性的发送VRRP通告报文,备份路由器在连续三个通告间隔内收不到VRRP或收到优先级为0的通告则启动新的一轮VRRP选举。
3、在VRRP路由器组中按优先级选举主控路由器:
VRRP协议中优先级范围是0-255。若VRRP路由器的IP地址和虚拟路由器的接口IP地址相同,则称该虚拟路由器作VRRP组中的IP地址所有者。IP地址所有者自动具有最高优先级:255。优先级0一般在IP地址所有者主动放弃主控者角色时使用。可配置的优先级范围为1-254,优先级的配置原则可以依据链路的速度、成本、路由器性能和可靠性以及其它管理策略来设定。在主控路由器的选举中,高优先级的虚拟路由器获胜,因此,如果在VRRP组中有IP地址所有者,则它总是作为主控路由的角色出现。对于相同优先级的候选路由器,则按照IP地址大小顺序选举。VRRP还提供了优先级抢占策略,如果配置了该策略,高优先级的备份路由器便会剥夺当前低优先级的主控路由器而成为新的主控路由器。
4、为了保证VRRP协议的安全性,提供了两种安全认证措施:
明文认证和IP头认证明文认证方式要求:在加入一个VRRP路由器组时,必须同时提供相同的VRID和明文密码适合于避免在局域网内的配置错误,但不能防止通过网络监听方式获得密码IP头认证的方式提供了更高的安全性,能够防止报文重放和修改等攻击
VRRP的优势:
- 负载共享:允许来自LAN客户端的流量由多个路由器设备所共享;
- 多VRRP组:在一个路由器物理接口上可配置多达255个VRRP组;
- 抢占:在master故障时允许优先级更高的backup成为master;
- 通告协议:使用IANA所指定的组播地址224.0.0.18进行VRRP通告;
- VRRP追踪:基于接口状态来改变其VRRP优先级来确定最佳的VRRP路由器成为master;
- 冗余:可以使用多个路由器设备作为LAN客户端的默认网关,大大降低了默认网关成为单点故障的可能性;
- 多IP地址:基于接口别名在同一个物理接口上配置多个IP地址,从而支持在同一个物理接口上接入多个子网;
二、Keepalived详解
Keepalived是基于VRRP协议实现的保证集群高可用的一个服务软件,运行在LVS之上,它的主要功能是实现真机的故障隔离及负载均衡器间的失败切换FailOver,可以防止单点故障。LVS结合keepalived,就实现了3层、4层、5/7层交换的功能,下面摘录来自官网的一段描述http://www.keepalived.org/
The main goal of the keepalived project is to add a strong & robust keepalive facility to the Linux Virtual Server project. This project is written in C with multilayer TCP/IP stack checks. Keepalived implements a framework based on three family checks : Layer3, Layer4 & Layer5/7. This framework gives the daemon the ability of checking a LVS server pool states. When one of the server of the LVS server pool is down, keepalived informs the linux kernel via a setsockopt call to remove this server entrie from the LVS topology. In addition keepalived implements an independent VRRPv2 stack to handle director failover. So in short keepalived is a userspace daemon for LVS cluster nodes healthchecks and LVS directors failover.
