二叉树查找算法
二叉查找树是先对待查找的数据进行生成树,确保树的左分支的值小于右分支的值,然后在就行和每个节点的父节点比较大小,查找最适合的范围。 这个算法的查找效率很高,但是如果使用这种查找方法要首先创建树。
原理:
二叉查找树(BinarySearch Tree,也叫二叉搜索树 BST,或称二叉排序树Binary Sort Tree)或者是一棵空树,或者是具有下列性质的二叉树:
1)若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2)若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3)任意节点的左、右子树也分别为二叉查找树;
4) 没有键值相等的节点(no duplicate nodes)。
BST 中实现查找元素:
根据BST的特性,对于每个节点:
- 如果目标值等于节点的值,则返回节点
- 如果目标值小于节点的值,则继续在左子树中搜索
- 如果目标值大于节点的值,则继续在右子树中搜索
在上面的二叉搜索树中搜索目标值为 4 的节点
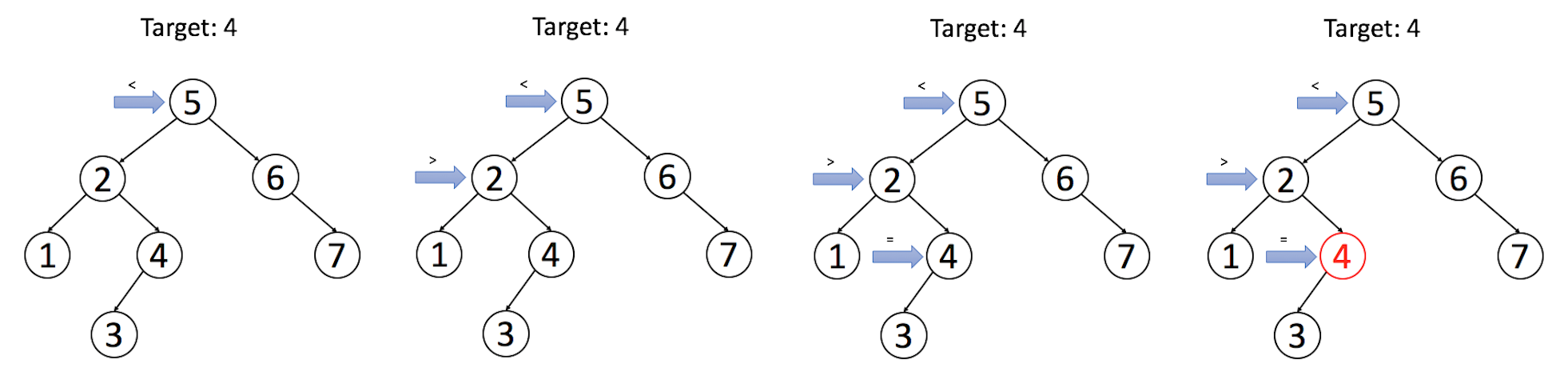
def search(self, node, parent, data):
if node is None:
return False, node, parent
if node.data == data:
return True, node, parent
if node.data > data:
return self.search(node.leftChild, node, data)
else:
return self.search(node.rightChild, node, data)BST 中实现插入元素:
与搜索操作类似,对于每个节点,我们将:
- 根据节点值与目标节点值的关系,搜索左子树或右子树;
- 重复步骤 1 直到到达外部节点;
- 根据节点的值与目标节点的值的关系,将新节点添加为其左侧或右侧的子节点。
| |

这样,我们就可以添加一个新的节点并依旧维持二叉搜索树的性质。
def insert(self, data):
flag, n, p = self.search(self.root, self.root, data)
if not flag:
new_node = BSTNode(data)
if data > p.data:
p.rightChild = new_node
else:
p.leftChild = new_nodeBST中实现删除操作:
删除要比我们前面提到过的两种操作复杂许多。有许多不同的删除节点的方法,根据其子节点的个数,我们需考虑以下三种情况:
1. 如果目标节点没有子节点,我们可以直接移除该目标节点。
2. 如果目标节只有一个子节点,我们可以用其子节点作为替换。
3. 如果目标节点有两个子节点,我们需要用其中序后继节点或者前驱节点来替换,再删除该目标节点。
例 1:目标节点没有子节点

例 2:目标节只有一个子节点

例 3:目标节点有两个子节点

def delete(self, root, data):
flag, n, p = self.search(root, root, data)
if flag is False:
return "关键字不存在,删除失败"
else:
if n.leftChild is None:
if n == p.leftChild:
p.leftChild = n.rightChild
else:
p.rightChild = n.rightChild
del p
elif n.rightChild is None:
if n == p.leftChild:
p.leftChild = n.leftChild
else:
p.rightChild = n.leftChild
del p
else: # 左右子树均不为空
pre = n.rightChild
if pre.leftChild is None:
n.data = pre.data
n.rightChild = pre.rightChild
del pre
else:
next = pre.leftChild
while next.leftChild is not None:
pre = next
next = next.leftChild
n.data = next.data
pre.leftChild = next.rightChild
del p代码分析:
class BSTNode:
def __init__(self, data):
self.data = data
self.leftChild = None
self.rightChild = None
class BST:
def __init__(self, node_list):
self.root = BSTNode(node_list[0])
for data in node_list[1:]:
self.insert(data)
def search(self, node, parent, data):
if node is None:
return False, node, parent
if node.data == data:
return True, node, parent
if node.data > data:
return self.search(node.leftChild, node, data)
else:
return self.search(node.rightChild, node, data)
def insert(self, data):
flag, n, p = self.search(self.root, self.root, data)
if not flag:
new_node = BSTNode(data)
if data > p.data:
p.rightChild = new_node
else:
p.leftChild = new_node
def delete(self, root, data):
flag, n, p = self.search(root, root, data)
if flag is False:
return "关键字不存在,删除失败"
else:
if n.leftChild is None:
if n == p.leftChild:
p.leftChild = n.rightChild
else:
p.rightChild = n.rightChild
del p
elif n.rightChild is None:
if n == p.leftChild:
p.leftChild = n.leftChild
else:
p.rightChild = n.leftChild
del p
else: # 左右子树均不为空
pre = n.rightChild
if pre.leftChild is None:
n.data = pre.data
n.rightChild = pre.rightChild
del pre
else:
next = pre.leftChild
while next.leftChild is not None:
pre = next
next = next.leftChild
n.data = next.data
pre.leftChild = next.rightChild
del p
# 先序遍历
def preOrderTraverse(self, node):
if node is not None:
print(node.data)
self.preOrderTraverse(node.leftChild)
self.preOrderTraverse(node.rightChild)
# 中序遍历
def inOrderTraverse(self, node):
if node is not None:
self.inOrderTraverse(node.leftChild)
print(node.data)
self.inOrderTraverse(node.rightChild)
# 后序遍历
def postOrderTraverse(self, node):
if node is not None:
self.postOrderTraverse(node.leftChild)
self.postOrderTraverse(node.rightChild)
print(node.data)性能总结:
- 二叉排序树以链式进行存储,保持了链接结构在插入和删除操作上的优点。
- 在极端情况下,查询次数为1,但最大操作次数不会超过树的深度。也就是说,二叉排序树的查找性能取决于二叉排序树的形状,也就引申出了后面的平衡二叉树。
- 给定一个元素集合,可以构造不同的二叉排序树,当它同时是一个完全二叉树的时候,查找的时间复杂度为O(log(n)),近似于二分查找。
- 当出现最极端的斜树时,其时间复杂度为O(n),等同于顺序查找,效果最差。