如需转载请注明出处。
win10 64位、Python 3.6.3、Notepad++、Chrome 67.0.3396.99(正式版本)(64 位)
注:作者编写时间2018-05-02,linux、python 3.5.2
以下内容均是加入自己的理解与增删,以记录学习过程。不限于翻译,部分不完全照搬作者Miguel Grinberg的博客,版权属于作者,感谢他提供免费学习的资料。
本章将学习如何创建独立于Web服务器运行的后台工作。
本章致力于需要作为应用程序的一部分来运行的长或复杂进程的实现。这些进程不能在请求的上下文中同步执行,因为这会在任务期间阻止对客户端的响应。在第10章中简要介绍过这个主题,当时将电子邮件发送到后台线程,以防止客户端在发送电子邮件所需的3-4秒内等待。虽然可以使用线程来处理电子邮件,但是当有问题的进程更长时,此解决方案无法很好地扩展。公认的做法是"offload"长任务到一个工作进程或更可能是一个进程。
为了证明需要长时间运行任务,我将向Microblog引入一个导出功能,用户可以通过该功能请求包含所有博客帖子的数据文件。当用户使用此选项时,应用程序将启动导出任务,该任务将生成包含所有用户帖子的JSON文件,然后通过电子邮件将其发送给用户。所有这些活动都将在工作进程中发生,当它发生时,用户将看到显示完成百分比的通知。
任务队列简介
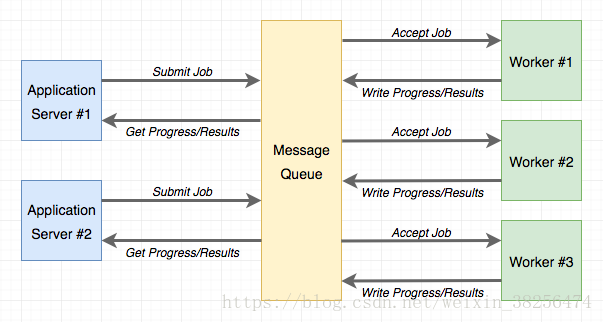
任务队列 为应用程序通过一个 工程进程(worker process)去请求一个执行任务提供了一个便捷的解决方案。应用程序 和工作程序(worker)之间的通信是通过消息队列完成的。应用程序提交作业,如果通过与队列交互来监视其进度。下图展示了典型的实现:
Python最受欢迎的任务队列(task queque)是Celery。这是一个相当复杂的包(库),有许多选项并支持多个消息队列。另一个流行的Python 任务队列 是Redis Queue(RQ),它牺牲了一些灵活性,如 只支持Redis添加链接描述消息队列,但它比Celery设置起来简单很多。
Celery和RQ 都很适合支持Flask应用程序中的后台任务,因此 对Microblog选择有简单优势的RQ。但是,与Celery实现相同的功能应该也不会太难。如果对Celery更感兴趣,可阅读 这篇作者博客文章。
使用RQ
RQ是一个标准的Python包,用pip 安装:(venv) D:\microblog>pip install rq
(venv) D:\microblog>pip freeze > requirements.txt
正如我之前提到的,应用程序和RQ工作程序(worker)之间的通信将在Redis消息队列中执行,因此需要运行Redis服务器。安装和运行Redis服务器有很多选择,从一键安装程序到下载源代码并直接在系统上编译。如果使用的是Windows,Microsoft会在此处维护安装程序。在Linux上,可以通过操作系统的软件包管理器将其作为软件包获取。Mac OS X用户可以运行brew install redis,然后使用redis-server命令手动启动服务。
除了确保服务正在运行并且RQ可访问之外,我们不需要与Redis进行交互。
请注意,RQ不能在Windows本机Python解释器上运行。如果使用的是Windows平台,则只能在Unix仿真下运行RQ。向Windows用户推荐的两个Unix仿真层是Cygwin和Windows的Linux子系统(WSL),两者都与RQ兼容。在此我不选择安装Cygwin(安装、操作有点麻烦!!我不熟悉)。这段是作者说的。
不过本人Win10选择WSL。步骤:
1,下载Redis,选择Redis-x64-3.2.100.zip,下载后解压。
2,打开第一个cmd窗口,进入Redis目录,如下:说明服务启动了

C:\Users\Administrator>d:
D:\>cd D:\Redis
D:\Redis>redis-server.exe redis.windows.conf
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 3.2.100 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 4624
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
[4624] 21 Sep 12:06:53.095 # Server started, Redis version 3.2.100
[4624] 21 Sep 12:06:53.096 * The server is now ready to accept connections on port 6379
[4624] 21 Sep 12:12:41.554 * 10 changes in 300 seconds. Saving...
