版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/w1573007/article/details/52471012
赛题和数据
https://tianchi.shuju.aliyun.com/competition/information.htm?spm=5176.100067.5678.2.3yG798&raceId=231531
离线数据:http://pan.baidu.com/s/1o8TjuPG
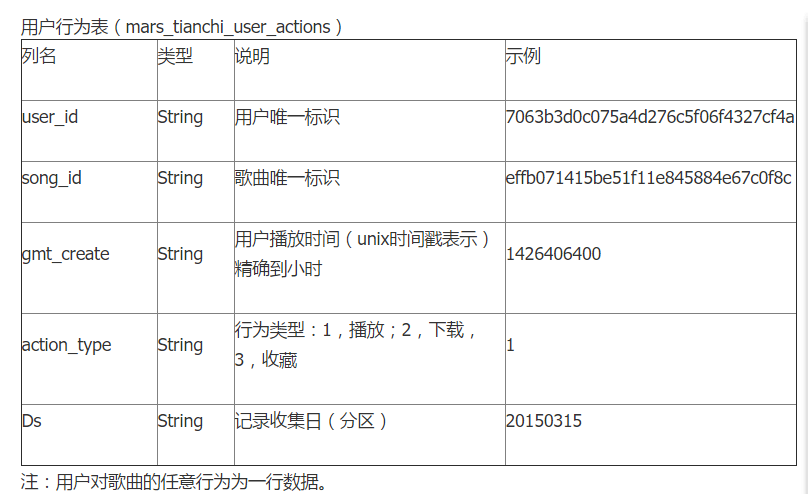
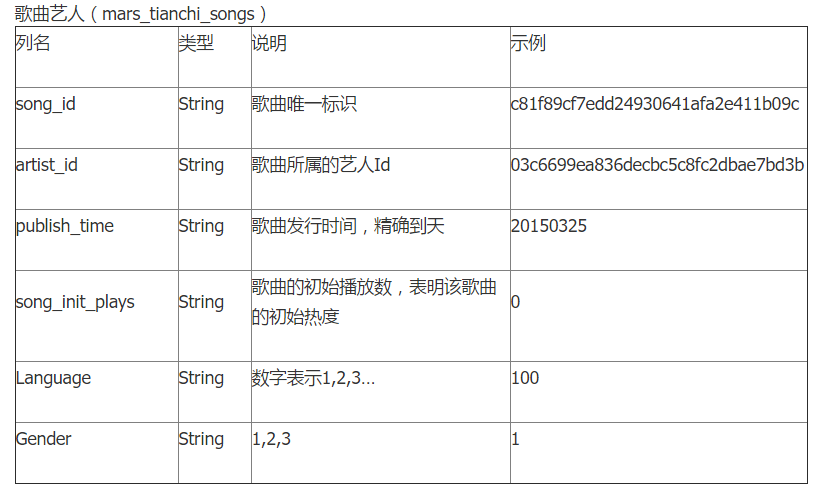
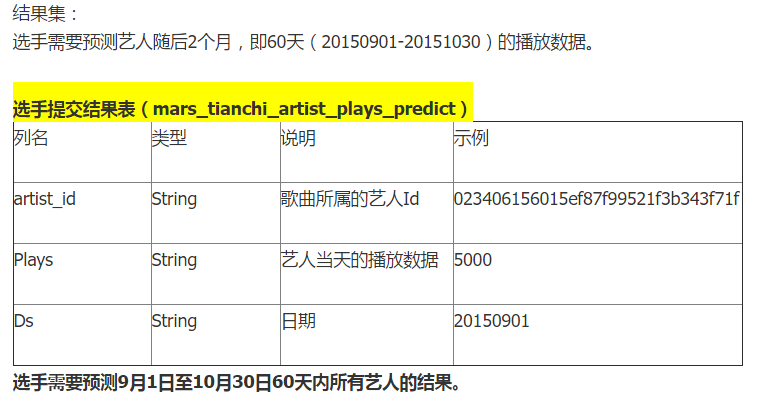
数据内容
分析
第一次参加这样的比赛,边学机器学习和python,面对这样的数据,先交7,8月的数据改成9,10数据看看结果。然而刚学编程和没学数据库,其中一个队友用一下午来导入数据,最后也没成功。
播放量的预测就是统计播放量。。。
这是我们一开始想到的。开始放写程序,这里是p2的数据,利用字典,元组,列表之间的关系创建类似二维表的数据结构,在以歌曲名为主键将两个表和起来。
最后我们采用的是时间序列预测模型,进入复赛,然后就没有然后了。时间序列预测是有瓶颈的,如果要做用户的聚类分析,再进行这样的统计可能会更好。
程序
#! usr/bin/env python
# -*- coding: utf-8 -*-
import time #引入时间函数
start = time.clock() #开始计时
actsong={} #艺人——歌曲字典
user={} #用户数据
fu=open("mars_tianchi_user_actions.csv","rb")
fo=open("p2.csv","w")
fs=open("mars_tianchi_songs.csv","rb")
#生成歌曲—艺人字典
for line in fs :
arry=line.split(",") #数据分片
song=str(arry[0])
acts=str(arry[1])
if acts in actsong :
#如果有这个艺人就添加数据,没有的话初始化数据
actsong[acts].append(arry[0]) #数据第一列,歌曲
else :
actsong[acts]=[arry[0]] #数据第二列,艺人
print "生成歌曲—艺人字典...ok"
print len(actsong) #长度应该是100
#生成歌曲—每天的操作和行数 {歌曲名:[(操作,时间)]}
for line in fu:
lis=line.split(",")
action=int(lis[3])
song=str(lis[1])
if action==1: #这里是判断操作数,要的是播放的操作
if song in user:
user[song].append((lis[3],lis[4]))#lis[3]是操作,4是时间,思想同上
else :
user[song]=[(lis[3],lis[4])]
else:
continue
#print user
print "生成歌曲—每天的操作和行数....ok"
print len(user)
#生成每首歌的统计结果
newlist={}#歌曲的统计字典
for linesong in user:
counts={} #临时计数字典
allshuju=user[linesong] #取出字典,user[linesong]是列表名,也是键
#print allshuju
for i in allshuju: #取元组的数据
j=list(i) #因为allshuju是一个列表,所以从第i个开始取
k=int(j[1]) #取第i个的元组的第二个数据,也就是时间
if k in counts: #思想同上,这次是直接计数了
counts[k]+=1
else:
counts[k]=1
newlist[linesong]=counts #生成新的字典,歌曲和每天统计的数据,字典套字典
#print newlist[linesong]
print "成每首歌的统计结果.....ok"
#生成每个艺人的总的统计结果
allactplay={} #总表