从这段描述中,可以得到几个有用的信息:
- keepalived是lvs的扩展项目,因此它们之间具备良好的兼容性。
- 通过对服务器池对象的健康检查,实现对失效机器/服务的故障隔离。
- 负载均衡器之间的失败切换failover,是通过VRRPv2(Virtual Router Redundancy Protocol)stack实现的。
Keepalived 体系结构
Keepalived 大致分两层结构:用户空间 user space和内核空间 kernel space
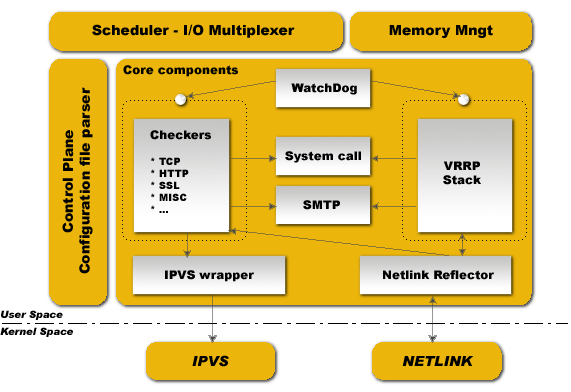
在这个结构图里,处于下端的是内核空间,它包括IPVS和NETLINK两个部分。netlink提供高级路由及其他相关的网络功能,如果在负载均衡器上启用netfilter/iptable,将会直接影响它的性能。处于图形上方的组件为用户空间,由它来实现具体的功能,下面选取几个重要的来做说明:
- WatchDog 负责监控checkers和VRRP进程的状况;
- Checkers 负责真实服务器的健康检查healthchecking,是keepalived最主要的功能;
- VRRP Stack负责负载均衡器之间的失败切换FailOver;
- IPVS wrapper 用来发送设定的规则到内核ipvs代码;
- Netlink Reflector 用来设定 vrrp 的vip地址等。
Keepalived正常运行时,会启动3个进程,分别是core、check和vrrp。
- vrrp模块是来实现VRRP协议的;
- check负责健康检查,包括常见的各种检查方式;
- core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。
配置文件
Keepalived安装完成后,会在安装目录/usr/local/keepalived生成 bin,etc,man,sbin这4个目录。其中etc为配置文件所在的目录,keepalived目录下面包含一个完整的配置文件样例keepalived.conf以及一些单独的配置样例文件
注意:
keepalived的启动过程并不会对配置文件进行语法检查,就算没有配置文件,keepalived的守护进程照样能够被运行起来。在不指定配置文件位置的状态下—keepalived默认先查找文件 /etc/keepalived/keepalived.conf ,可以手动创建这个文件,然后在这个文件里书写规则,来达到控制keepalived运行的目的。
配置文件keepalived.conf,里面主要包括以下几个配置区域:global_defs、vrrp_script、vrrp_instance和virtual_server。全局定义块和虚拟服务器定义块是必须的,如果在只有一个负载均衡器的场合,就不需要VRRP实例定义块。
花括号”{}”用来分隔定义块,必须成对出现,由于定义块内存在嵌套关系,因此很容易遗漏结尾处的花括号,这点要特别注意。
全局定义块主要配置故障发生时的通知对象以及机器标识
global_defs {
notification_email {
a@abc.com
b@abc.com ##故障发生时给谁发邮件通知
}
notification_email_from c@abc.com ##通知邮件从哪个地址发出
smtp_server 192.168.200.1 ##通知邮件的smtp地址
smtp_connect_timeout 30 ## 连接smtp服务器的超时时间
router_id LVS_DEVEL ##标识本节点的字条串,故障发生时,邮件通知会用到
}vrrp_script区域主要用来做健康检查的,当时检查失败时会将vrrp_instance的priority减少相应的值。
vrrp_script chk_http_port {
script "path to scirpts "
interval 1
weight -10
}VRRP实例定义块主要用来定义对外提供服务的VIP区域及其相关属性
vrrp_instance VI_1 {
state MASTER ##可以是MASTER或BACKUP,不过当其他节点keepalived启动时会将priority比较大的节点选举为MASTER
interface eth0 ##对外提供服务的网络接口,用来发VRRP包
virtual_router_id 1 ## 取值在0-255之间,用来区分多个instance的VRRP组播, 同一网段中该值不能重复,并且同一个vrrp实例使用唯一的标识
priority 100 ##用来选举master的,要成为master,那么这个选项的值最好高于其他机器50个点,该项取值范围是1-255(在此范围之外会被识别成默认值100)