[4624] 21 Sep 12:12:41.613 * Background saving started by pid 3528
[4624] 21 Sep 12:12:41.814 # fork operation complete
[4624] 21 Sep 12:12:41.815 * Background saving terminated with success
创建任务
接下来将展示如何通过RQ运行一个简单的任务,以便熟悉它。任务,只不过是一个Python函数。这是一个示例任务,我将放入一个新的app/tasks.py模块:
app/tasks.py:示例 后台任务
import time
def example(seconds):
print('Starting task')
for i in range(seconds):
print(i)
time.sleep(1)
print('Task completed')
这个任务需要几秒钟作为参数,然后等待那段时间,每秒打印一次计数器。
运行RQ Worker
现在任务已经准备就绪,一个worker就可以成为开始。这是通过rq worker命令完成的。打开第二个cmd窗口(PS:应该在WSL下运行rq worker命令。下方仅作示例),进入microblog虚拟目录下:
C:\WINDOWS\system32>d:
D:\>cd D:\microblog\venv\Scripts
D:\microblog\venv\Scripts>activate
(venv) D:\microblog\venv\Scripts>cd D:\microblog
(venv) D:\microblog>rq worker microblog-tasks
12:12:41 RQ worker 'rq:worker:Cchen-PC.14552' started, version 0.12.0
12:12:41 *** Listening on [32mmicroblog-tasks[39;49;00m...
12:12:41 Cleaning registries for queue: microblog-tasks
现在,工作进程已连接到Redis,并在名为microblog-tasks的队列中查看可能分配给它的任何作业。如果希望让多个工作程序具有更多吞吐量,则需要做的就是运行更多rq worker实例,所有实例都连接到同一队列。然后,当一个作业出现在队列中时,任何可用的工作进程都会将其提取出来。在生产环境中,可能希望至少拥有与可用CPU一样多的工作程序。
执行任务
现在打开 第三个cmd窗口,进入microblog虚拟目录后:(venv) D:\microblog>python
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from redis import Redis
>>> import rq
>>> queue = rq.Queue('microblog-tasks', connection=Redis.from_url('redis://'))
>>> job = queue.enqueue('app.tasks.example', 23)
>>> job.get_id()
'15b8ce12-c350-4b7d-a579-bb56484f189f'
RQ中的Queue类表示从应用程序端看到的任务队列。它所采用的参数是队列名称和Redis连接对象,在这种情况下,我使用默认URL进行初始化。如果你的Redis服务器在不同的主机或端口号上运行,则需要使用其他URL。
在队列上的enqueue()方法用于将作业添加到队列中。第一个参数是要执行的任务的名称,直接作为函数对象给出,或作为导入字符串。我发现字符串选项更方便,因为这使得不必在应用程序端导入该函数。给定给enqueue()的任何剩余参数将被传递给在worker中运行的函数。
一旦enqueue()调用执行,就会注意到第二个cmd窗口上的某些活动,即运行RQ worker的窗口。将看到example()函数正在运行,并且每秒打印一次计数器。
PS:一旦执行enqueue(),第二个cmd窗口将报错:
...
File "d:\microblog\venv\lib\site-packages\rq\worker.py", line 595, in fork_work_horse
child_pid = os.fork()
AttributeError: module 'os' has no attribute 'fork'
原因:是没有在Linux仿真层下运行rq worker命令。
解决方案:
1,参考文章安装WSL。
2,在ubuntu终端,更新软件源:避免安装包时报错(E:Unable to locate package xxx)
sudo apt-get update
3,安装python3-pip,过程有点慢,静心等待。
sudo apt-get install python3-pip
4,安装rq(R,Redis;Q,Queue。rq通过Redis和Queue实现分布式,分别实现Master和Worker,通过Redis存储任务队列)
sudo pip3 install rq
5,设置环境环境:
export FLASK_APP=microblog.py
6,运行rq worker命令
rq worker microblog-tasks
不过会报错:原因应该是未进入应用程序Microblog所属的Python虚拟环境中 执行rq worker命令。这就是Win10系统下操作的弊端!!【早知如此,一开始就应该在Win10下安装子系统Linux,并一直在Linux下操作】。而此时的解决办法是:在子系统Ubuntu下安装和Win10一样的虚拟环境(各种python库)。

同时,第三个cmd终端未被阻止,可以继续在shell中运行上述剩余的表达式。在上述示例中,调用job.get_id()方法来获取分配给任务的唯一标识符。您可以尝试使用这个job对象的另一个有趣的表达式是检查worker上的函数是否已完成:
>>> job.is_finished
False
如果通过了像上述例中所做的23,那么函数将运行大约23秒。在那之后,job.is_finished表达式将成为True。这不是很酷吗?我真的很喜欢RQ的简洁性。
函数完成后,worker会返回等待新作业,因此如果想要进行更多实验,可以使用不同的参数重复调用enqueue()。存储在队列中的有关任务的数据将在那里停留一段时间(默认为500秒),但最终将被删除。这很重要,任务队列不会保留已执行作业的历史记录。
报告任务进度
上一小节使用的示例任务非常简单。通常,对于长时间运行的任务,得需要某种进度信息可供应用程序使用,而这些信息又可以向用户显示。RQ通过使用job对象的meta属性来支持此功能。重写example()编写进度报告的任务:
app/tasks.py:带进度的示例后台任务
import time
from rq import get_current_job
def example(seconds):
job = get_current_job()
print('Starting task')
