上一篇文章简单介绍了下Flume的背景,接下来本文说说Flume NG的内部设计。注意:本文针对的是Flume1.6.0版本。
上一篇:http://manzhizhen.iteye.com/blog/2298150
我们先来看看为什么需要Flume,在大数据分析领域,最重要的就是数据,而日志作为首选数据来源之一,有着举足轻重的地位,如今企业的线上业务服务器,少则几十台上百台,多则上千台,这么多台线上服务器,按照每台每天平均产生出50G的日志来算,如果线上共有100台服务器,则每天就可以产生差不多5TB的日志量,而将些日志流数据高效可靠的写入hdfs,我们应该怎么做?有人会说每台业务服务器自己往HDFS写啊,no,no,no,这样做的话hdfs表示受不了,我们一定要考虑到“供需稳定和平衡”,又有人马上会说:用Kafka!的确,Kafka作为高吞吐量的MQ实现之一,性能上肯定是没问题,而且Kafka作为Apache另一顶级项目,最初就是作为日志系统出生。Kafka现在作为流行的发布/订阅消息中间件,有Scala语言开发,广泛的用于体统之间的异步通信,特别适合异构系统之间使用。在日志传输领域,是选择Flume还是Kafka,就像皇马打巴萨那样,谁都没有压倒性的优势,但Flume纯粹为日志传输而生,开箱即用,几乎零编程,而且提供日志过滤、自定义分发等功能,并对写入HDFS等有良好的支持,如果想偷懒,则选Flume绝对没错。但现如今,Kafka+Flume+HDFS等诸多将Kafka和Flume结合起来使用的方案。
如果没有成熟的日志传输方案,我们来讨论讨论如果自己做,需要解决哪些问题。最容易想到的第一点就是效率和性能,秒级的延迟我们可以接受,但如果说线上业务系统产生一条日志数据,过了十几分钟甚至一个小时才能写到HDFS中,那是忍无可忍的。其实这点不难做到,只要架构设计的简单实用,效率和性能一般不是问题。第二点就是可靠性,只要是经过网络传输的数据,都存在丢失的可能,要做到一条日志从生产者发送到消费者,而且消费者有且仅仅消费一次,是很困难的,在某些情况下甚至是不可能的,如果做不到,那至少得做到保证至少消费一次。可靠性还涉及到Failover和可恢复,如果发生故障,能切换到其他正常服务的节点,并且出故障的节点能快速恢复。第三点就是可扩展性,可扩展性是分布式系统的标配了,如果日志量增大,我们可以动态的添加服务节点,来增加日志传输的吞吐量。第四点,得支持异构源,日志不可能只需要些到HDFS,某些日志还需要写入目的地。其实要做到以上这些点,并不容易,我们不需要重复造轮子了,因为已经有Flume了。
接下来,我们看看Flume的设计,Flume是以Agent作为基本的服务单位,类似于MQ中的Broker,一个Agent启动后就是一个Java进程,它暴露一个或多个端口来提供服务。于是你可以发现,可以叠加多个Agent来提高我们的日志服务能力,比如你可以在一个服务器上启动多个Agent的Java进程,来通过暴露多个端口来实现日志服务的横向扩展,增加日志传输能力,但也不是越多越好,应该根据CPU内核数来确定。每个Agent都对应一个配置文件,配置文件中有该Agent的所有细节。
任何日志数据在进入Agent之前会被包装成Event,所以,对于Agent来说,生命周期所基础到的每一行日志,其实都是一个Event。Event下篇会详细介绍,接下来我们看看Agent的内部结构,如果把Agent当做一个黑盒,你肯定能想到它得有个输入和输出,输入是Event的入口,而输入则表明日志将发往其他某个地方或者直接写入我们的离线数据的仓库HDFS。这个输入就是Agent三大组成部分之一的Source,输出指的是Sink,最后一个就是Channel,Channel是Event存放的地方。没错,一个Flume Agent实例就是由多个Source、多个Channel和多个Sink组成的,也就是说,你可以在Agent的配置你文件中定义多个Source、Channel和Sink。但需要注意,Source可以指定多个Channel,但一个Sink实例只能指定一个Channel,换句话说,就是Source能同时向多个Channel写入数据,但一个Sink只能从一个Channel中取数据。大体设计如下图:
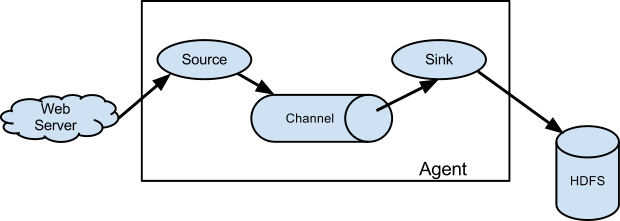
