二、预习
在我们进去device mapper的dm dedup学习之前,我们先要预习一下,什么是device mapper,和为什么device mapper能够做块重删。
1、device mapper
照旧,我们先看一下维基百科对它的介绍。
The device mapper is a framework provided by the Linux kernel for mapping physical block devices onto higher-level virtual block devices. It forms the foundation of the logical volume manager (LVM), software RAIDs and dm-crypt disk encryption, and offers additional features such as file system snapshots.
注1:这一段的意思就是说device mapper是我们linux系统中非常重要的LVM和软RAID还有加密、快照等特性的实现。
Device mapper works by passing data from a virtual block device, which is provided by the device mapper itself, to another block device. Data can be also modified in transition, which is performed, for example, in the case of device mapper providing disk encryption or simulation of unreliable hardware behavior.
注2:这一段的意思是说device mapper使用虚拟设备(dm-n)来提供与其他虚拟或者真实的块设备的数据传送,当然数据能够在其中改变(比如raid会增加冗余信息),也可以不改变(比如linear就是透传),或者就是更厉害的功能,加密等吧,可见这个device mapper一定可以是个常青树,什么和存储有关系的都可以用它实现。
我们大致了解的device mapper,我们还需要了解一下device mapper在linux I/O stack中的位置吧;
还是那个老图,我们尽量看看,顺便把其他的模块也讲解一下;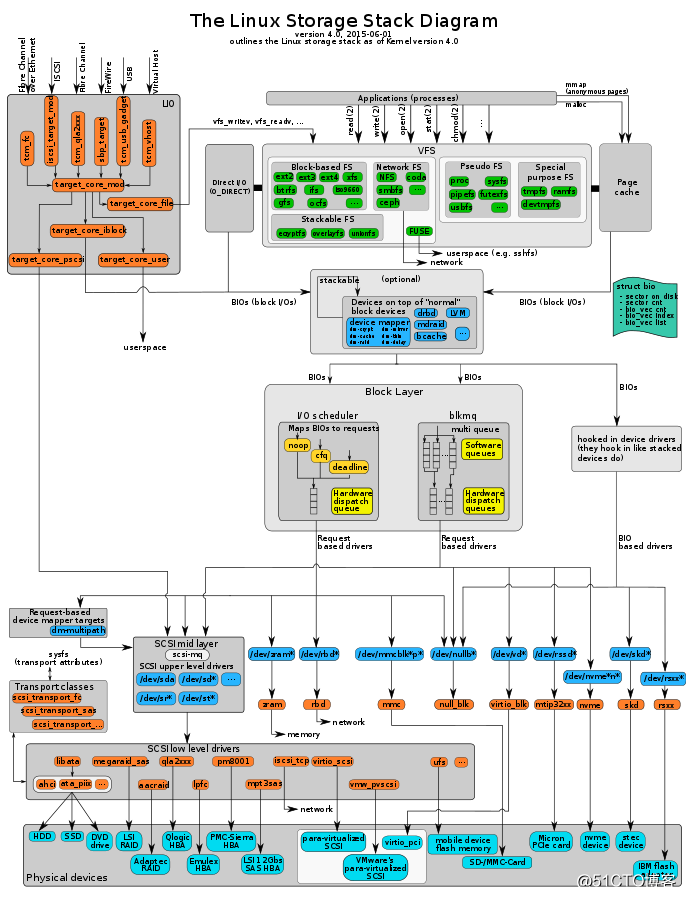
鉴于篇幅有限,我们就从上往下讲,因为本人从事linux I/O stack的研究已经有5年的时间,大概每个位置都是玩过的,但并非每个module都是专家,并且kernel I/O stack里面的存储的知识都非常的深,所以要入坑存储的同行的请三思啊。
ok,废话不多说,我们从最上层开始讲,这里只是概要性的分析,不涉及特别深。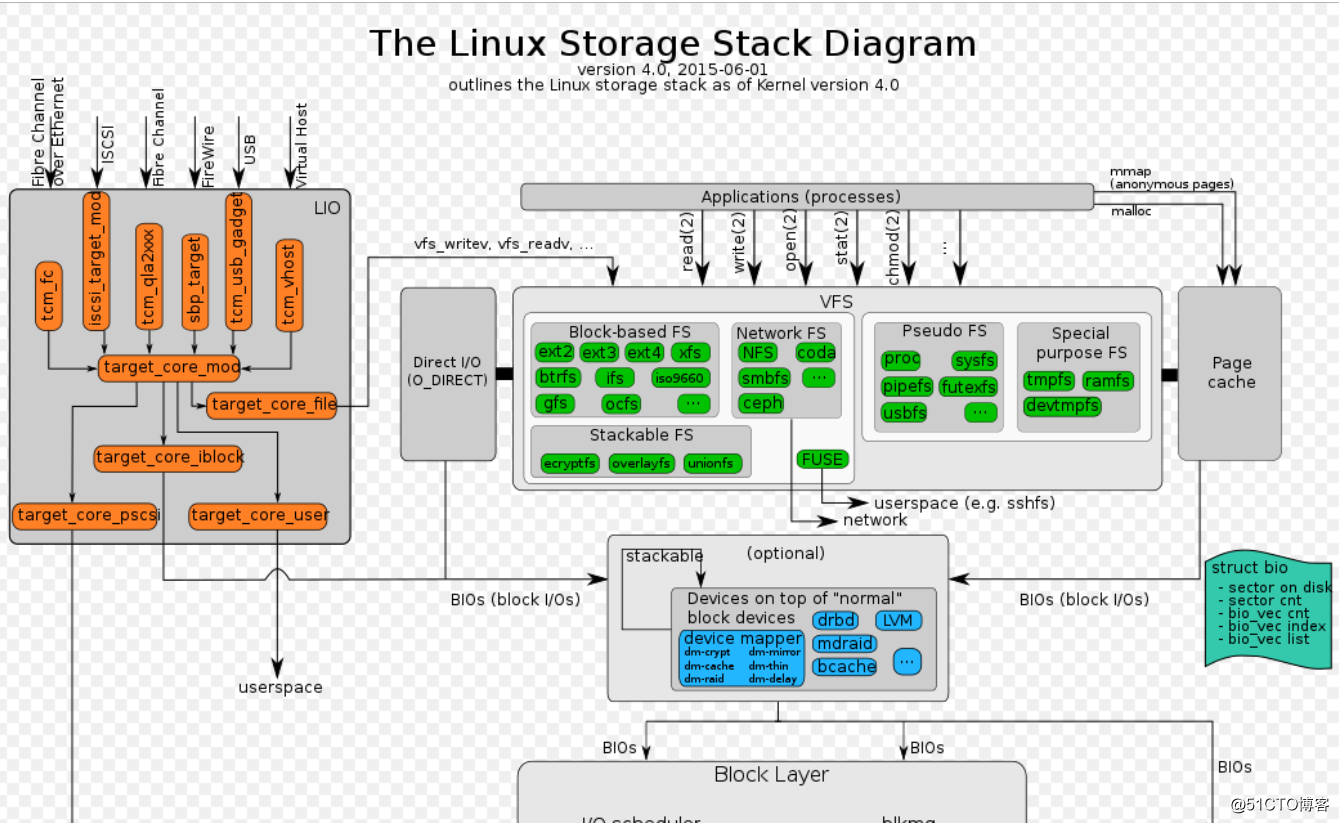
我把图截成上下两半,以block layer为分层。上面应该就是大概非常熟悉的三大块,LIO、虚拟块设备、VFS虚拟文件系统。
1、LIO(linux io target)