for i in range(seconds):
job.meta['progress'] = 100.0 * i / seconds
job.save_meta()
print(i)
time.sleep(1)
job.meta['progress'] = 100
job.save_meta()
print('Task completed')
这个新版example()使用RQ的get_current_job()函数来获取作业实例,这类似于提交任务时返回给应用程序的实例。job对象的meta属性是一个字典,其中任务可以写入要与应用程序通信的任何自定义数据。在这个例子中,编写一个表示任务完成百分比的progress项目。每次更新进度时,都会调用job.save_meta()指示RQ将数据写入Redis,应用程序可以在其中找到它。
在应用程序端(当前只是一个Python shell),我可以运行此任务,然后按如下方式监视进度:
>>> job = queue.enqueue('app.tasks.example', 23)
>>> job.meta
{}
>>> job.refresh()
>>> job.meta
{'progress': 13.043478260869565}
>>> job.refresh()
>>> job.meta
{'progress': 69.56521739130434}
>>> job.refresh()
>>> job.meta
{'progress': 100}
>>> job.is_finished
True
如上所见,在这一侧,meta属性可供阅读。需要调用方法refresh()以从Redis更新内容。
任务的数据库表示
对于上面的示例,它足以启动任务并观察它的运行。对于Web应用程序,事情会变得复杂一些,因为一旦这些任务中的一个作为请求的一部分启动,该请求就会结束,并且该任务的所有上下文都将丢失。因为我希望应用程序跟踪每个用户正在运行的任务,所以我需要使用数据库表来维护某些状态。下方将看到新Task模型的实现:
app/models.py:Task模型
# ...
import redis
import rq
class User(UserMixin, db.Model):
# ...
tasks = db.relationship('Task', backref='user', lazy='dynamic')
# ...
class Task(db.Model):
id = db.Column(db.String(36), primary_key=True)
name = db.Column(db.String(128), index=True)
description = db.Column(db.String(128))
user_id = db.Column(db.Integer, db.ForeignKey('user.id'))
complete = db.Column(db.Boolean, default=False)
def get_rq_job(self):
try:
rq_job = rq.job.Job.fetch(self.id, connection=current_app.redis)
except (redis.exceptions.RedisError, rq.exceptions.NoSuchJobError):
return None
return rq_job
def get_progress(self):
job = self.get_rq_job()
return job.meta.get('progress', 0) if job is not None else 100
此模型与之前模型之间的一个有趣区别是主键字段id是字符串,而不是整数。这是因为对于这个模型,我不会依赖数据库自己的主键生成,而是我将使用RQ生成的job标识符。
该模型将存储任务的完全限定名称(传递给RQ),适合向用户显示的任务的描述,与请求任务的用户的关系,以及指示任务是否完成的布尔值。complete字段的目的是将结束的任务与正在运行的任务分开,因为正在运行的任务需要特殊处理才能显示进度更新。
get_rq_job()方法是一个辅助方法,它从给定的任务ID 加载RQ Job实例,我可从模型中获取。这样做是为了从Redis中存在的数据Job.fetch()加载Job实例。get_progress()方法建立在顶部的get_rq_job()上,并返回该任务的进度百分比。这种方法有几个有趣的假设。如果RQ队列中不存在模型中的job ID,则表示job已完成且数据已过期并已从队列中删除,因此在这种情况下返回的百分比为100。另一方面,如果job存在,但没有相关的信息meta 属性,那么可以安全地假设job被安排运行,但是还没有机会启动,所以在这种情况下,返回0作为进度。
要将更改应用于数据库模式,需要生成新的迁移,然后升级数据库:
(venv) D:\microblog>flask db migrate -m "tasks"
[2018-09-21 20:15:20,249] INFO in __init__: Microblog startup
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'task'
INFO [alembic.autogenerate.compare] Detected added index 'ix_task_name' on '['name']'
Generating D:\microblog\migrations\versions\673ce4638afc_tasks.py ... done
(venv) D:\microblog>flask db upgrade
[2018-09-21 20:15:34,132] INFO in __init__: Microblog startup
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade 6f999203a2b1 -> 673ce4638afc, tasks
新模型也可以添加到shell上下文中,以便在shell会话中访问它而无需导入它:
microblog/microblog.py:将任务模型添加到shell上下文
from app import create_app, db, cli
from app.models import User, Post, Message, Notification, Task
app = create_app()
cli.register(app)
@app.shell_context_processor
def make_shell_context():
return {'db': db, 'User': User, 'Post': Post, 'Message': Message,
'Notification': Notification, 'Task': Task}
将RQ与Flask应用程序集成
需要将Redis服务的连接URL添加到配置中: microblog/config.py:# ...
