目录
1、需求
2、软件
3、参考文档和配置下载
4、配置过程
1)环境变量
2)Zookeeper(zookeeper-3.4.8)配置文件解说
3)hadoop(hadoop-2.7.3)配置文件解说
4)Hive(hive-2.3.2)配置文件解说
5)Hbase(hbase-1.2.6)配置文件解说
6)Spark(spark-2.0.0-bin-hadoop2.7)和Scala(scala-2.11.11)安装
7)Storm(apache-storm-1.1.2)安装
8)Kafka(kafka_2.10-0.8.1.1)安装
9)Kafka(kafka_2.11-1.0.0)安装
5、界面展示
1、需求
搭建一个单机版的Hadoop和Spark环境
2、软件
hadoop-2.7.3
zookeeper-3.4.8
hive-2.3.2
hbase-1.2.6
scala-2.11.11
spark-2.0.0-bin-hadoop2.7
apache-storm-1.1.2
kafka_2.11-1.0.0
http://archive.apache.org/dist/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz
http://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
http://archive.apache.org/dist/hbase/1.2.6/hbase-1.2.6-bin.tar.gz
http://archive.apache.org/dist/phoenix/apache-phoenix-4.14.0-cdh5.14.2/bin/apache-phoenix-4.14.0-cdh5.14.2-bin.tar.gz
http://archive.apache.org/dist/flink/flink-1.6.0/flink-1.6.0-bin-hadoop27-scala_2.11.tgz
3、参考文档和配置下载
这个pdf文件仔细看
hadoop-Apache2.7.3+Spark2.0集群搭建.pdf,
百度云下载地址:
https://pan.baidu.com/s/13TmW7dITZ9WpYfyg0OZgIw
4、配置过程
【hadoop-Apache2.7.3+Spark2.0集群搭建.pdf 】这个文档很重要,是一个集群的配置过程,先仔细看了之后,再看下面的配置。
1、环境变量
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_151.jdk/Contents/Home
export HADOOP_HOME=/Users/huiyu/DevTools/hadoop-2.7.3
export HIVE_HOME=/Users/huiyu/DevTools/apache-hive-2.3.2-bin
export HBASE_HOME=/Users/huiyu/DevTools/hbase-1.2.6
export SCALA_HOME=/Users/huiyu/DevTools/scala-2.11.11
export SPARK_HOME=/Users/huiyu/DevTools/spark-2.0.0-bin-hadoop2.7
export STORM_HOME=/Users/huiyu/DevTools/apache-storm-1.1.2
export KAFKA_HOME=/Users/huiyu/DevTools/kafka_2.11-1.0.0
export PATH=$PATH:$SPARK_HOME/bin:$HIVE_HOME/bin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$JAVA_HOME/bin:$SCALA_HOME/bin:$STORM_HOME/bin:$KAFKA_HOME/bin
2、Zookeeper配置文件解说
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/Users/huiyu/DevTools/zookeeper-3.4.8/data
clientPort=2181
3、hadoop配置文件解说
hadoop-env.sh:只要配置Java_home
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_151.jdk/Contents/Home
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/Users/huiyu/DevTools/hadoop-2.7.3/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.huiyu.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.huiyu.groups</name>
<value>*</value>
</property>
</configuration>
其中:hadoop.proxyuser.huiyu.hosts和hadoop.proxyuser.huiyu.groups是hive2需要的配置,huiyu是用户名
hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/Users/huiyu/DevTools/hadoop-2.7.3/dfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/Users/huiyu/DevTools/hadoop-2.7.3/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8032</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
备注:localhost:8032,主要是hive在执行MR时候找不到yarn,所以指定localhost:8032。
4、Hive配置文件解说
export HADOOP_HOME=/Users/huiyu/DevTools/hadoop-2.7.3
export HIVE_HOME=/Users/huiyu/DevTools/apache-hive-2.3.2-bin
export HBASE_HOME=/Users/huiyu/DevTools/hbase-1.2.6
hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.server2.transport.mode</name>
<value>binary</value>
</property>
<property>
<name>hive.server2.thrift.sasl.qop</name>
<value>auth</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.authentication</name>
<!--
<value>NOSASL</value>
-->
<value>NOSASL</value>
<description>
Expectsoneof[nosasl,none,ldap,kerberos,pam,custom].
