网络是很抽象的,但是在wireshark里面却又是相对直观的。这里我们列举了5个问题来进一步直观地学习TCP协议,并且从中了解分析网络性能的一般方法。
问题一:关于子网掩码和网关
服务器A和B的网络配置如下:
A:
IP address: 192.168.26.129
Subnet mask: 255.255.255.0
Default gateway: 192.168.26.2
B:
IP address: 192.168.26.3
Subnet mask: 255.255.255.224
Default gateway: 192.168.26.2
B的子网掩码本应该是255.255.255.0,被不小心配成了255.255.255.224,它们还能正常通信吗?运用我们学过的网络知识,子网掩码是用来判断任意两台计算机的IP地址是否属于同一子网络的依据。最为简单的理解就是两台计算机各自的IP地址与子网掩码进行“与”运算后,如果得出的结果是相同的,则说明这两台计算机是处于同一个子网络上的,可以进行直接的通信,就这么简单。
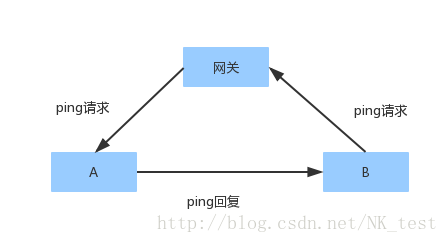
在B上ping A,由于在B看来B_IP&B_mask的结果和A_IP&B_mask的结果不一致,也就是A和B不属于同一个子网。因为跨子网通信需要默认网关的转发,所以B要先通过ARP广播查询默认网关192.168.26.2的MAC地址,之后默认网关再把包转发给A。由于在A看来A_IP&A_mask和B_IP&A_mask的结果一致,也就是A和B属于同一个子网,所以B可以直接收到A发出的ARP广播,不需要默认网关的参与。之后由于A和B都已经知道对方的MAC地址,不必再发送ARP广播,直接就是ping请求和ping回复了。
通信过程如下图:
问题二:关于MTU
我们都知道网络分层的基本概念,如果我们现在有一个比较大的写操作,比如8192字节,那么TCP层是不是简单的加上TCP头就可以交给网络层了呢?很显然答案是否定的,因为网络对包的大小有限制,其最大称为MTU,即“最大传输单元”。大多数网络的MTU是1500字节,但也有些网络启用了巨帧(Jumbo Frame),能达到9000字节,一个8192字节的包进入巨帧网络不会有问题,但到了1500字节的网络中就会被丢弃或者切分。被丢弃意味着传输彻底失败,因为重传的包还会被丢弃,而被切分则意味着传输效率降低。
由于这个原因,TCP不想简单的将8192字节的数据一口气传给网络层,而是根据双方的MTU决定每次传多少。知道自己的MTU容易,那么对方的MTU是如何获取的呢?如图,TCP三次握手的时候,双方都会把自己的MSS告诉对方,MSS+TCP头和IP头的长度,就得到MTU了。而且发包的大小是由MTU较小的一方决定的。

另外,如果网络路径上存在着一个MTU小于1500的设备,这个包还是可能被丢弃或者切分,所以这个方案并不完美,但是至今没有更好的办法。
在这里我还要说一个我实习时候遇到的关于MTU的一个问题,两台主机通过OVS网桥使用vxlan协议传输数据,但是传输大数据时速度很慢,不到正常值的1/10。后来发现vxlan会对所有经过OVS网桥的数据包进行一个封包操作,也就是会在头部增加几个字节。这样数据包在经过设置为MTU 1500的设备时就会发生丢弃或者切分,从而导致这个问题。将设备的MTU 适当调小之后恢复正常。如果没有深入地了解MTU并且使用wireshark或者tcpdump抓包的话,是很难发现这个问题的。
问题三:经常听说“TCP Window Scale”这个概念,他究竟和接收窗口有何关系?
