Fabric共识机制结构
共识:在Fabric中,共识过程意味着多个Peer节点对于某一批交易的发生顺序、合法性以及它们对账本状态的更新达成一致的观点。
共识相关组件
在Fabric中,共识是通过背书、排序和验证三个环节的保障。
背书过程:背书节点对收到的来自客户端的请求(交易提案)按照自身的逻辑进行检查,以决策是否予以支持的过程。
对于调用某个链码的交易来讲,它需要获得一定条件的背书才被认为合法。例如,必须是来自某些特定身份成员的一致同意;或者某个组织中超过一定数目的成员的支持等等;这些背书策略可以由链码在实例化之前来指定。
排序过程:对一段时间内的一批交易达成一个网络内全局一致的顺序。
Fabric中,采用可插拔式的架构,solo模式(测试使用)、Kafka在内的CFT类型后端、BFT类型后端。
验证过程:对排序后的一批交易进行提交到账本之前最终检查的过程。
验证过程包括验证交易结构自身完整性,背书签名是否满足背书策略,交易的读写集是否满足多版本并发控制等。
排序服务
在Fabric中所有交易在交付给Committer进行验证接受之前,需要先经过排序服务进行全局排序。排序服务提供了原子广播排序功能。
Fabric1.0架构中排序服务的功能的服务抽取出来,作为单独的fabric-orderer模块实现,代码在fabric/orderer目录下。
排序服务主要有三部分组成:gRPC协议对外提供服务接口、账本组件网络中的每个应用通道维护区块链结构、排序插件同不同类型的排序后端打交道。
共识插件
Solo:单节点的排序功能,实验版。
Kafka:基于Kafka集群的排序实现。支持CFT容错,支持可持久化和可扩展性,可以再生产环境中用。
SBFT:支持BFT容错的排序实现,开发中。
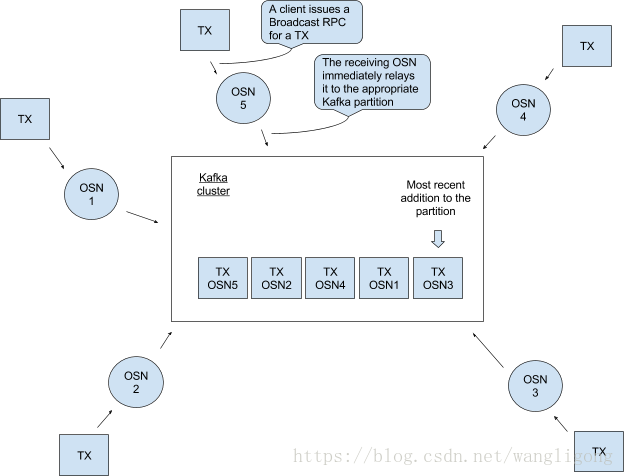
Kafka排序后端:
通过使用kafka提供排序服务,并且使用容错的方式保证多链数据的一致性。如图所示,排序服务是有kafka集群、ZK ensemble、orderer服务节点(在ordering service client 和 Kafka集群+ZK ensemble之间)。
其中ordering service client可以直接与多个OSN节点通信(orderer service node),注意osc不能直接和kafka cluster进行通信。
这些排序服务节点(OSNs)①client身份验证,②允许clients通过简单的接口进行读写链,③对配置交易(这些交易要么重新配置链要么重新创建一个链)的交易的过滤和验证
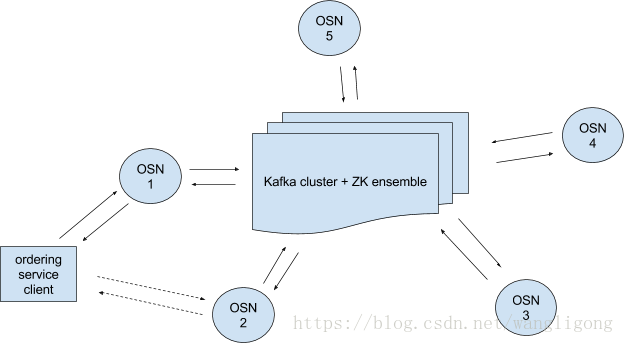
kafka角色介绍
消息以主题为划分写入Kafka,一个Kafka集群包括多个主题,每个主题有包含多个分区。 每个分区是一个不断增长的、有序的、不可变的记录序列。