advert_int 1 ##发VRRP包的时间间隔,即多久进行一次master选举,可以认为是健康查检时间间隔,单位为秒
authentication {
auth_type PASS ##认证类型有PASS和AH(IPSEC),通常使用的类型为PASS,同一vrrp实例MASTER与BACKUP 使用相同的密码才能正常通信
auth_pass 12345678
}
virtual_ipaddress { ##可以有多个VIP地址,每个地址占一行,不需要指定子网掩码,必须与RealServer上设定的VIP相一致
192.168.200.16
192.168.200.17
}
track_script {
chk_http_port
}
notify_master <STRING>|<QUOTED-STRING>
notify_backup <STRING>|<QUOTED-STRING>
notify_fault <STRING>|<QUOTED-STRING>
notify <STRING>|<QUOTED-STRING>
}
}notify_master/backup/fault 分别表示切换为主/备/出错时所执行的脚本。
notify 表示任何一状态切换时都会调用该脚本,并且该脚本在以上三个脚本执行完成之后进行调用,keepalived会自动传递以下三个参数
($1 = "GROUP"|"INSTANCE",$2 = name of group or instance,$3 = target state of transition(MASTER/BACKUP/FAULT))虚拟服务器定义块
virtual_server 192.168.200.16 80 { ##定义RealServer对应的VIP及服务端口
delay_loop 6 ##延迟轮询时间(单位秒)
lb_algo rr ## 后端调试算法(load balancing algorithm)
lb_kind NAT ##LVS调度类型NAT/DR/TUN
nat_mask 255.255.255.0
persistence_timeout 50 ##持久连接超时时间
protocol TCP ##转发协议protocol.一般有TCP和UDP两种
sorry_server ##当所有RealServer宕机时,sorry server顶替
real_server 192.168.200.100 80 { ##RealServer的IP和端口号,改组可在下面定义多个
weight 1
HTTP_GET {
url {
path / ##请求Real Serserver上的路径
digest ff20ad2481f97b1754ef3e12ecd3a9cc
status_code 200 ##用genhash算出的结果和http状态码
}
connect_timeout 3 ##超时时长
nb_get_retry 3 ##重试次数
delay_before_retry 3 ##下次重试的时间延迟
}
}
}
关于配置文件的说明可根据实际应用的场景做具体配置,在接下来总结一下LVS负载均衡高可用集群的相关知识点
使用负载均衡技术主要的目的:
1、系统高可用性:组成系统的某些设备或部件失效,并不会影响正常的服务。
2、系统可扩展性:用户的增加,引起访问数乃至流量的增加,这种情形下,需要对系统进行扩容,以应对这种快速增长。对于提供高可用服务的互联网网站,其对可扩展的基本要求就是在保持系统服务不终止的情况下,透明的扩充容量,即用户不知道扩容的存在,或者说是扩容不对现有的服务产生任何负面作用。这些扩展主要包括:带宽扩展、服务器扩展、存储容量扩展、数据库扩展等,当然也包括主机增加内存等方面的扩展。
3、负载均衡能力:一个应用或服务由数个物理服务器提供,并且每个物理服务器运行的应用或服务是相同的,可以通过某种控制策略把用户的访问分摊到不同的物理服务器,从而保持每个物理服务器有比较合理的负载。当整个系统的负载趋于饱和时,通过增加物理服务器和扩充物理带宽来解决这个麻烦。增加物理服务器以后,系统的负载情况将重新在所有集群的物理服务器之间按照指定的算法重新达到新的均衡。
负载均衡构成
一个完整的负载均衡项目,一般由虚拟服务器、故障隔离及失败切换3个功能框架所组成。
- 虚拟服务器是负载均衡体系的基本架构,它分两层结构:转发器(Director)和真实服务器。
- 故障隔离指虚拟服务器中的某个真实服务器(或某几个真实服务器)失效或发生故障,系统将自动把失效的服务器从转发队列中清理出去,从而保证用户访问的正确性;另一方面,当实效的服务器被修复以后,系统再自动地把它加入转发队列。
- 失败切换是针对负载均衡器Director采取的措施,在有两个负载均衡器Director的应用场景,当主负载均衡器(MASTER)失效或出现故障,备份负载均衡器(BACKUP)将自动接管主负载均衡器的工作。
