一、基础概念
线程池是一种多线程开发的处理方式,线程池可以方便得对线程进行创建,执行、销毁和管理等操作。主要用来解决需要异步或并发执行任务的程序
线程池解决的问题:
1.线程池未出现前:如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因为频繁创建线程和销毁线程需要时间,而且会消耗系统资源。
如果使用线程池:线程在run()方法执行完后,不用将其销毁,让它继续保持空闲状态,当有新任务时让它继续执行新的任务。最后统一交给线程池来销毁线程。
2.io操作过多或者比较耗时
以下摘自《Java并发编程的艺术》
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,
还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是,要做到合理利用
线程池,必须对其实现原理了如指掌。
二、线程池的实现原理
当向线程池提交一个任务之后,线程池是如何处理这个任务的呢?下图就展示了线程池对任务的处理流程。
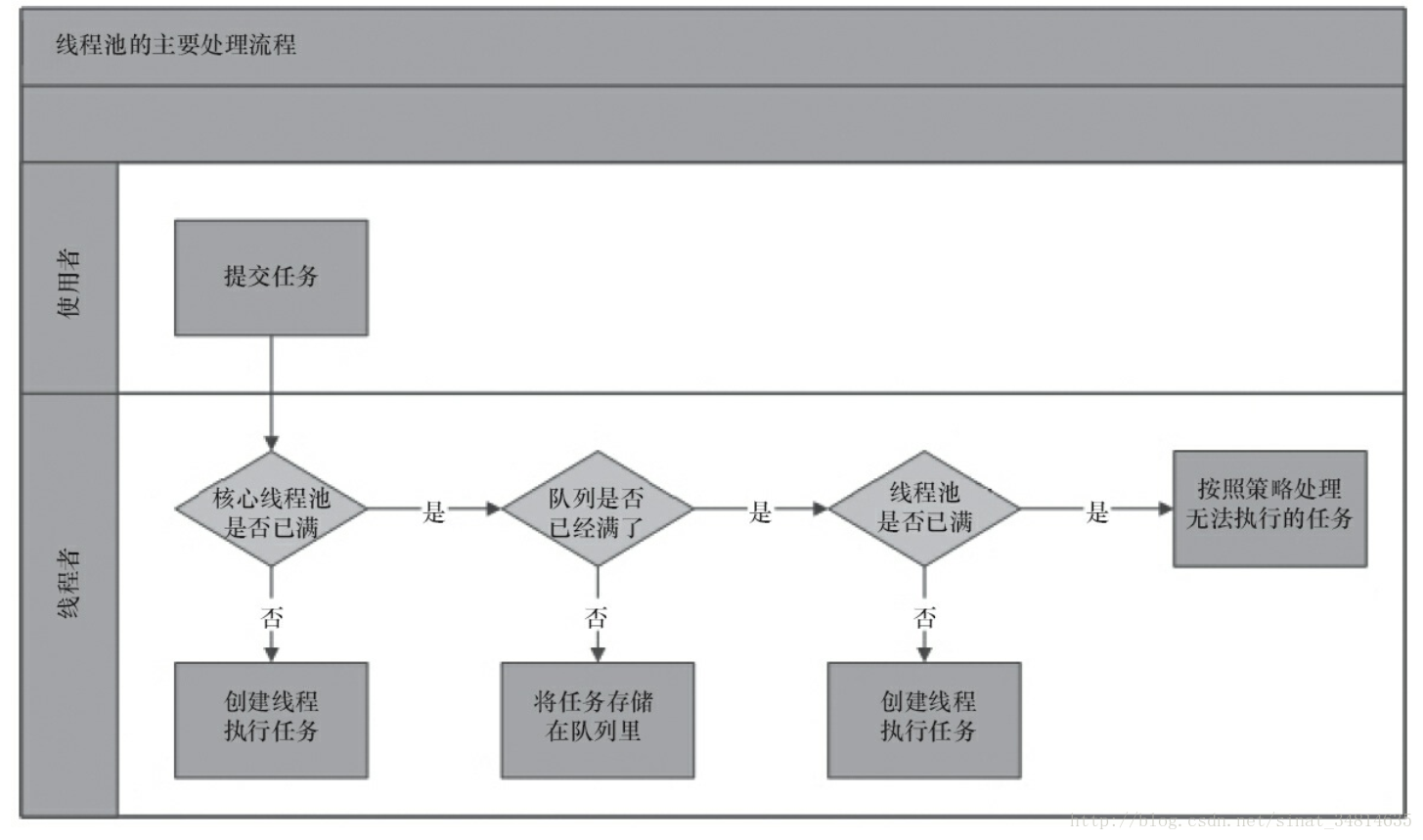
从图中可以看出,当提交一个新任务到线程池时,线程池的处理流程如下。
1.线程池判断核心线程池里的线程是否都在执行任务。如果不是,则创建一个新的工作
线程来执行任务。如果核心线程池里的线程都在执行任务,则进入下个流程。
如核心线程池的容量为5个线程。
1)如果有3个线程在工作,另外有2个线程没有创建或者处于空闲状态,那么线程池就创建一个线程或者让空闲状态的线程来执行任务。
2)如果有5个线程都在工作,则进入下个流程。
2.线程池判断工作队列是否已经满。如果工作队列没有满,则将新提交的任务存储在这
个工作队列里(期间不会创建新的线程)。如果工作队列满了,则进入下个流程。
3.线程池判断线程池的线程是否都处于工作状态。如果没有,则创建一个新的工作线程
来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
问题:
直接创建一个新的工作线程来执行任务吗?
答:是的,不会使用核心线程池里的线程,任务执行完后,这个线程的生命周期由所设置的keepAliveTime的大小控制。
名词解释:
工作线程:线程池创建线程时,会将线程封装成工作线程Worker,Worker在执行完任务
后,还会循环获取工作队列里的任务来执行。
三、线程池中线程的执行流程
ThreadPoolExecutor执行execute()方法的示意图,如图9-2所示。
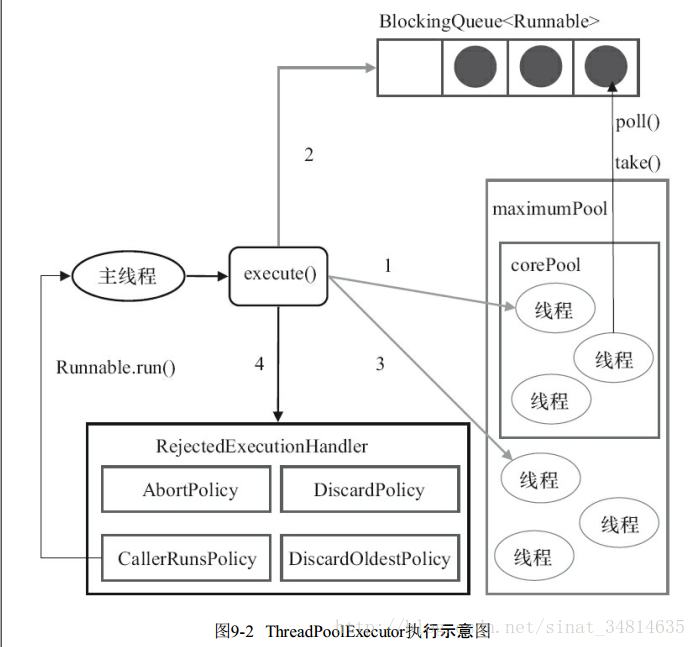
ThreadPoolExecutor执行execute方法分下面4种情况。
1.如果当前运行的线程少于corePoolSize,则创建新线程来执行任务
2.如果运行的线程等于或多于corePoolSize,则将任务加入BlockingQueue。