TCP刚发明的时候,全世界的网络带宽都很小,所以最大接收窗口被定义为65535字节。随着硬件的革命性进步,65535字节已经成为性能瓶颈了。1992年的RFC中提出了一个解决方案,就是在三次握手的时候,把自己的Window Scale信息告知对方,作用就是向对方声明一个Shift count,我们把它作为2的指数,再乘以TCP头中定义的接收窗口,就得到真正的TCP接收窗口了。
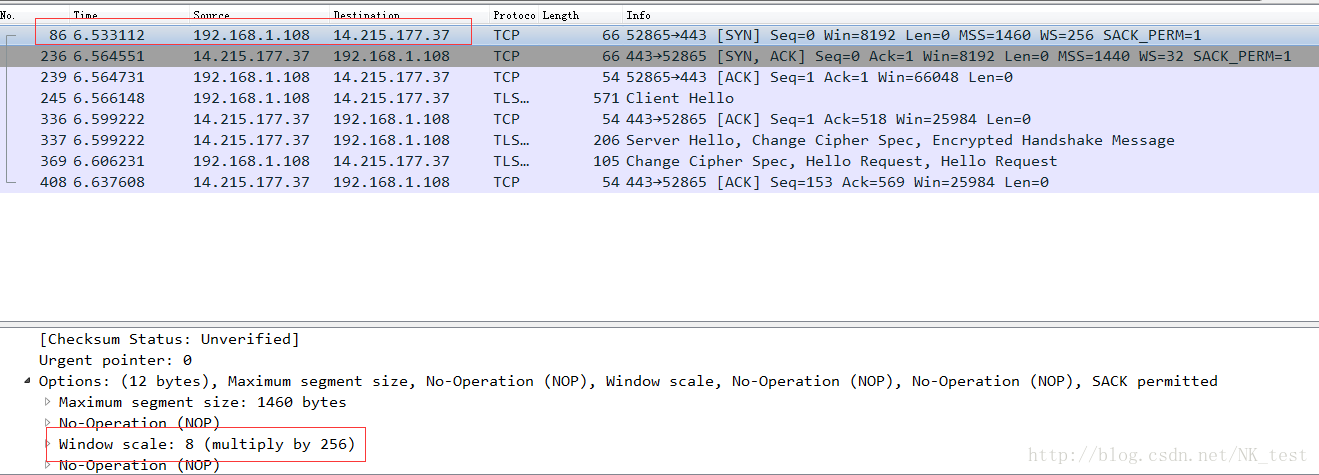
如下图:192.168.1.108告诉14.215.177.37说它的Shift count是8。2的8次方是256,这就意味着以后192.168.1.108声明的接收窗口要乘以256才是真正的窗口值。
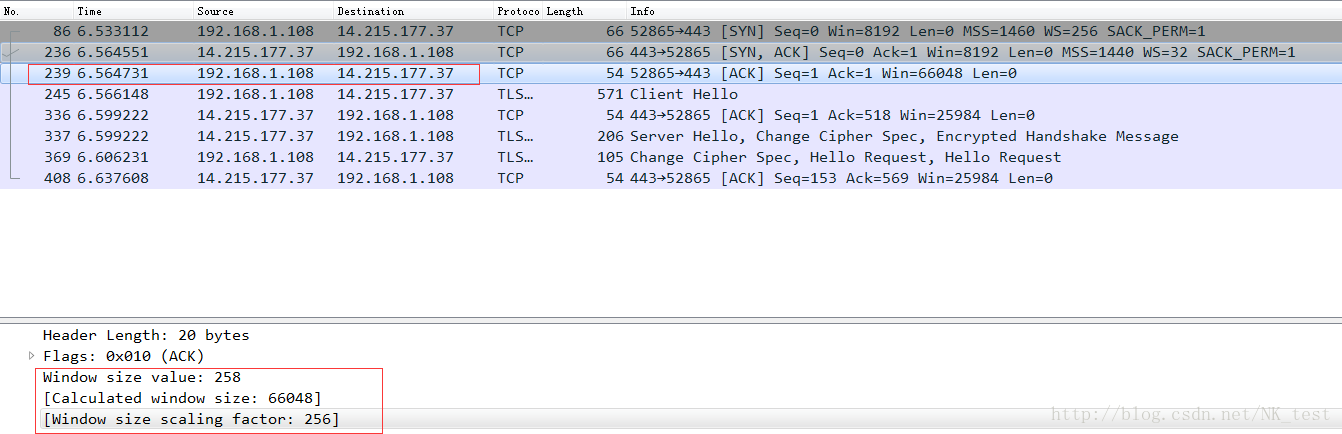
如下,192.168.1.108声明自己的接收窗口是183,183*256=66048,所以wireshark就显示Win=66048了。注意:如果抓包的时候没有抓到三次握手,那么wireshark就不知道如何计算,所以有时候我们会很莫名的看到一些极小的接收窗口值。还有些时候是防火墙识别不了Window Scale,因此对方无法获得Shift count,最终导致严重的性能问题。
问题四:关于TCP重传
想必大家都看过计算机网络方面的教材,但是扪心自问,除了记住概念,你又是否真的了解TCP滑动窗口和重传的设计呢?