要从技术上实现虚拟服务器、故障隔离及失败切换3个功能,需要两个工具:ipvsadm和keepalived。当然也有heartbeat这样的工具可以实现同样的功能,但相对于keepalived,heartbeat的实现要复杂得多(如撰写ipvsadm脚本,部署ldirectord,编写资源文件等)。在采用keepalived的方案里,只要ipvsadm被正确的安装,简单的配置唯一的文件keepalived就行了。
Ipvs(IP Virtual Server)是整个负载均衡的基础,如果没有这个基础,故障隔离与失败切换就毫无意义了。在大部分linux发行版中,ipvs被默认安装,FreeBSD也可以支持LVS,只不过实现起来要麻烦一些。注意:只有执行ipvsadm以后,才会在内核加载ip_vs模块;不能以查进程的方式判断ipvs是否运行。
如果下载最新的ipvsadm版本,在创建连接文件/usr/src/linux后,执行编译时,可能需要修改/boot/grub/grub.conf启动内核名称。一旦当前运行内核与连接文件所代表的内核名不一致时,将出现找不到*.h这样的错误,从而导致安装不能正常进行。
LVS集群运行维护
当配置集群环境并通过各项功能测试后,要实现负载均衡环境真正的高可用并符合业务需求,还需要以下操作:负载均衡环境中对象新增、变更及删除,状态监控,故障的排查处理等。
对象新增、变更及删除
这里的对象包括VIP、RealServe、服务VIP+端口号)等;一对负载均衡器,可以承担多个服务的转发任务,因此在运行过程中,很可能因为业务本身的变化而新增、变更或删除对象。比如:某个服务负载趋于饱和,需新加服务器;有些业务下线了,需要从转发队列中把服务删除掉。对象增加、变更及删除的操作,涉及Director和RealServe。在Director上的主要操作就是修改keepalived的配置文件keepalived.conf;在RealServe上主要的操作主要是编写lvs配置脚本、运行或者关闭这个配置脚本。在有2个Director的LVS环境中,所作的配置文件keepalived.conf变更操作要在这两个服务器上都进行一遍,以保持配置和服务的一致性。
当我们进行对象增加、变更或删除的操作时,只要注意好执行的先后顺序,就能保证提供的服务不中断,用户的正常访问不受影响。
● 对象新增
假定在负载均衡环境新增一个web服务器,其操作顺序是:
1、启用新增服务器的web服务。
2、启用新增服务器的lvs客户端配置脚本。
3、检验“1”和“2”两步的正确性。
4、修改负载均衡器的配置文件keepalived.conf。
5、关闭第一个lvs负载均衡器,所有的转发服务将切换到另外一个负载均衡器上。
6、启用“5”关闭的那个负载均衡器,然后关闭“5”中还在运行的那个负载均衡器。
7、重新启动“6”所关闭的负载均衡器。
● 删除对象
假定在负载均衡环境删除一个web服务器,其操作顺序是:
1、关闭欲下线服务器的web服务。这样负载均衡器的健康检查会自动把该web服务从转发队列删除掉。
2、卸载欲下线服务器的vip地址。即执行/usr/local/bin/lvs_real stop操作。
3、修改负载均衡器的配置文件keepalived.conf。
4、关闭第一个lvs负载均衡器,所有的转发服务将切换到另外一个负载均衡器上。
5、启用“4”关闭的那个负载均衡器,然后关闭“4”中还在运行的那个负载均衡器。
6、重新启动“6”所关闭的负载均衡器。
● 变更对象
与前两种方式的操作步骤基本相似,不再赘述。
注意:如果真实服务器上的服务没关闭而把其上的vip卸载的话,某些用户的请求仍然会被负载均衡器转发过来,导致请求失败。因此,无论如何,请先关服务!
状态监控
为了随时随地了解整个lvs负载均衡环境的运行情况,必须对其进行有效的监控。当出现异常或故障时,监控系统能及时有效的通知维护人员,以便问题得以及时地处理。这也是提高可靠性的一个保障措施。有很多开源的或商业类型的监控系统可供选择,例如开源的nagios
可供nagios监控的对象很多,对LVS负载均衡环境而言,怎么选定对象才是最有效的呢?回顾一下LVS负载均衡环境运行时,其存在的表现形式
- 负载均衡器及真实服务器
- 各真实服务器上运行的服务
- LVS公用的VIP
根据这些表现形式,选取存活检查及服务状态作为监控对象,就可以清晰地了解LVS负载均衡环境的运行状况。把它具体化,可分为:
- 负载均衡器及真实服务器的存活检查。只有这些服务器运行正常,才可能有其他依赖服务。
- VIP的存活检查。一般情况下,启用了LVS环境后,是可以用ping的方式检查VIP的。
- 真实服务器服务状态检查。