Clientauthenticationtypes.
NONE:noauthenticationcheck
LDAP:LDAP/ADbasedauthentication
KERBEROS:Kerberos/GSSAPIauthentication
CUSTOM:Customauthenticationprovider
(Usewithpropertyhive.server2.custom.authentication.class)
PAM:Pluggableauthenticationmodule
NOSASL:Rawtransport
</description>
</property>
</configuration>
问题
NestedThrowablesStackTrace:
Required table missing : "`DBS`" in Catalog "" Schema "". DataNucleus requires this table to perform its persistence operations. Either your MetaData is incorrect, or you need to enable "datanucleus.schema.autoCreateTables"
org.datanucleus.store.rdbms.exceptions.MissingTableException: Required table missing : "`DBS`" in Catalog "" Schema "". DataNucleus requires this table to perform its persistence operations. Either your MetaData is incorrect, or you need to enable "datanucleus.schema.autoCreateTables"
解决
https://www.cnblogs.com/garfieldcgf/p/8134452.html
这样就可以开始初始化了,先启动hadoop,然后在bin目录下执行命令
yuhuideMacBook-Pro:bin huiyu$ ls
beeline ext hive hive-config.sh hiveserver2 hplsql metatool schematool
yuhuideMacBook-Pro:bin huiyu$ ./schematool -initSchema -dbType mysql
hive启动顺序
一,先启动 metastore
hive --service metastore &
二,再启动 hiveserver2
hive --service hiveserver2 &
5、Hbase配置文件解说
Hbase要重点说说:我们要的是基于Hbase外部的zookeeper所以在,hbase-env.sh设置【export HBASE_MANAGES_ZK=false】,hbase-site.xml中设置【hbase.cluster.distributed】和【base.zookeeper.quorum】两个配置
