在命令行里输入命令安装模块
pip install requests
pip install random
以获取豆瓣网页内容为例
#导入需要用到的模块
import requests
#准备一个网址
url='https://movie.douban.com/top250'
res=requests.get(url) #requests模块会自动解码来自服务器的内容,可以使用res.encoding来查看编码
html=res.text
有些网页需要浏览器头部才能访问,下面使用添加浏览器头部的方法获取网页内容
查找自己浏览器头部的方法,以谷歌浏览器为例:打开一个网页然后点击右键,检查
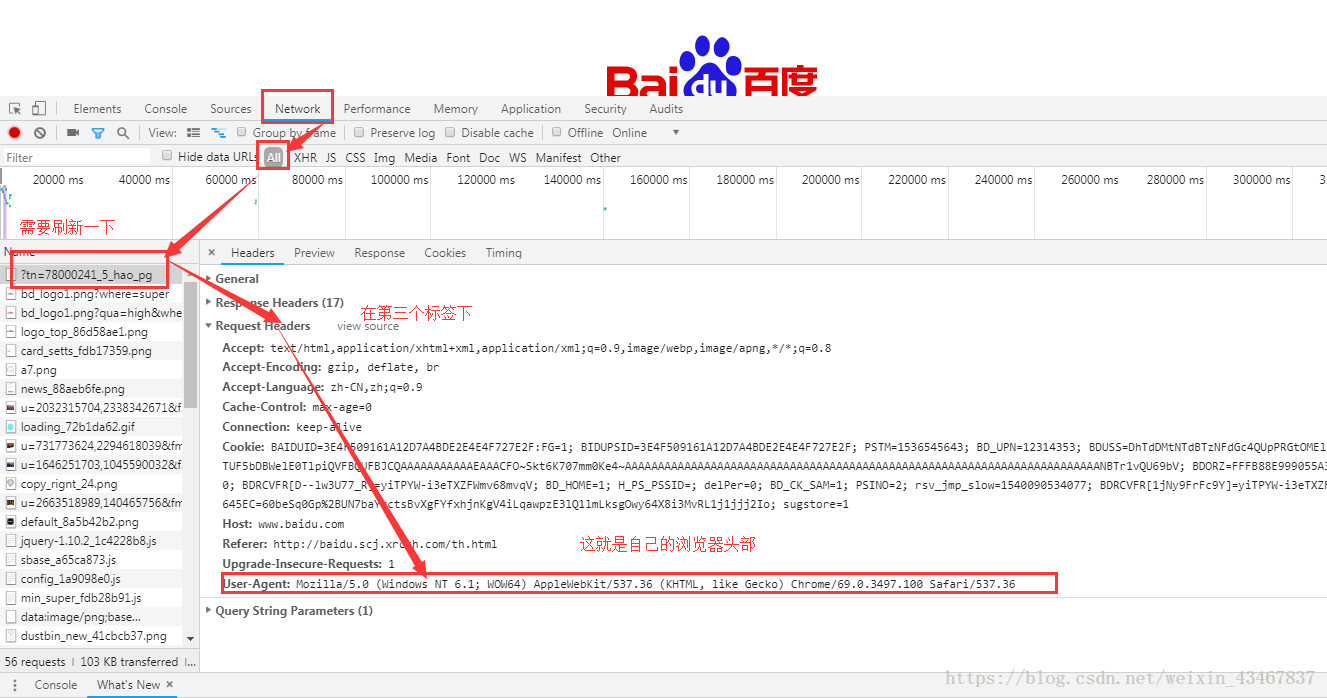
#导入需要的模块
import requests
import random
url='https://movie.douban.com/top250'
#准备浏览器头部
User_Agent='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
response=requests.get(
url,
headers={'User-Agent':random.choice(User_Agent)}) #把头部增加到请求中去
html=response.text
设置请求头部和代理IP
#导入需要的模块
import requests
import random
url='https://movie.douban.com/top250'
#准备浏览器头部
User_Agent='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
ips=[ {'HTTPS':'121.228.64.21 808','HTTP':'124.235.181.175 80'}]
response=requests.get(
url,
headers={'User-Agent':random.choice(User_Agent)},
proxies=random.choice(ips) # 把代理IP增加进去
)
html=response.text