class Config(object):
# ...
ELASTICSEARCH_URL = os.environ.get('ELASTICSEARCH_URL')
REDIS_URL = os.environ.get('REDIS_URL') or 'redis://'
# ...
与往常一样,Redis连接URL将来自环境变量,如果未定义该变量,则将使用假定服务在同一主机和默认端口上运行的默认URL。
应用程序的工厂函数将负责初始化Redis和RQ:
app/__init__.py:RQ集成
# ...
from redis import Redis
import rq
from config import Config
# ...
def create_app(config_class=Config):
# ...
app.elasticsearch = Elasticsearch([app.config['ELASTICSEARCH_URL']]) if app.config['ELASTICSEARCH_URL'] else None
app.redis = Redis.from_url(app.config['REDIS_URL'])
app.task_queue = rq.Queue('microblog-tasks', connection=app.redis)
# ...
app.task_queue会将是其中任务提交队列中。将队列连接到应用程序很方便,因为我可以使用current_app.task_queue在应用程序中的任何位置来访问它。为了使应用程序的任何部分能够轻松提交或检查任务,我可以在User模型中创建一些辅助方法:
app/models.py:用户模型中的任务帮助程序方法
# ...
class User(UserMixin, db.Model):
# ...
def add_notification(self, name, data):
# ...
def launch_task(self, name, description, *args, **kwargs):
rq_job = current_app.task_queue.enqueue('app.tasks.' + name, self.id,
*args, **kwargs)
task = Task(id=rq_job.get_id(), name=name, description=description,
user=self)
db.session.add(task)
return task
def get_tasks_in_progress(self):
return Task.query.filter_by(user=self, complete=False).all()
def get_task_in_progress(self, name):
return Task.query.filter_by(name=name, user=self,
complete=False).first()
# ...
launch_task()方法负责将任务提交到RQ队列,并将其添加到数据库。name参数是函数名,如在限定的app/tasks.py。提交到RQ时,该函数会以此名称app.tasks.为前缀,以构建完全限定的函数名称。description参数是对可以呈现给用户的任务的友好描述。对于导出博客帖子的函数,我将设置名称export_posts和描述Exporting posts...。其余参数是将传递给任务的位置和关键字参数。该函数首先调用队列的enqueue()方法来提交作业。返回的job对象包含RQ分配的任务ID,因此我可以使用它来创建相应的数据库中的Task对象。
请注意,launch_task()将新任务对象添加到会话中,但不会发出提交。通常,最好在更高级别的函数中操作数据库会话,因为这允许我们在单个事务中组合由较低级别函数进行的多个更新。这不是一个严格的规则,实际上,将看到一个异常,其中在本章后面的子函数中发出了提交。
get_tasks_in_progress()方法返回用户未完成的功能的完整列表。稍后将看到我使用此方法包含有关在呈现给用户的页面中运行任务的信息。
最后,get_task_in_progress()是前一个返回特定任务的简单版本。阻止用户同时启动两个或多个相同类型的任务,因此在启动任务之前,可以使用此方法来确定以前的任务当前是否正在运行。
从RQ任务发送电子邮件
这可能看起来像是对主题的干扰,但在上面说过,当后台导出任务完成时,将使用包含所有帖子的JSON文件向用户发送电子邮件。在第11章中构建的电子邮件功能需要以两种方式进行扩展。首先,需要添加对文件附件的支持,以便我可以附加JSON文件。其次,send_email()函数始终使用后台线程异步发送电子邮件。当我要从后台任务发送一封已经异步的电子邮件时,基于线程的二级后台任务没什么意义,所以需要支持同步和异步电子邮件发送。
幸运的是,Flask-Mail支持附件,所以我需要做的就是扩展send_email()函数以将它们带入另一个参数,然后在Message对象中配置它们。并且可选地在前台发送电子邮件,我只需要添加一个布尔sync参数:
app/email.py:发送带附件的电子邮件
# ...
def send_email(subject, sender, recipients, text_body, html_body,
attachments=None, sync=False):
msg = Message(subject, sender=sender, recipients=recipients)
msg.body = text_body
msg.html = html_body
if attachments:
for attachment in attachments:
msg.attach(*attachment)
if sync:
mail.send(msg)
else:
Thread(target=send_async_email,
args=(current_app._get_current_object(), msg)).start()
Message类的attach()方法接受三个定义附件的参数:文件名,媒体类型和实际文件数据。文件名只是收件人将看到与附件关联的名称,它不需要是真实文件。媒体类型定义了这种附件的类型,这有助于电子邮件阅读器适当地呈现它。例如,如果作为媒体类型发送image/png,电子邮件阅读器将知道附件是图像,在这种情况下,它可以显示它。对于博客帖子数据文件,我将使用JSON格式,它使用application/json媒体类型。第三个和最后一个参数是带有附件内容的字符串或字节序列。
为简单起见,attachments参数给send_email()的将是一个元组列表,每个元组将有三个元素对应于attach()的三个参数。因此,对于此列表中的每个元素,我需要将元组作为参数发送给attach()。在Python中,如果有一个包含要发送给函数的参数的列表或元组,则可以使用func(*args)去拥有,该列表扩展到实际参数列表中,而不必使用更繁琐的语法,例如func(args[0], args[1], args[2])。例如,如果你有args = [1, 'foo'],那么调用将发送两个参数,就像调用一样func(1, 'foo')。没有*,调用将有一个参数列表。
至于同步发送电子邮件,当sync是True时,我需要做的只是直接恢复到调用mail.send(msg)。
任务助手
虽然我上面使用的example()任务是一个简单的独立函数,但导出博客帖子的功能将需要我在应用程序中使用的一些功能,如访问数据库和电子邮件发送功能。因为这将在一个单独的进程中运行,所以我需要初始化Flask-SQLAlchemy和Flask-Mail,而Flask-SQLAlchemy和Flask-Mail又需要一个Flask应用程序实例来从中获取它们的配置。所以要在app/tasks.py模块的顶部添加一个Flask应用程序实例和应用程序上下文:
app/tasks.py:创建应用程序和上下文
import time
from rq import get_current_job
from app import create_app
app = create_app()
app.app_context().push()
# ...
应用程序在此模块中创建,因为这是RQ worker工作程序要导入的唯一模块。当使用flask命令时,根目录中的microblog.py模块会创建应用程序,但RQ工作程序对此一无所知,因此如果任务函数需要它,则需要创建自己的应用程序实例。已经在几个地方看过app.app_context()方法,推送上下文使应用程序成为“current”应用程序实例,这使得Flask-SQLAlchemy等扩展可用于current_app.config获取其配置。如果没有上下文,current_app表达式将返回错误。
然后我开始思考在这个函数运行时我将如何报告进度。除了通过job.meta字典传递进度信息之外,我还想将通知推送到客户端,以便可以动态更新完成百分比,而无需用户刷新页面。为此,我将使用第21章中构建的通知机制。更新将以与未读邮件徽章非常相似的方式工作。当服务器呈现模板时,它将包含从job.meta中获取的“static”进度信息,但是一旦页面在客户端的浏览器上,通知将使用通知动态更新百分比。由于通知,更新正在运行的任务的进度将比我在上一个示例中所做的更为复杂,因此我将创建一个专用于更新进度的包装函数:
app/tasks.py:设置任务进度
from rq import get_current_job
from app import db
from app.models import Task
# ...
def _set_task_progress(progress):
job = get_current_job()
if job:
job.meta['progress'] = progress
job.save_meta()
task = Task.query.get(job.get_id())
task.user.add_notification('task_progress', {'task_id': job.get_id(),
'progress': progress})
if progress >= 100:
task.complete = True
db.session.commit()
导出任务可以调用_set_task_progress()以记录进度百分比。该函数首先将百分比写入job.meta字典并将其保存到Redis,然后从数据库加载相应的任务对象,并使用现有add_notification()方法将通知task.user推送到请求任务的用户。通知将被命名task_progress,与之关联的数据将成为包含两个项目的字典,即任务标识符和进度编号。稍后我会添加JavaScript代码来处理这种新的通知类型。
该函数检查进度是否表明函数已完成,并且在这种情况下还会更新数据库中任务对象的complete属性。数据库提交调用add_notification()确保添加的任务和通知对象都立即保存到数据库。我需要非常小心我如何设计父任务以不进行任何数据库更改,因为此提交调用也会编写这些更改。
实施导出任务
现在所有的部分都可以让我编写导出功能。该函数的高级结构如下:
app/tasks.py:导出帖子的一般结构
def export_posts(user_id):
try:
# read user posts from database
# send email with data to user
except:
# handle unexpected errors
为什么要将整个任务包装在try/except块中?存在于请求处理程序中的应用程序代码受到保护,以防止意外错误,因为Flask本身捕获异常,然后处理它们,观察为应用程序设置的任何错误处理程序和日志记录配置。但是,此函数将在由RQ控制的单独进程中运行,而不是Flask,因此如果发生任何意外错误,任务将中止,RQ将向控制台显示错误,然后将返回等待新工作。所以基本上,除非正在观察RQ工作器的输出或将其记录到文件中,否则您将永远不会发现存在错误。
让我们开始查看上面注释中指出的三个部分,最简单的部分是最后的错误处理:
app/tasks.py:导出帖子错误处理
import sys
# ...
def export_posts(user_id):
try:
# ...
except:
_set_task_progress(100)
app.logger.error('Unhandled exception', exc_info=sys.exc_info())
每当发生意外错误时,我将通过将进度设置为100%将任务标记为已完成,然后使用Flask应用程序中的记录器对象记录错误以及堆栈跟踪,信息是由调用sys.exc_info()提供的。使用Flask应用程序记录器来记录错误的好处是,将观察到为Flask应用程序实现的任何日志记录机制。例如,在第7章中,我将错误配置发送到管理员电子邮件地址。只是通过使用app.logger也得到了这些错误的行为。
接下来,我将编写实际的导出代码,它只是发出一个数据库查询并在循环中遍历结果,并将它们累积在字典中:
app/tasks.py:从数据库中读取用户帖子
import time
from app.models import User, Post
# ...
def export_posts(user_id):
try:
user = User.query.get(user_id)
_set_task_progress(0)
data = []
i = 0
total_posts = user.posts.count()
for post in user.posts.order_by(Post.timestamp.asc()):
data.append({'body': post.body,
'timestamp': post.timestamp.isoformat() + 'Z'})
time.sleep(5)
i += 1
_set_task_progress(100 * i // total_posts)
# send email with data to user
except:
# ...
对于每个帖子,该函数将包括一个包含两个元素的字典,帖子正文和帖子写入的时间。时间将以ISO 8601标准编写。我正在使用的Python datetime对象不存储时区,因此在以ISO格式导出时间之后,我添加“Z”,表示UTC。
由于需要跟踪进度,代码稍微复杂一些。我维护计数器i,我需要在进入循环之前发出额外的数据库查询total_posts以获得帖子数量。使用i和total_posts,每次循环迭代可以使用0到100之间的数字更新任务进度。
可能已经注意到我还在每次循环迭代中添加了一个调用time.sleep(5)。我添加休眠的主要原因是使导出任务持续更长时间,并且即使导出仅包含少量博客帖子,也可以看到进度上升。
可以在下面看到该功能的最后一部分,该部分向用户发送一封电子邮件,其中包含作为附件收集在data的所有信息:
app/tasks.py:将帖子发送给用户
import json
from flask import render_template
from app.email import send_email
# ...
def export_posts(user_id):
try:
# ...
_set_task_progress(100 * i // total_posts)
send_email('[Microblog] Your blog posts',
sender=app.config['ADMINS'][0], recipients=[user.email],
text_body=render_template('email/export_posts.txt', user=user),
html_body=render_template('email/export_posts.html', user=user),
attachments=[('posts.json', 'application/json',
json.dumps({'posts': data}, indent=4))],
sync=True)
except:
# ...
这只是对send_email()函数的调用。附件被定义为具有三个元素的元组,然后传递给Flask-Mail Message对象的attach()方法。元组中的第三个元素是附件内容,它是使用Python的json.dumps()函数生成的。
这里引用了一对新模板,它们以纯文本和HTML格式提供电子邮件正文的内容。这是文本模板:
app/templates/email/export_posts.txt:导出帖子文本电子邮件模板
Dear {{ user.username }},
Please find attached the archive of your posts that you requested.
Sincerely,
The Microblog Team
这是电子邮件的HTML版本:
app/templates/email/export_posts.html:导出帖子HTML电子邮件模板
<p>Dear {{ user.username }},</p>
<p>Please find attached the archive of your posts that you requested.</p>
<p>Sincerely,</p>
<p>The Microblog Team</p>
应用程序中的导出功能
现在支持后台导出任务的所有核心部分都已到位。剩下的就是将此功能与应用程序连接起来,以便用户可以通过电子邮件将请求发送给他们。下面你可以看到一个新的export_posts视图函数:
app/main/routes.py:导出帖子路由和查看功能
@bp.route('/export_posts')
@login_required
def export_posts():
if current_user.get_task_in_progress('export_posts'):
flash(_('An export task is currently in progress'))
else:
current_user.launch_task('export_posts', _('Exporting posts...'))
db.session.commit()
return redirect(url_for('main.user', username=current_user.username))
该函数首先检查用户是否具有未完成的导出任务,并且在这种情况下只是闪烁消息。同一个用户同时拥有两个导出任务是没有意义的,所以这是可以避免的。我可以使用get_task_in_progress()之前实现的方法检查这种情况。
如果用户尚未运行导出,则调用launch_task()以启动导出。第一个参数是将传递给RQ worker的函数的名称,前缀为app.tasks.。第二个参数只是一个友好的文本描述,将显示给用户。这两个值都写入数据库中的Task对象。该函数以重定向到用户配置文件页面结束。
现在我需要公开这条路线的链接,用户可以访问该链接以请求导出。我认为最合适的地方是在用户个人资料页面中,只有在用户查看自己的页面时才能显示该链接,就在“Edit your profile”链接下方:
app/templates/user.html:在用户个人资料页面中导出链接
...