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_151.jdk/Contents/Home
export HBASE_MANAGES_ZK=false
hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>/Users/huiyu/DevTools/hbase-1.2.6/data/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/Users/huiyu/DevTools/hbase-1.2.6/data/zookeeper</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>base.zookeeper.quorum</name>
<value>localhost:2181</value>
</property>
</configuration>
6、Spark和Scala安装
Spark配置和使用,Scala就不说了。
配置spark-env.sh,加入hadoop配置的路径
/Users/huiyu/DevTools/spark-2.0.0-bin-hadoop2.7/conf/spark-env.sh
HADOOP_CONF_DIR=/Users/huiyu/DevTools/hadoop-2.7.3/etc/hadoop/
7)Storm安装
官网配置讲解
https://github.com/apache/storm/blob/v1.1.2/conf/defaults.yaml
下载
https://www.apache.org/dyn/closer.lua/storm/apache-storm-1.1.2/apache-storm-1.1.2.tar.gz
只要配置conf/storm.yaml文件,修改内容如下:
storm.zookeeper.servers:
- "127.0.0.1"
storm.zookeeper.port: 2181
nimbus.seeds: ["localhost"]
storm.local.dir: "/Users/huiyu/DevTools/apache-storm-1.1.2"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
启动命令如下:
nohup bin/storm nimbus &
nohup bin/storm supervisor &
nohup bin/storm ui &
hadoop-Apache2.7.3+Spark2.0集群搭建.pdf,
百度云下载地址:
https://pan.baidu.com/s/13TmW7dITZ9WpYfyg0OZgIw
8)Kafka(kafka_2.10-0.8.1.1)安装
需要修改的配置如下: kafka_2.10-0.8.1.1/config/server.properties
broker.id=0
log.dirs=/Users/huiyu/DevTools/kafka_2.10-0.8.1.1/kafka-log
zookeeper.connect=localhost:2181