先说一个误区,很多人把window size(也就是win=)误认为是发送窗口,其实这不是发送窗口,而是在向对方声明自己的接收窗口。如果接收方处理数据的速度跟不上接收数据的速度,缓存就会被占满,从而导致接收窗口为0,对方接收到win=0的信息后,就会将自己的发送窗口限制为0,不会再发送数据。
另外,发送窗口除了受接收方的接收窗口影响之外,还受到网络的影响(也就是我们常说的拥塞窗口),其中限制的更严的因素起到决定作用。
网络之所以能限制发送窗口,是因为他一口气收到太多数据时就会拥塞,拥塞的结果是丢包,这是发送方最忌惮的。
接下来我们开看看拥塞窗口如何维护:
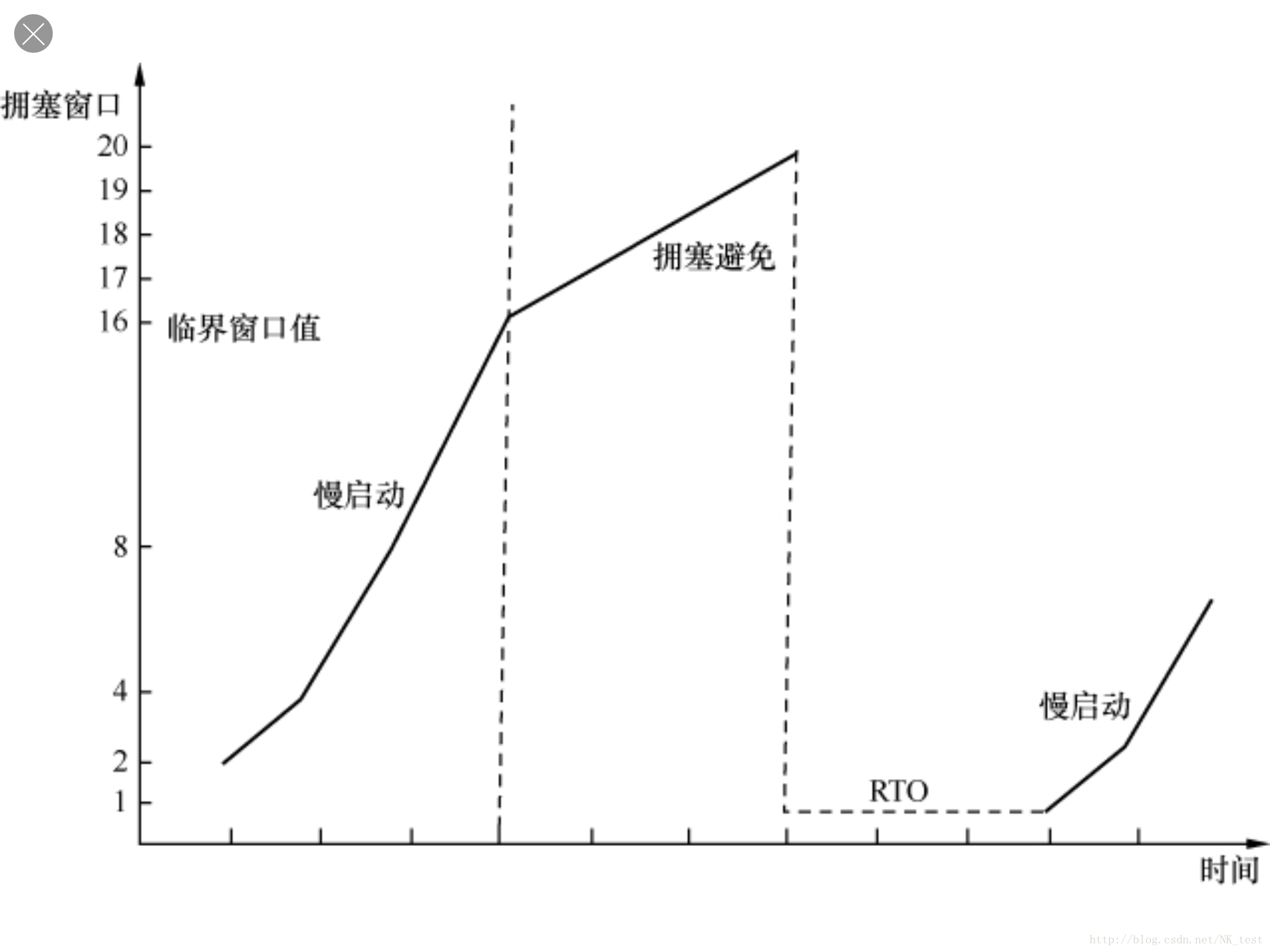
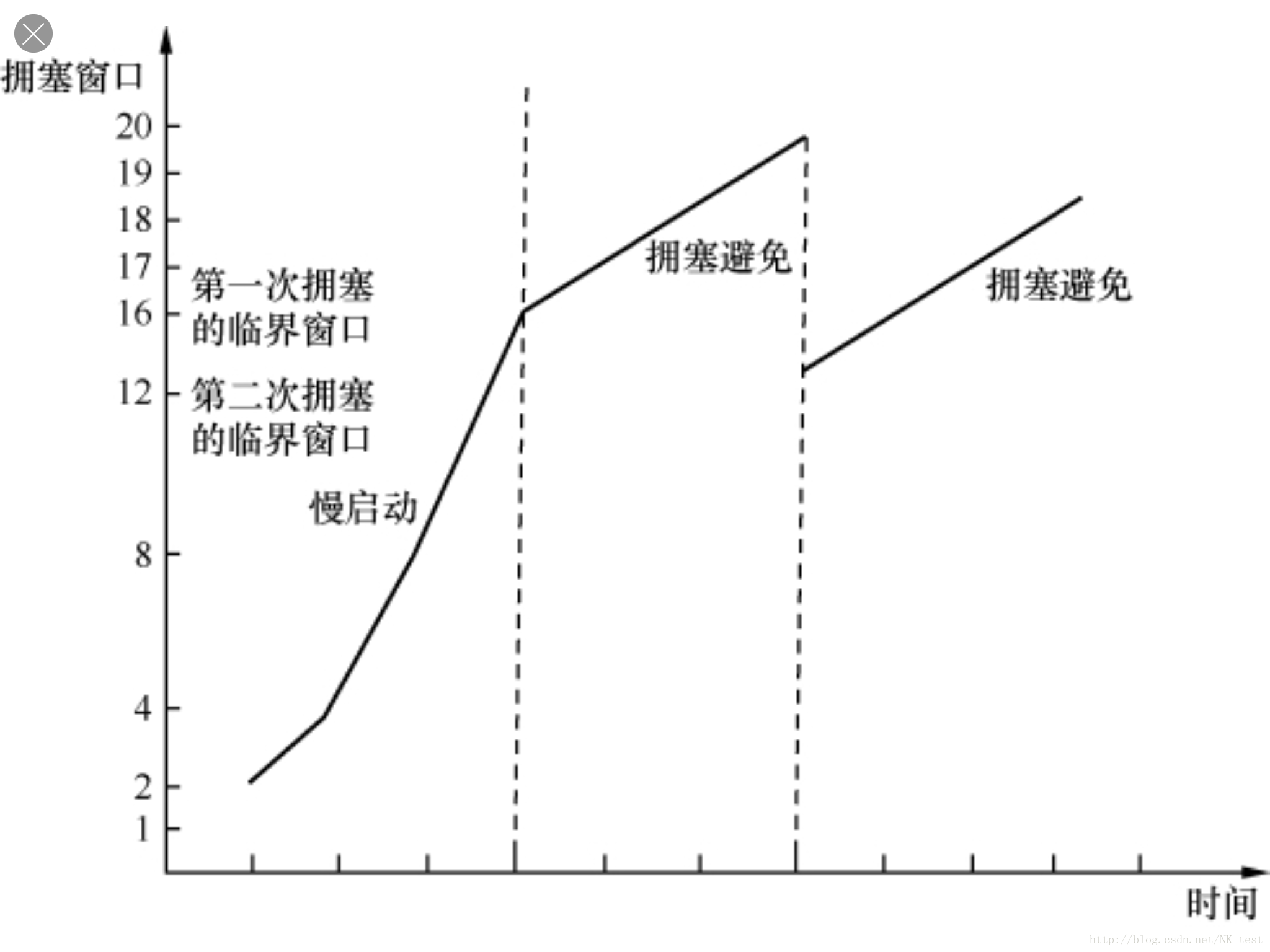
1. 连接刚建立的时候,发送方对网络状况一无所知,TCP采用慢启动(指数增长)+拥塞避免(线性增长)的方式来试探拥塞点。如果之前发生过拥塞,就把该拥塞点作为参考依据,如果从来没有拥塞过就可以取相对较大的值,比如和最大接收窗口相等。
2. 那么拥塞之后会发生什么情况呢?