<p>
<a href="{{ url_for('main.edit_profile') }}">
{{ _('Edit your profile') }}
</a>
</p>
{% if not current_user.get_task_in_progress('export_posts') %}
<p>
<a href="{{ url_for('main.export_posts') }}">
{{ _('Export your posts') }}
</a>
</p>
...
{% endif %}
此链接与条件绑定,因为我不希望在用户已经进行导出时显示该链接。
此时,后台作业应该起作用,但不向用户提供任何反馈。如果想尝试这个,可以按如下方式启动应用程序和RQ工作程序:
- 确保Redis正在运行
- 在第一终端窗口中,启动RQ工作器的一个或多个实例。为此,必须使用
rq worker microblog-tasks命令 - 在第二个终端窗口中,启动Flask应用程序
flask run(记住先设置FLASK_APP)
进度通知
要结束此功能,我想在后台任务运行时通知用户,包括完成百分比。在查看Bootstrap组件选项时,我决定在导航栏下方使用警报。警报是这些颜色水平条,它向用户显示信息。蓝色警报框是我用来渲染闪烁消息的方法。现在我要添加一个绿色的来显示进度状态。可以在下面看到它的外观:
app/templates/base.html:在基础模板中导出进度警报

...
{% block content %}
<div class="container">
{% if current_user.is_authenticated %}
{% with tasks = current_user.get_tasks_in_progress() %}
{% if tasks %}
{% for task in tasks %}
<div class="alert alert-success" role="alert">
{{ task.description }}
<span id="{{ task.id }}-progress">{{ task.get_progress() }}</span>%
</div>
{% endfor %}
{% endif %}
{% endwith %}
{% endif %}
{% with messages = get_flashed_messages() %}
...
...
{% endblock %}
...
呈现任务警报的方法几乎与闪烁消息相同。当用户未登录时,外部条件跳过所有与警报相关的标记。对于登录用户,我通过调用我之前创建的get_tasks_in_progress()方法获取当前正在进行的任务列表。在当前版本的应用程序中,我最多只能获得一个结果,因为我一次不允许多个活动导出,但将来我可能希望支持可以共存的其他类型的任务,所以以通用的方式写这个可以节省我的时间。
对于每个任务,我都会向页面写一个警报元素。警报的颜色由第二种CSS样式控制,在这种情况alert-success下,在闪烁消息的情况下是alert-info。该引导文件包括在HTML结构警报的细节。警报文本包括存储在Task模型中的description字段,后跟完成百分比。
百分比包含在具有id属性的<span>元素中。这样做的原因是我将在收到通知时刷新JavaScript的百分比。我用于给定任务的id被构造为-progress在末尾附加的任务id 。当通知到达时,它将包含任务ID,因此为#<task.id>-progress我可以轻松找到要使用选择器更新的正确<span>元素。
如果此时尝试应用程序,则每次导航到新页面时都会看到“static”进度更新。将注意到,在启动导出任务后,可以自由导航到应用程序的不同页面,并始终调用正在运行的任务的状态。
为了准备对百分比<span>元素应用动态更新,我将在JavaScript端编写一个小帮助函数:
app/templates/base.html:Helper函数,用于动态更新任务进度
...
{% block scripts %}
...
<script>
...
function set_message_count(n) {
$('#message_count').text(n);
$('#message_count').css('visibility', n ? 'visible' : 'hidden');
}
function set_task_progress(task_id, progress) {
$('#' + task_id + '-progress').text(progress);
}
...
</script>
...