线程池会让corePoolSize里执行完任务的线程反复的获取BlockingQueue的任务执行。
3.如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务
4.如果创建新线程将使当前运行的线程超出maximumPoolSize,任务将被拒绝,并调用
RejectedExecutionHandler.rejectedExecution()方法。
问题:
1).全局锁
四、线程池中的各个组件
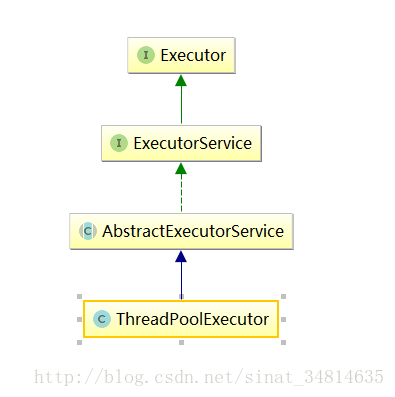
4.1 ThreadPoolExecutor类
ThreadPoolExecutor类的层级结构如下:
Executor接口
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
Executor接口只有一个方法execute(),通过这个方法可以向线程池提交一个任务,交由线程池去执行
ExecutorService接口
1.submit():
提交一个返回值的任务用于执行,返回一个表示任务的未决结果的 Future。
submit()和execute()的区别
1.最大的区别是submit()可以有返回值
2.submit()里面实际上也会执行execute()方法,,只不过它利用了Future来获取任务执行结果。而execute没有返回结果
2.shutdown()
启动一次顺序关闭,执行以前提交的任务,但不接受新任务。
ThreadPoolExecutor类
在ThreadPoolExecutor类中提供了四个构造方法:
public class ThreadPoolExecutor extends AbstractExecutorService {
.....
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler);
...
}
从上面的代码可以得知,ThreadPoolExecutor继承了AbstractExecutorService类,并提供了四个构造器,事实上,通过观察每个构造器的源码具体实现,发现前面三个构造器都是调用的第四个构造器进行的初始化工作。
各个参数名词解释:
corePoolSize(线程池的基本大小):核心池的大小。当提交一个任务到线程池时,线程池会创建一个线
程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任
务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,
线程池会提前创建并启动所有基本线程。
maximumPoolSize:线程池最大线程数。线程池允许创建的最大线程数。如果队列满了,并
且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是,如
果使用了无界的任务队列这个参数就没什么效果
keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率。
unit:参数keepAliveTime的时间单位。
workQueue:用于保存等待执行的任务的阻塞队列.。这个参数的选择也很重要,会对线程池的运行过程产生重大影响可以选择以下几个阻塞队列。
·ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原
则对元素进行排序。
·LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通
常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
·SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用
移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于Linked-BlockingQueue,静态工
厂方法Executors.newCachedThreadPool使用了这个队列。
·PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
ArrayBlockingQueue和PriorityBlockingQueue使用较少,一般使用LinkedBlockingQueue和Synchronous。线程池的排队策略与BlockingQueue有关。
SynchronousQueue详解
作为BlockingQueue中的一员,SynchronousQueue与其他BlockingQueue有着不同特性:
1.SynchronousQueue没有容量。与其他BlockingQueue不同,SynchronousQueue是一个不存储元素的BlockingQueue。每一个put操作必须要等待一个take操作,否则不能继续添加元素,反之亦然。
2.因为没有容量,所以对应 peek, contains, clear, isEmpty … 等方法其实是无效的。例如clear是不执行任何操作的,contains始终返回false,peek始终返回null。
3.SynchronousQueue分为公平和非公平,默认情况下采用非公平性访问策略,当然也可以通过构造函数来设置为公平性访问策略(为true即可)。
4.若使用 TransferQueue, 则队列中永远会存在一个 dummy node(这点后面详细阐述)
threadFactory:线程工厂,主要用来创建线程;
handler:表示当拒绝处理任务时的策略。
各个参数的详细解释请参考: http://www.cnblogs.com/dolphin0520/p/3932921.html
Executors
一般如果对线程池没有特别深入的研究或特别复杂的业务,不建议开发人员自己手动配置线程池.
