4 系统稳定性
系统上线后,可能会发生各种各样的运行问题。如依赖的应用宕机、程序bug、线程死锁、黑客攻击、负载过高等。发生了问题如何快速定位,如何最大程度地保证线上系统的稳定性,都是本章将要探讨的问题。
4.1 在线日志分析
在线日志分析是出现问题时最常用的问题分析方式。日志中包含了程序在遇到异常情况所打印的堆栈信息。通过异常堆栈可以定位到产生问题的代码行;通过访问IP和请求url参数,排查是否遭到攻击;通过应用的响应时间、垃圾回收,以及系统load来判断系统负载,是否需要增加机器;通过线程dump,判断是否死锁及线程阻塞的原因;通过GC日志,对系统代码和JVM内存参数进行优化,减少GC次数与stw时间,优化应用响应时间。
日志分析命令和脚本网上资料很多,不展开详述。
4.2 集群监控
成熟稳健的系统往往需要对集群运行时的各个指标进行收集,如系统的load,CPU利用率,I/O繁忙程度,网络traffic,内存利用率,应用心跳等,对这些信息就行实时监控,如发现异常情况能够第一时间通知到相应的开发和运维人员进行处理。
4.2.1 监控指标
Load
系统的load是指特定时间间隔内运行队列中的平均线程数。每个cpu的核都维护了一个运行队列,系统的load主要由运行队列来决定。假设一个CPU有8核,运行的应用程序启动了16个线程且都处于运行状态。在平均分配的情况下,每个CPU的运行队列中就有2个线程在运行。假设这种情况维护了1分钟,则这一分钟内系统的load就是2。Load值越大,意味着系统的CPU越繁忙,每个线程获取CPU时间的间隔也越大。一般来说CPU的活动线程数不大于3是正常的,大于5表示系统负载高。
使用uptime可以查看系统的load:
uptime命令可以查看服务器已经运行了多久,当前登录用户有多少,服务器在过去的1、5、15分钟的系统平均负载值。

CPU
在linux系统下, CPU的时间消耗主要在这几个方面,即用户进程、内核进程、中断处理、I/O等待、Nice时间、丢失时间、空闲等几个部分,而CPU的利用率则为这些时间所占总时间的百分比。通过top | grep Cpu命令可以查看CPU的消耗情况:

- 用户时间(us)表示CPU执行用户进程所占用的时间,通常情况下希望us的占比越高越好。
- 系统时间(sy)表示CPU在内核态所花费的时间,sy的占比较高通常意味着系统在某些方面设计的不合理,比如频繁的系统调用导致的用户态和内核态的频繁切换。
- Nice时间(ni)表示系统在调整进程优先级的时候所花费的时间。
- 空闲时间(id)表示系统处于空闲期,等待进程运行所占用的时间。
- 等待时间(wa)表示CPU在等待I/O操作所花费的时间,系统不应该花费大量的时间来进行等待。
- 硬件中断处理时间(hi)表示系统处理硬件中断所占用的时间。
- 软件中断处理时间(si)表示系统处理软件中断所占用的时间。
- 丢失时间(st)表示被强制等待虚拟CPU的时间。如果st占用较高,则表示当前虚拟机与该宿主上的其他虚拟机间的CPU征用较为频繁。
按1可以显示全部CPU的利用率。
其他监控指标有磁盘剩余空间,网络traffic,磁盘I/O,内存使用,qps,rt,GC等等,这里不详细讲述。这些指标都从不同角度反映了系统当前的运行情况。当然,在实际中不可能通过人工的方式一个个去分析,而是通过一些监控系统来统一监控和观察系统当前的运行情况,如APM(Application Performance Manager)工具PinPoint:
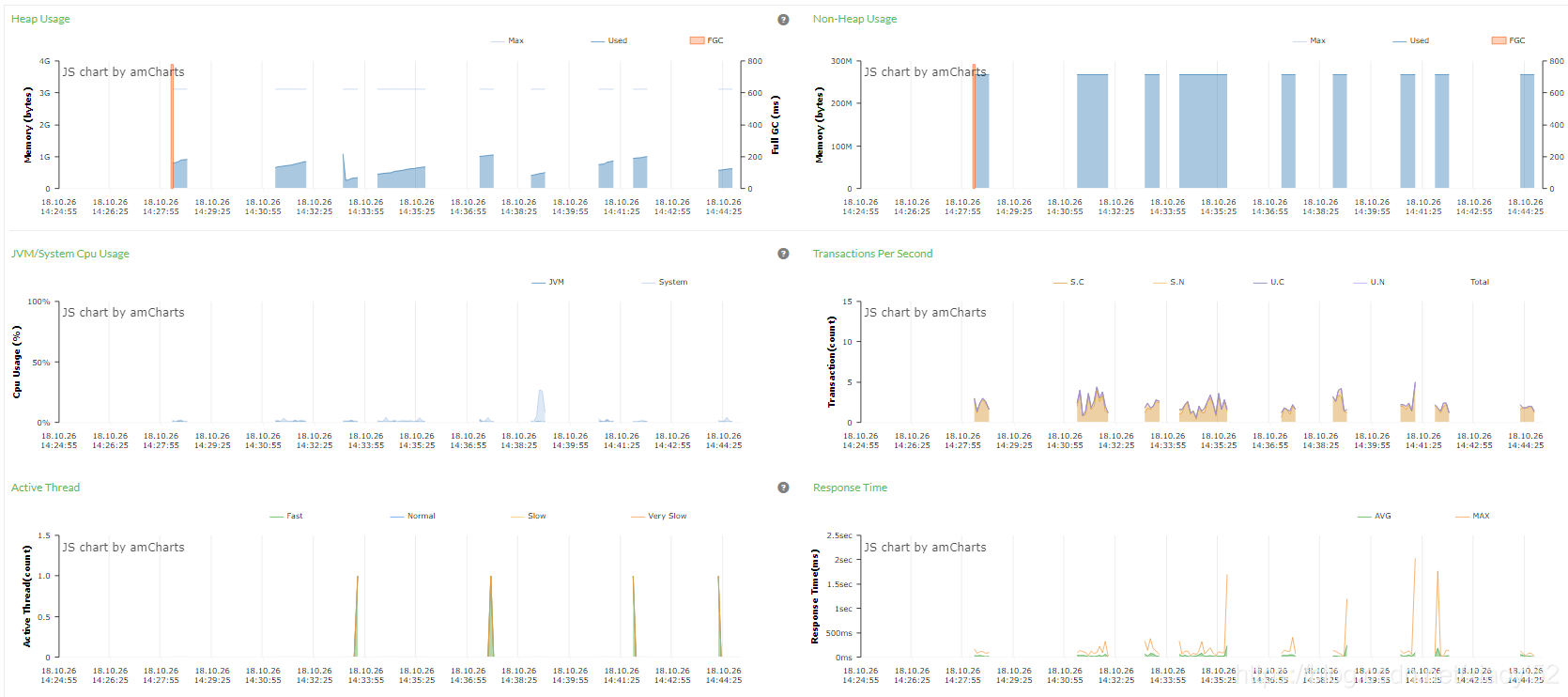
4.2.2 心跳检测
分布式系统一般都是以集群形式存在的,集群中任何一个节点出问题,都需要能够快速检测并且移除。因此对集群服务器和部署于其上的应用的心跳检测是必不可少的。
心跳检测有多重实现方案,作用除了用于检测节点故障之外,还可用于服务故障的检测。服务故障检测主要是针对业务层面的,可定期的发送一些无损的业务请求,以判断服务器是否正常提供服务。比如在博主的工作中,专门做了一个简单的心跳检测系统,通过定期调用其他业务系统的一些查询接口,来验证服务的可用性,以此达到心跳检测的目的。
4.3 流量控制
4.3.1 流量控制方式
任何系统都有承载上限,因此在分布式系统中,对超过上限的流量进行控制是必须的。流量控制可以从多个维度来进行,如对系统的总并发请求数进行限制,或者限制单位时间内的请求次数(如限制qps),或者通过白名单机制来限制接入系统调用的频率。不同的机制适应不同的场景。
对于超载的流量最简单的处理方式是直接丢弃,不进行任何处理直接返回,但会给用户带来糟糕的用户体验。

信号量/线程池
基于Java信号量实现流控的思路如下:
Semaphore semaphore = new Semaphore(INIT_SIZE);
...
// 请求处理
if (semaphore.getQueueLength() > 0) {
return;
}
try {
semaphore.acquire();
// 处理具体的业务逻辑
...
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
通过不断测试和调整,得到系统的承载上限,以此设置资源阈值INIT_SIZE。当流量在可控范围内,就获取信号量,并执行业务逻辑。否则就直接返回。
当然也可以设置等待队列大小,让一部分请求进行有限的等待。
也可以使用线程池,其思路跟使用信号量是一样的。
消息队列
流量控制的另一种方式是通过分布式消息队列来将用户的请求异步化,将请求的接收与业务逻辑处理解耦,当系统请求较多时,请求进入请求处理队列排队,前端用户不用等待系统处理完毕便能够得到相应。而后端系统能够以固定的频率来进行请求的处理,削峰填谷,不用担心瞬间流量过大被压垮。
当然在具体的场景中,对于流量控制实现方案有不同的选择。这里可参考博主的另一篇文章,讲了在实际工作场景中的一种流控实现方案-线程池处理高并发请求。
----未完待续。