对发送方来说,就是发出去的包不像往常一样得到确认了。不过收不到确认也可能是网络延迟所致,所以发送方决定等待一小段时间再去判断,如果迟迟收不到,就认定包已经丢失了,需要重传,这个过程称为超时重传。从发出原始包到重传该包的这段时间称为RTO。那么重传之后的拥塞窗口是否需要调整呢?很显然是非常有必要的,为了不给拥塞的网络雪上加霜,RFC建议把拥塞窗口降到1个MSS,然后再次进入慢启动。那么这一次从慢启动过渡到拥塞避免的临界窗口值就有参考依据了。RFC 5681认为应该是发生拥塞时没被确认的数据量的1/2,但是不能小于2个MSS。不难想象,超时重传对传输性能有严重影响。原因之一是在RTO阶段不能传数据,相当于浪费了一段时间;原因之二是拥塞窗口的急剧减小,使得传输速率受到影响。所以,即使是万分之一的超时重传对性能的影响也非同小可。
有时候拥塞很轻微,只有少量的包丢失,还有些偶然因素,比如校验码不对的时候会导致单个丢包。这两种丢包的症状和严重拥塞时的不一样,因为后续有包能够正常到达。当后续的包到达接收方时,接收方会发现其Seq号比期望的大,所以它每收到一个包就Ack一次期望的Seq号,以此提醒发送方重传。当发送方收到3个或以上重复确认(Dup Ack)时,就意识到响应的包已经丢了,从而立即重传它,这个过程称为快速重传。
为什么要规定凑满3个呢?这是因为网络包有时候会乱序,乱序的包一样会触发重复的Ack,但是为了乱序而重传没有必要。由于一般乱序的距离不会相差太大,比如2号包也许会跑到4号包后面,但是不太可能跑到6号包后面,所以限定成3个或以上可以在很大程度上避免因乱序而触发快速重传。
那么快重传情况下的临界窗口值如何设置呢?RFC 5681认为临界窗口值应该设为发生发生拥塞时还没被确认的数据量的1/2(但是不能小于2个MSS)。然后将拥塞窗口设置为临界窗口值加3个MSS,继续保留在拥塞避免阶段。这个过程成为快速恢复。
问题五:延迟确认与Nagle算法
发送窗口一般只影响大块的数据传输,比如读写大文件。而频繁交互的小块数据不太在乎发送窗口的大小,因为发包量本来就小。日常场景中比如用ssh客户端连接linux服务器,随便输入一些字符,在网络上就交互了很多小块的数据了。其实这种方式是很低效的,因为TCP头和IP头至少40字节,而携带的数据却只有几个字符。
延迟确认就是处理这种交互式场景的一种策略。原理是这样的:如果收到一个包之后暂时没有数据要发给对方,那就延迟一段时间(windows上默认200ms)再确认。这样在这段时间内如果恰好有数据要发送,那就可以在一个包里发送了。它减少了部分确认包,减轻了网络负担。
还是ssh客户端的场景,一个RTT内发送的字符仍然会被逐个打成小包发送,能不能把在一个RTT内生成的小数据收集起来,合并成一个大包呢?Nagle算法实现的就是这个功能。原理是:在发出去的数据还没有被确认之前,假如又有小数据生成,那就把小数据收集起来,凑满一个MSS或者等收到确认后再发送。
注意:在某些场合,延迟确认和Nagle算法一起使用甚至会降低性能。具体的案例会在下一篇文章中介绍。
参考资料
《wireshark网络分析就是这么简单》
《计算机网络》谢希仁
RFC文档