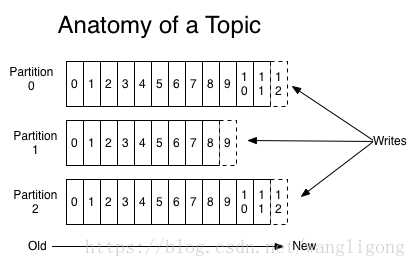
一个由三个分区组成的主题.分区中的每个记录都带有偏移量作为标记

如图:每个链都有一个独立的分区,在OSN对交易完成客户端验证和筛选后就可以提交到Kafka对应的分区。同样的他们可以从分区中读取所有的交易,这对于OSNs都是相同的。
这种设计架构的问题和解决方案:
1.如果每一笔交易的到达,都进行验证,打包,切割,成本太高。
批量打包交易到块解决1k/s交易数等高频次交易
2.批量打包,若是交易到达的频率不一致,会出现延迟交付的问题,这是不希望看见的。
通过设置batchSize和batchTimeout,这两个任意一个条件先满足,块就会被切割。
3.基于时间切块,需要保证OSNs之间的同步。
通过在各个orderer之间设置一个显式的协调信号来进行控制,(TTC-n,TimeToCut),并将该消息上送至kafka,以第一个TTC-n为准出块,后续重复的TTC-n将被忽略,以达到一致。

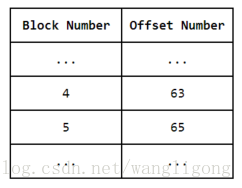
4.若是交易在同一个块中,OSN根据块高度同步数据,但块高度和kafka的offset没有关联上,无法识别kafka的断点位置。
通过每个OSN针对每条链都要维护一个检索表,记录了块高度和offset的对应关系,而不需要使用块的metadata数据。
5.每个OSN在收到分发请求后,都要从当前的节点进行追溯,每个节点都要进行相同的操作,而且该操作的代价比较昂贵。
6.kafka中存在冗余的消息;检索表会被请求,分发请求处理逻辑相对复杂,检索表操作会增加等待时间。
持久化已生成的块数据,每个OSN本地存储一个日志记录。同时解决了问题5和6。选举一个OSN的leader (ZK或谁产生TTC-x谁是主) ,由它负责分区1上下一个块数据的产生。但是仍然可能出现冗余数据:主节点提交块X后宕掉,此时选举出新的主节点,它判断块X仍未提交,所以将自己的块X提交,此时原主节点的数据也提交至kafka上,出现冗余数据。
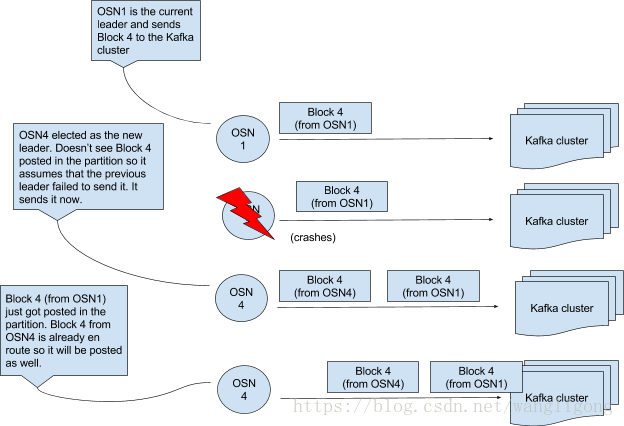
进一步解决冗余数据问题,尝试记录压缩,但是会导致检索表数据超时。
进一步提出解决方案,如下图,在我们发送交易和TTC-X的地方继续使用分区0,同时各个OSN维护一个对于每条链信息的本地日志。
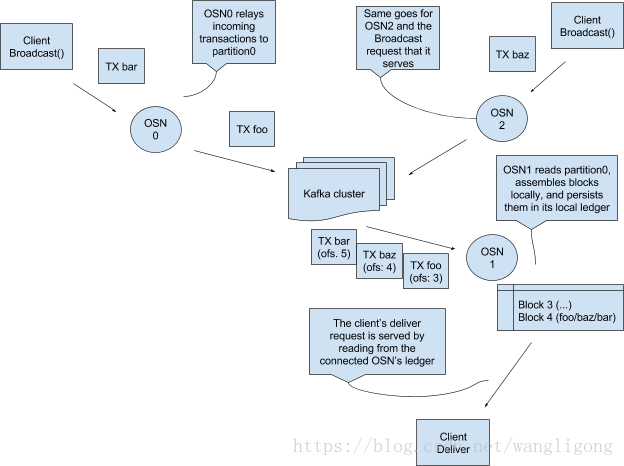
这种方案基本解决了在设计中遇到的所有问题。优势①解决交付请求现在只是从本地的平台上顺序读取的问题②最大的使用orderer的公共组件。
最终在性能和复杂性之间取得平衡实现如下架构,
参考: A Kafka-based Ordering Service for Fabric
区块链原理设计与应用