测试:
创建topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic yuhui
展示topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181
生产者:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic yuhui
消费者:
kafka-console-consumer.sh --zookeeper localhost:2181 --topic yuhui --from-beginning
9)Kafka(kafka_2.11-1.0.0)安装
需要修改的配置如下: kafka_2.11-1.0.0/config/server.properties
broker.id=1 # 唯一ID同一集群下broker.id不能重复
listeners=PLAINTEXT://localhost:9092 # 监听地址
log.dirs=/opt/kafka_2.11-1.0.1/data # 数据目录
log.retention.hours=168 # kafka数据保留时间单位为hour 默认 168小时即 7天
log.retention.bytes=1073741824 #(kafka数据量最大值,超出范围自动清理,和 log.retention.hours配合使用,注意其最大值设定不可超磁盘大小)
zookeeper.connect:localhost:2181 #(zookeeper连接ip及port,多个以逗号分隔)
测试:
创建topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
展示topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181
生产者:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
消费者:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
5、界面展示
HDFS的UI界面

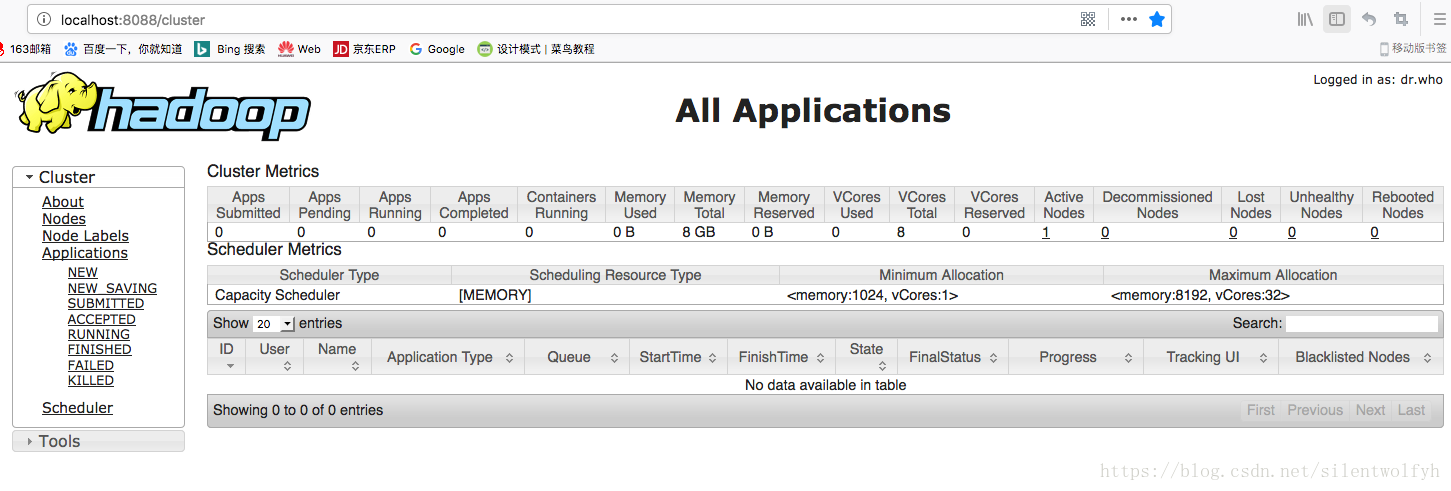
Hadoop的UI界面
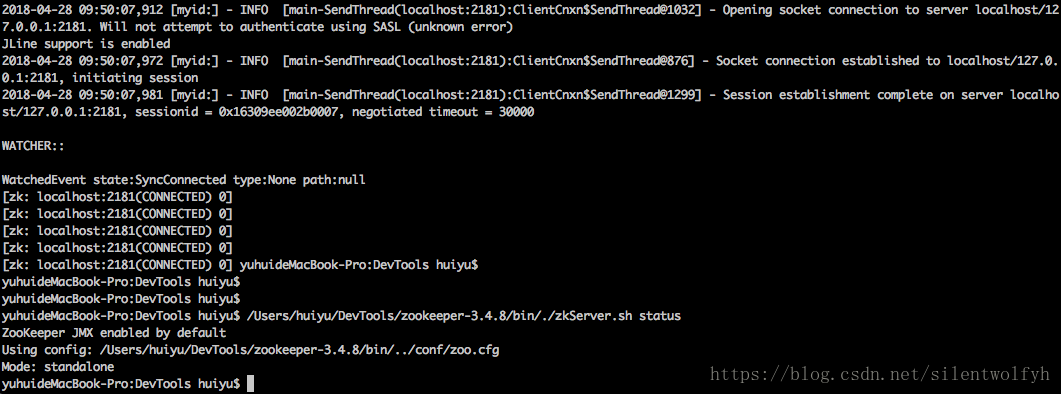
Zookeeper的Shell界面
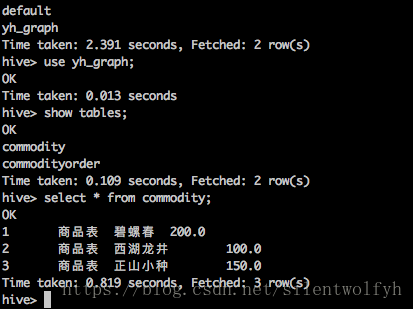
Hive的Shell界面
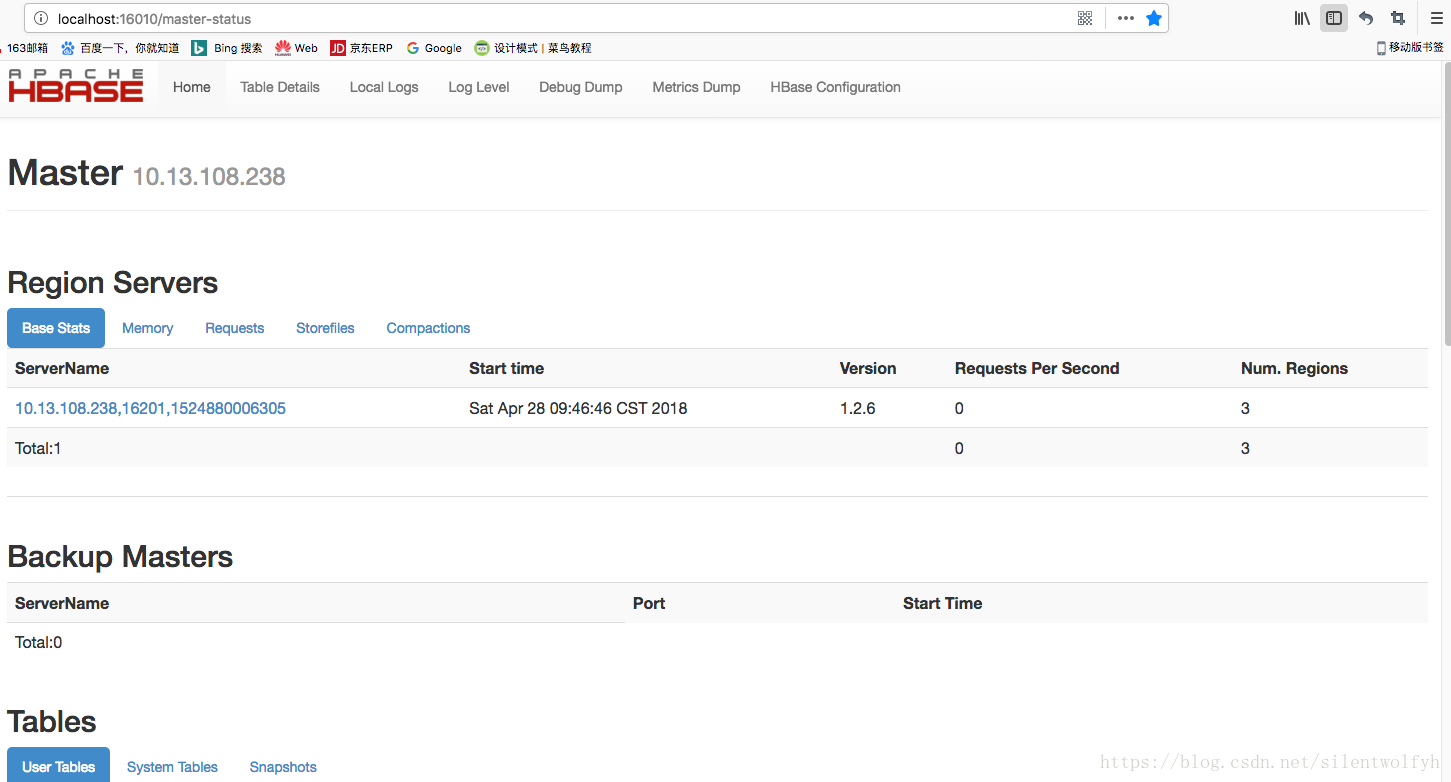
Hbase的UI界面
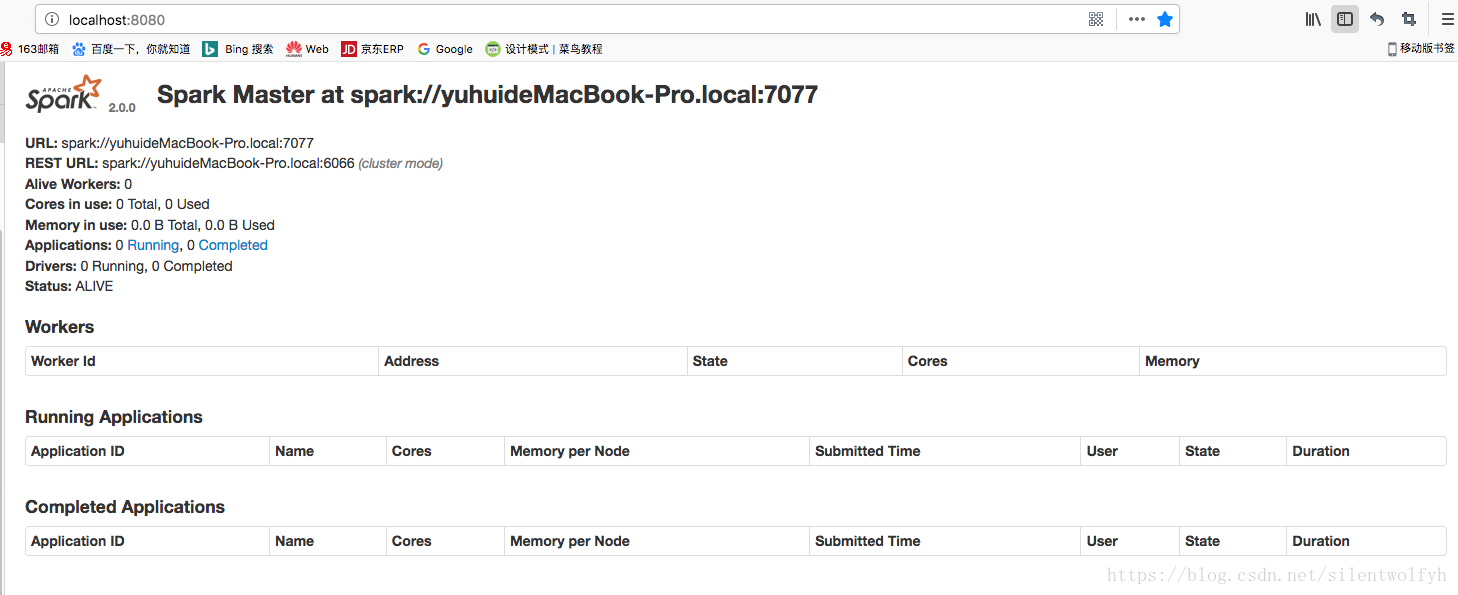
Spark的UI界面
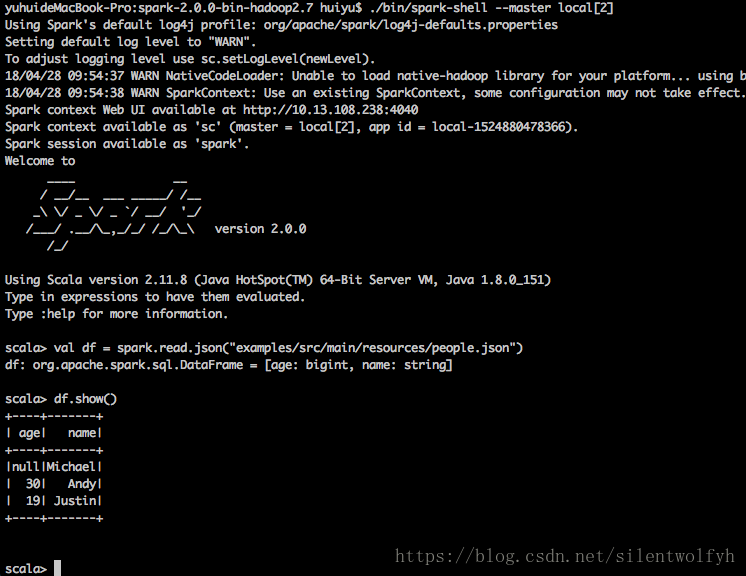
Spark的shell界面
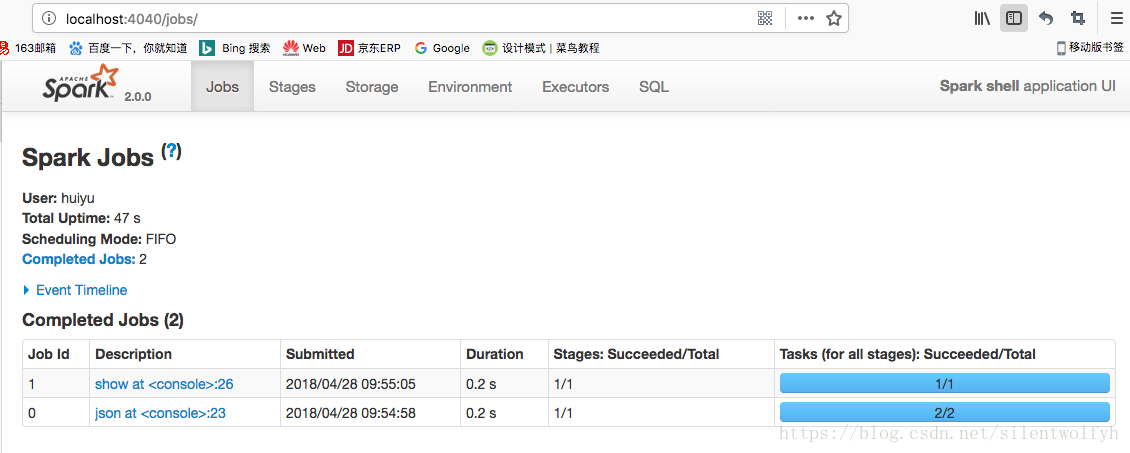
Spark的UI界面
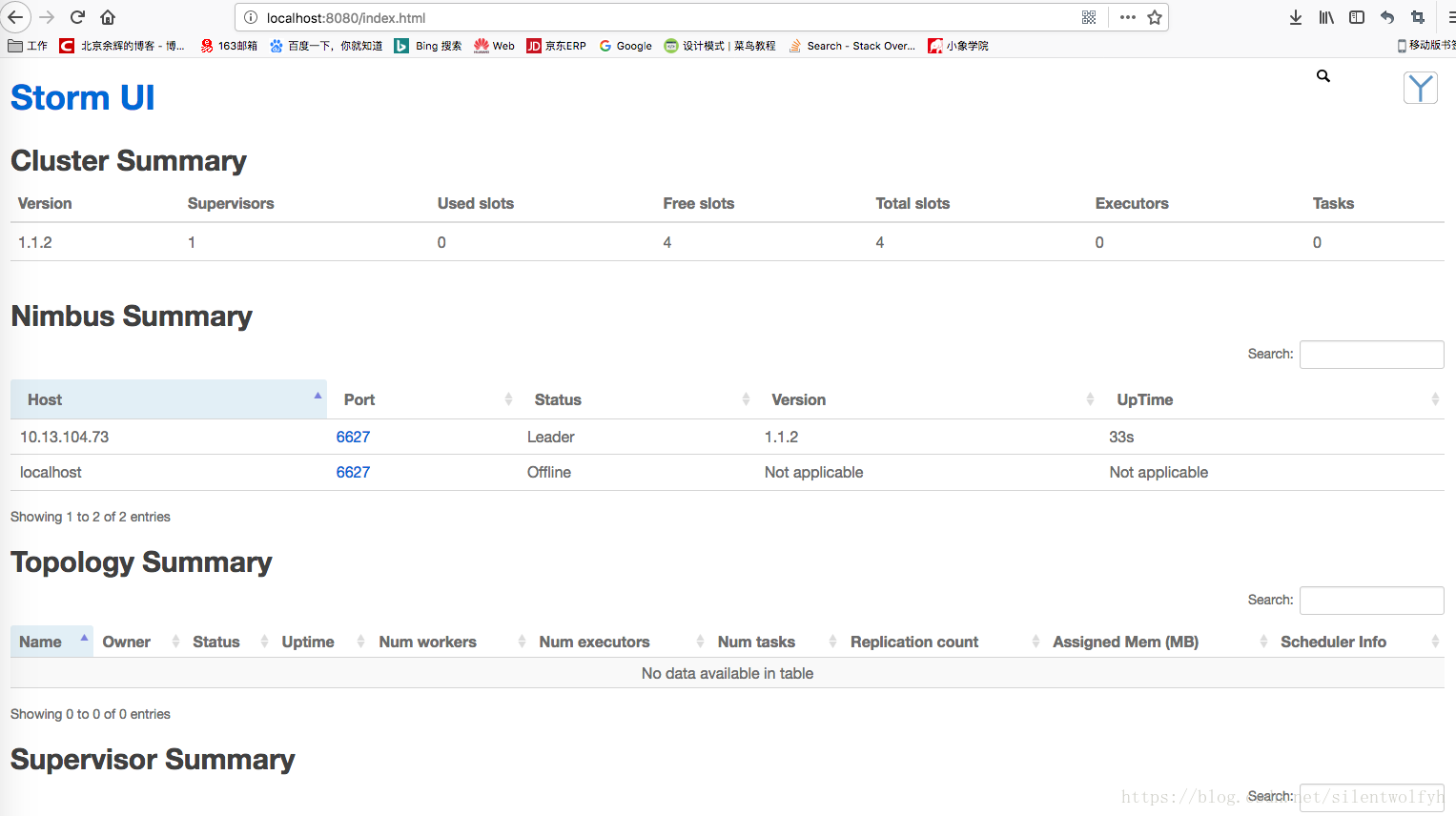
Storm的UI界面