{% endblock %}
此函数接受任务id和进度值,并使用jQuery定位此任务的<span>元素,并将新进度写为其内容。实际上没有必要验证页面上是否存在元素,因为如果没有元素与给定的选择器一起定位,jQuery将不会执行任何操作。
通知已经到达浏览器,因为每次更新进度时app/tasks.py中的_set_task_progress()函数都会调用add_notification()。如果对这些通知如何到达浏览器感到困惑而没有我不得不做任何事情,那真的是因为在第21章我明智地以完全通用的方式实现通知功能。当浏览器定期向服务器请求通知更新时,浏览器将看到通过add_notification()方法添加的任何通知。
但是处理这些通知的JavaScript代码只识别那些具有unread_message_count名称的代码,而忽略其余的代码。我现在需要做的是扩展该函数以task_progress通过调用上面定义的set_task_progress()函数来处理通知。以下是处理来自JavaScript的通知的循环的更新版本:
app/templates/base.html:通知处理程序
for (var i = 0; i < notifications.length; i++) {
switch (notifications[i].name) {
case 'unread_message_count':
set_message_count(notifications[i].data);
break;
case 'task_progress':
set_task_progress(
notifications[i].data.task_id,
notifications[i].data.progress);
break;
}
since = notifications[i].timestamp;
}
现在我需要处理两个不同的通知,我决定用一个if语句替换检查unread_message_count通知名称的switch语句,该语句包含我现在需要支持的每个通知的一个部分。如果不熟悉“C”系列语言,可能以前没有看过switch语句。这些提供了一种替代长链if/elseif语句的方便语法。这很好,因为我需要支持更多通知,我可以简单地将它们作为附加case块添加。
如果还记得,那RQ任务附加到数据task_progress的通知是一个有两个元素,一个字典task_id和progress,这是两个参数,我需要用它来调用set_task_progress()。
如果现在运行该应用程序,绿色警报框中的进度指示器将每隔10秒刷新一次,因为通知将传递到客户端。
因为我在本章中介绍了新的可翻译字符串,所以需要更新翻译文件。如果您要维护非英语语言文件,则需要使用Flask-Babel刷新翻译文件,然后添加新翻译:
(venv) D:\microblog>flask translate update
翻译完成后,必须编译翻译文件:
(venv) D:\microblog>flask translate compile
部署注意事项
为了完成本章,我想讨论如何更改应用程序的部署。为了支持后台任务,我在堆栈中添加了两个新组件,一个Redis服务器和一个或多个RQ worker。显然,这些需要包含在我们的部署策略中,因此我将简要介绍前面章节中介绍的不同部署选项以及它们如何受这些更改的影响。
在Linux服务器上部署
如果在Linux服务器上运行应用程序,则添加Redis应该与从操作系统安装此软件包一样简单。对于Ubuntu Linux,你必须运行sudo apt-get install redis-server。
要运行RQ工作进程,可以按照第17章中的“设置Gunicorn和Supervisor”一节创建第二个Supervisor配置,而不是在gunicorn中运行rq worker microblog-tasks。如果要运行多个工作程序(并且可能应该用于生产),可以使用Supervisor numprocs指令指示要同时运行的实例数。
在Heroku上部署
要在Heroku上部署应用程序,需要为帐户添加Redis服务。这类似于我用来添加Postgres数据库的过程。Redis还有一个免费套餐,可以使用以下命令添加:
$ heroku addons:create heroku-redis:hobby-dev
新redis服务的访问URL将作为REDIS_URL变量添加到Heroku环境中,这正是应用程序所期望的。
Heroku中的免费计划允许一个web dyno和一个worker dyno,因此您可以rq在应用程序的同时容纳一名工作人员,而不会产生任何费用。为此,您需要在procfile中的单独行中声明worker:
web: flask db upgrade; flask translate compile; gunicorn microblog:app
worker: rq worker -u $REDIS_URL microblog-tasks
使用这些更改进行部署后,可以使用以下命令启动worker:
$ heroku ps:scale worker=1
在Docker上部署
如果要将应用程序部署到Docker容器,则首先需要创建Redis容器。为此,可以使用Docker注册表中的官方Redis映像之一:$ docker run --name redis -d -p 6379:6379 redis:3-alpine
运行应用程序时,需要链接redis容器并设置REDIS_URL环境变量,类似于MySQL容器的链接方式。以下是启动应用程序的完整命令,包括redis链接:
$ docker run --name microblog -d -p 8000:5000 --rm -e SECRET_KEY=my-secret-key \
-e MAIL_SERVER=smtp.googlemail.com -e MAIL_PORT=587 -e MAIL_USE_TLS=true \
-e MAIL_USERNAME=<your-gmail-username> -e MAIL_PASSWORD=<your-gmail-password> \
--link mysql:dbserver --link redis:redis-server \
-e DATABASE_URL=mysql+pymysql://microblog:<database-password>@dbserver/microblog \
-e REDIS_URL=redis://redis-server:6379/0 \
microblog:latest
最后,需要为RQ worker运行一个或多个容器。因为工作程序基于与主应用程序相同的代码,所以可以使用用于应用程序的相同容器映像,覆盖启动命令,以便启动工作程序而不是Web应用程序。这是一个docker run启动worker 的示例命令:
$ docker run --name rq-worker -d --rm -e SECRET_KEY=my-secret-key \
-e MAIL_SERVER=smtp.googlemail.com -e MAIL_PORT=587 -e MAIL_USE_TLS=true \
-e MAIL_USERNAME=<your-gmail-username> -e MAIL_PASSWORD=<your-gmail-password> \
--link mysql:dbserver --link redis:redis-server \
-e DATABASE_URL=mysql+pymysql://microblog:<database-password>@dbserver/microblog \
-e REDIS_URL=redis://redis-server:6379/0 \
--entrypoint venv/bin/rq \
microblog:latest worker -u redis://redis-server:6379/0 microblog-tasks
覆盖Docker镜像的默认启动命令有点棘手,因为命令需要分为两部分。--entrypoint参数仅使用可执行文件名,但需要在命令行末尾的图像和标记之后给出参数(如果有)。请注意,rq需要在venv/bin/rq不激活虚拟环境的情况下进行操作。
如需转载请注明出处。