- VIP对应的服务状态检查。一般通过check_tcp加端口号的形式实现。如果web集群,可以以check_http!url的方式更精确的检查。
故障处理
在对lvs运行环境进行有效的监控后,一旦有故障或异常发生,系统管理人员将会得到及时的通知。并且这些报警信息往往包含故障的基本情况,如负载过高、主机down了、服务严重不可用(critical)、磁盘空间快满了等等,这些信息非常有利于系统管理员定位故障点。在知晓和定位故障以后,结下来就是分析和处理故障。Lvs负载均衡的故障点可分为:负载均衡器故障、真实服务器故障、vip故障、服务故障这几个部分。这些故障出现后,怎么着手处理?下面分别论述之。
● 负载均衡器发生故障的检查点
1、 查看系统日志 /var/log/messages ,了解内核是否有报错信息。因为keepalived的日志也被追加到系统日子,因此通过系统日志,也能了解keepalived的运行情况。
2、 检查负载均衡器的网络连通状况。这包括ip地址的设置是否正确,是否能远程访问(如ping 、tracert等)。
3、 检查keepalived的运行情况。这包括进程是否处于运行中,ipvs模块是否被加载到系统的内核,vip是否被绑定到网络接口,ipvsadm是否有输出。
4、 检查负载均衡器的系统负载。
5、 检查keepalived的配置文件书写是否正确。因为keepalived启动过程不对配置文件做语法检查,因此在运行前,必须按需求表逐项检查配置文件keepalived.conf 的内容。有时,就可能就是因为漏写了一个“}”符号而导致意外的结果。配置文件的内容检查还包括主从优先级priority、虚拟路由标识virtual_router_id、路由标识router_id等几个部分,这些值有些是必须相同的、有些则必须不同。
6、 检查负载均衡器是否启用防火墙规则。
● 真实服务器发生故障的检查点
1、 查看系统日志 /var/log/messages ,了解内核是否有报错信息。
2、 检查服务器的网络连通状况。
3、 检查服务是否正常运行。可以结合察看进程、模拟用户访问来确定。
4、 检查服务器的负载情况,看哪些进程占用较高的资源。如果暂停占资源高的进程,情况会怎么样?
5、 检查vip是否被绑定。Linux只能通过ip add 指令察看,freebsd 用ifconfig就可以了。
6、 检查主机防火墙是否被启用。如果需要启用主机防火墙,则应设置好过滤规则。
7、 从客户端直接访问服务器的服务,看是否能正常访问。这是dr模式的一个优点。
● vip发生故障的检查点
1、 检查负载均衡器的vip是否被绑定。
2、 检查负载均衡器ipvsadm的输出,察看输出的vip项是否与我们的设定相一致。
3、 检查各真实服务器的vip是否被绑定。
4、 从客户端测试一下vip的连通情况,如ping vip。
5、 检查vip地址是否与其它服务器的地址相冲突。
● 服务发生故障检查点
1、 检查服务是否正常运行。如查进程、模拟用户访问等。
2、 检查系统的负载情况。
3、 检查是否启用主机防火墙。
数据备份
LVS负载均衡环境需要备份的数据包括keepalived配置文件和LVS客户端配置脚本。因为这两个文件都是文本文件,并且尺寸小(几k而已),因此可以以复制的方式进行备份。
其他:
LVS负载均衡转发模式
负载均衡转发模式包括直接路由模式DR、网络地址转换模式NAT以及隧道模式TUN三种。在一般的互联网应用环境,选择直接路由模式是比较有利的:
- DR利用大多数Internet服务的非对称特点,负载调度器中只负责调度请求,而服务器直接将响应返回给客户,可以极大地提高整个集群系统的吞吐量。从原理上可以知道,DR模式下,负载均衡器的输出和输出流量应该是基本一致的
- 排错方便迅速。如果通过VIP访问不到服务,则可以直接通过访问真实服务器的方式直接定位问题的所在。
- 当负载均衡器都停止工作时,DR模式易于应急处理。通过修改DNS的A记录,把先前主机名对应的VIP改成真实服务器的IP地址,使服务迅速恢复起来,从而赢得时间处理负载均衡器的故障。
负载均衡器的调度算法
一般的互联网应用,多采用轮叫调度rr(Round-Robin Scheduling)及加权最小连接调度wlc(Weighted Least-Connection Scheduling)。
LVS负载均衡环境安全问题
在负载均衡器上,为了获得更好的转发性能,尽量不要使用主机防火墙。那么,这怎样保证系统的安全呢?个人觉得,还是采购硬件防火墙放在负载均衡器的前面比较可靠。如果资金充裕,购买具备防ddos的硬件防火墙则更胜一筹。
分割集群
关于负载均衡器后面真实服务器的数量,最佳的策略可能是:根据访问情况对大的应用进行分割,弄成一个个小的集群。具体到一个网站,可以把访问量大的频道独立出来,一个频道或几个频道组成一个lvs负载均衡集群。