for oneact in actsong: #取艺人字典中一个艺人x
songlist=actsong[oneact] #取x的所有歌曲
timedisk={} #临时时间字典,最后要生成艺人时间播放量的数据
for song in newlist: #取歌曲统计中的歌曲名
if song in songlist: #如果取的歌曲在x的歌曲表中
for time1 in newlist[song]: #取时间,newlist[song]是歌曲之后对应的统计结果的字典,取字典的键值,时间
if time1 in timedisk: #将时间放入总表
timedisk[time1]+=newlist[song][time1] #newlist[song][time1]这个是歌曲字典->时间字典->到播放量
else:
timedisk[time1]=newlist[song][time1]
#print time1 是日期,timedisk[time1] 是这天的总播放量
#将所有x的歌曲的相同每天的播放量相加
else:
allactplay[oneact]=timedisk
print "生成每个艺人的总的统计结果.....ok"
#输出文件,类型为字典套字典的结构
for act1 in allactplay:
for play2 in allactplay[act1]:
fo.write(str(act1)+","+str(play2)+","+str(allactplay[act1][play2])+"\n")
print "输出文件.....ok"
end = time.clock()
print "read: %f s" % (end - start)
评估函数

代码
这里注意除法是不是地板除,还有列表的类型,从而保证不会取整
#!/usr/bin/python
# -*- coding: utf-8 -*-
import math
import numpy
f=open("7-8text.csv","rb")
ff=open("7-8.csv","rb")
dict1={}#预测结果集合
dict2={}#实际结果集合
list3=[]#单个艺人的总成绩
for line in f:
artplaytime=line.split(',')
art=str(artplaytime[0])
#play=int(artplaytime[1])
#time=int(artplaytime[2])
if art in dict1:
dict1[art].append((artplaytime[2],artplaytime[1]))
else:
dict1[art]=[]
print len(dict1)
for line1 in ff:
artplaytime1=line1.split(',')
art1=str(artplaytime1[0])
play1=int(artplaytime1[1])
time1=int(artplaytime1[2])
if art1 in dict2:
dict2[art1].append((artplaytime1[2],artplaytime1[1]))
else:
dict2[art1]=[]
print len(dict2)
for art in dict1:
list1=[]#方差归一化内部每天的计算结果
list2=[]#艺人j在的权重根据艺人的播放量平方根
for tuple1 in dict1[art]:#读取预测集中某一个歌手的所有数据
if art in dict2:
#判断歌手
for tuple2 in dict2[art]:#读取实际集中这一个歌手的所有数据
if tuple1[1]==tuple2[1]:#判断时间
a=int(tuple1[0])
b=int(tuple2[0])
count=float((float(float((a-b))/b))**2)
list1.append(count)
list2.append(int(tuple2[0]))
else:
continue
else:
continue
oneart=float((1-math.sqrt(float(sum(list1))/60)) *math.sqrt(float(sum(list2))))
list3.append(oneart)
result=sum(list3)
print result