Source实例会在配置文件指定的端口来监听数据,用来接收客户端发来的Event并将其存储到Channel之中。Flume提供了多种类型的Source,用来从不同的渠道来接收Event,比如Avro Source、Thrift Source、 Kafka Source、Http Source等,Source的选型需要根据日志发送客户端来决定,如果是Avro的Client,那么它的接收源只能是Avro Source,而不能是Thrift Source。Source中有拦截器(interceptor)的概念, 用于过滤掉不符合要求的Event,或者给Event添加必要的信息,拦截器也可以组合成拦截器链,就像Servlet中的过滤器链一样。前面说过,一个Source至少要指定一个接收的Channel,当一个Source指定多个Channel时,有人肯定得问,这时一个Event会被复制多份分别放入这些Channel呢?还是负载均衡的只放入其中一个Channel呢?这个问题很好,答案是:都可以!当一个Source绑定多个Channel时,Flume提供了两种Channel写入策略:复制(replicating)和复用(multiplexing),当使用复制策略时每个Channel都会接收到一个Event的副本,而在使用复用策略时,一个Event只会下发到其中一个合格的Channel中。Flume中默认的分发策略是复用。当使用默认的复用策略时,Source接收到的消息会不会是轮询一次发给绑定的Channel来达到“负载均衡”的目的呢?其实仔细想想就知道,从写入的角度来说,将一份数据写到一个Channel和均匀的写到多个Channel,性能上会有多大差别吗?所以,Flume采用的不是简单的负载均衡的思路,而是给复用策略添加了选择器(selector)的功能,可以通过配置来做到根据Event头中的键值来决定该Event写入哪些(注意,这里是哪些,因为有可能是写入多个)Channel,还可以设置一个默认Channel,当没有匹配的键值时,就直接写入设置的默认的Channel中。那么问题来了,如果Source r1需要写入(复制策略或复用策略)到三个Channel c1,c2和c3中,如果其中的c2写入失败了,这时Source会怎么处理?大家能想到两种可能的处理方案,第一种就是打印告警日志,然后只在失败的c2上尝试重新写入。第二种就是作为一种事务来处理,c2的写入失败将导致该Event会重新再次尝试写入到c1,c2和c3中。这里,当使用的是复用策略时,我们可以在Selector上配置可选( optional)的Channel,没有配置可选标记的都是要求(required)的Channel,对于被配置可选的这些Channel来说(注意,如果某可选的Channel还出现在了required的Channel中,那么它还是required的),Source将其当做备份方案,即Source可以不必保证一定将对应的Event写入成功,Source只会向其尝试写入一次。但对于required的Channel,Source将保证其写入成功(具体细节后面后面回来补充)。
Channel用来存储Agent接收到的Event,像Source一样,Flume也提供了多种类型的Channel,常用的比如Memory Channel、File Channel、JDBC Channel、Kafka Channel。效率最高的肯定是Memory Channel,但它是不可靠的,一旦重启,全部没有消费的Event就会丢失。最常用最简单的就是File Channel,它将Event先写入指定的文件中,所以重启的话大部分没有消费的Event还是会保留。为了保证端到端(end to end)的可靠性,只有Sink成功消费了Event,Event才会从Channel中删除。
Sink用于将Event写入到其他的目的地,这个目的地可以是HDFS、Kafka等开源实现,或者是另一个Flume Agent,Flume提供了足够多的Sink的实现,达到配置后开箱即用。常用的Sink实现有Avro Sink、HDFS Sink、Kafka Sink、Thrift Sink、Null Sink、Logger Sink等。如果使用Null Sink,将直接丢弃从Channel取出来的Event,而Logger Sink一般用来测试,它将从Channel取出来的Event直接打印在Flume的日志文件中。
说到这里,大家应该对Flume Agent有一个大体了解了,后面的文章我再来给大家一一介绍其内部细节。下一篇:http://manzhizhen.iteye.com/blog/2298394