java中的Executors提供了很多静态工厂来配置线程池如下所示(图片来源于core java):

推荐使用Executors.newCachedThreadPool():
1.Executors.newCachedThreadPool():
其源码如下:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
创建一个核心数为0,最大数为Integer.MAX_VALUE即(2^31)-1。被创建的线程60秒没有任务的时候就会被回收。由于采用的是SynchronousQueue(一个不存储元素的阻塞队列),当任务超过核心数的时候,就好创建线程去执行任务。偏向于线程比较宝贵的系统。
2.Executors.newFixedThreadPool()
固定线程池:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
newFixedThreadPool 创建一个固定核心数和最大线程数的线程池,被创建的线程将不会被回收,超出的线程会在基于链表的阻塞队列中等待。偏向于cpu运用频繁的系统。
3.Executors.newSingleThreadExecutor
单线程线程池。其源码如下:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
单线程线程池,核心线程数和最大线程数均为1,空闲线程存活0毫秒同样无意思,意味着每次只有一个线程执行任务,多余的先存储到工作队列,一个一个执行,保证了线程的顺序执行。
4.Executors.newScheduledThreadPool
调度线程池。其源码如下:
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}
即按一定的周期执行任务,即定时任务,对ThreadPoolExecutor进行了包装而已。
如何提交线程
如可以先随便定义一个固定大小的线程池
ExecutorService es = Executors.newFixedThreadPool(3);
提交一个线程
es.submit(xxRunnble);
es.execute(xxRunnble);
如何关闭线程池
es.shutdown();
不再接受新的任务,之前提交的任务等执行结束再关闭线程池。
es.shutdownNow();
不再接受新的任务,试图停止池中的任务再关闭线程池,返回所有未处理的线程list列表。
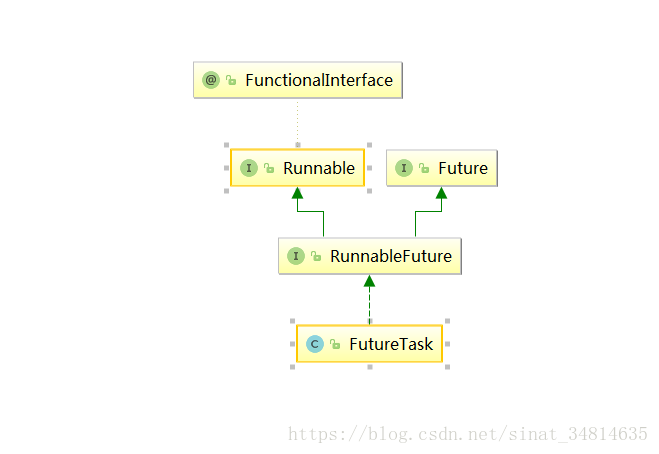
4.2 Future,FutureTask
Future:Future 表示异步计算的结果。它提供了检查计算是否完成的方法,以等待计算的完成,并获取计算的结果。
1)多用于获取callable的返回结果
FutureTask:对所继承的接口进行了基本的实现。
其对应关系如下
三、Java中的并发工具类
CountDownLatch
CountDownLatch类位于java.util.concurrent包下,利用它可以实现类似计数器的功能。比如有一个任务A,它要等待其他4个任务执行完毕之后才能执行,此时就可以利用CountDownLatch来实现这种功能了。
CountDownLatch类只提供了一个构造器如下:
/**
* Constructs a {@code CountDownLatch} initialized with the given count.
*
* @param count the number of times {@link #countDown} must be invoked
* before threads can pass through {@link #await}
* @throws IllegalArgumentException if {@code count} is negative
*/
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
然后下面这3个方法是CountDownLatch类中最重要的方法:
public void await() throws InterruptedException { }; //调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行
public boolean await(long timeout, TimeUnit unit) throws InterruptedException { }; //和await()类似,只不过等待一定的时间后count值还没变为0的话就会继续执行
public void countDown() { }; //将count值减1
注意与join()方法的联系
参考资料
1.《Java并发编程的艺术》方腾飞 魏鹏 程晓明 著
2.《core java》
3. Java并发编程:线程池的使用:http://www.cnblogs.com/dolphin0520/p/3932921.html
4. 【死磕Java并发】—– 死磕 Java 并发精品合集http://cmsblogs.com/?p=2611
5. java高级应用:线程池全面解析https://mp.weixin.qq.com/s/fFZfEe10bdVKBndrEFH4fA