做传统SAN存储和分布式块存储的同学应该对LIO比较熟悉吧,至少都是听过的,早些年我们做iscsi或者fc存储的时候,那时候我们大多数用IET和SCST,后来随着linux kernel对LIO的逐步完善,目前LIO可以支持非常多种类的fabric和backcore。
fabric:tcm_fc(我觉得可能是用于emulex的光纤卡),iscsi_target_mod(是对接linux kernel网络协议栈)、tcm_qla2xxx(对接qlogic的光纤卡)、sbp_target(IEEE 1394),tcm_usb_target(做usb移动硬盘可以用上)等等吧,其中iscsi_target_mod可以被赋予infiniband的支持,会成为一个新的target为iser。
backcore:backcore简单来讲就是虚拟scsi lun的mod,它能够解析和仿真几乎常见的所有标准SCSI命令,让它看起来和SCSI DISK内的LUN一样。LIO能够提供几种backcore,core_file(通常是文件系统的某个文件,或者直接是将块设备作为文件导出),core_iblock(能够将linux块设备导出),pscsi(能够直接导出,比如直接导出/dev/sdb等)。
2、vfs(虚拟文件系统)
微微一笑,这里我不太懂,属于瞎写。
文件系统在linux中占有举足轻重的作用,他可能是用户和开发者最便捷能够访问资源的方式。
linux为用户开发了很多可操作的文件系统。大致有以下几种:
block-based fs:这类文件系统通常后端设备是一个或多个块设备,它们的实体是一个能够组织数据的表结构,通过查表(metadata)来实现文件描述符到块的映射访问,这能非常有效的进行我们日常所有的大部分工作和生活需求。我们比较常用的是ext2/3/4,xfs和btrfs等等。
Network fs:网络文件系统,他们的诞生是要去解决,block-based文件不能够有效共享文件而产生的。他们从本质上讲都是分布式的,因为文件可能被多个client使用,这种文件系统通常需要非常复杂的分布式协议作为支持,如我们最开始接触的NFS,从windows兼容的smb2fs,还有目前非常流行的ceph,目前来看ceph并非和它的前辈一样只能够作为NAS的导出协议,它能够提供新兴的存储接口对象存储和高效的块存储。
psedudo fs:伪文件系统。大家应该都会对/dev/sda这种块设备直接进行过dd等操作,从vfs来看,/dev/sda这种bdev也是一种伪文件系统,包括我们更加数据的/proc、/sys、/configfs等开发者经常用来变成使用的接口,他们的注册和使用都非常简单,能够高效的帮助我们完成各种系统功能的配置和查看。
special psedudo fs:这类特别伪文件系统,是非常重要的,我们经常会把/tmp和/var挂载为tmpfs,用来加速不需要持久化的信息,来提供运行速度。
大致说完了上面的两个LIO和vfs后,我们就需要来讲讲top block device,也就是可能被导出的block decive,在linux中,被LIO和VFS使用,等价于被mount,即使独占模式,保护块设备的访问安全。
top block device:也就是虚拟块设备,这个在linux 里主要就是咱们经常用的LVM drbd md-raid bcache和device mapper,它们就是在/drivers/md/下面,他们就是真正承上启下的块虚拟化模块,每个模块都是比较有意思。这些内容会在后续的文章中一一讲解。