前言
Python中出场率很高的分布式队列神器celery,正巧近期一些需求需要使用,因而换装celery。
此前已经介绍过Python利用pika进行RabbitMQ的使用,Celery官网介绍首页就给出支持设定 RabbitMQ作为celery的brokers,celery官网地址 。演示Celery版本4.1.0,Python 3.5.2, MacOS,RabbitMQ 3.6.12,Redis 3.2.6。
所有示例代码均可在个人github中下载,celery_example.
celery 概述
Celery是一个异步的分布式任务队列,个人看来其核心是任务调度功能,并不包括消息存储功能。那么配合其使用的可以是redis,或是RabbitMQ,用以存储消息。
安装自不必说,pip直接就能安装。
使用之前还是需要了解celery消息队列的几个定义。
1,broker:消息代理,存储生产者发送的任务消息,并提供给消费者,通常是redis,或者RabbitMQ。
2,backend:消费者接受任务消息处理完后的保存状态和结果。
3,worker:任务执行者,从broker中接受属于自己的消息并执行对应任务。
4,beat:心跳,任务调度的核心。Celery不仅能分发任务,还能够执行定时任务。
Celery使用
Celery – Redis
Celery的Worker 文件get_start.py代码定义如下:
import time
from celery import Celery
broker = 'redis://127.0.0.1:6379/5'
backend = 'redis://127.0.0.1:6379/6'
app = Celery('tasks', broker=broker, backend=backend)
@app.task
def my_task(name, seconds):
time.sleep(int(seconds))
print('{} sleeps for {} sec'.format(name, seconds))
return name对于上述Celery Worker功能,启动命令如下:
celery -A worker get_start -l info消息发布者use_task.py 代码如下:
from get_start import my_task
def on_message(body):
print('body -- ', body)
r = my_task.delay('Rookie', 5)
s = my_task.delay('TheShy', 4)
j = my_task.delay('JLK', 3)
print('r --- ', r.get(on_message=on_message))
print('s --- ', s.get(on_message=on_message))
print('j --- ', j.get(on_message=on_message))执行结果如图:
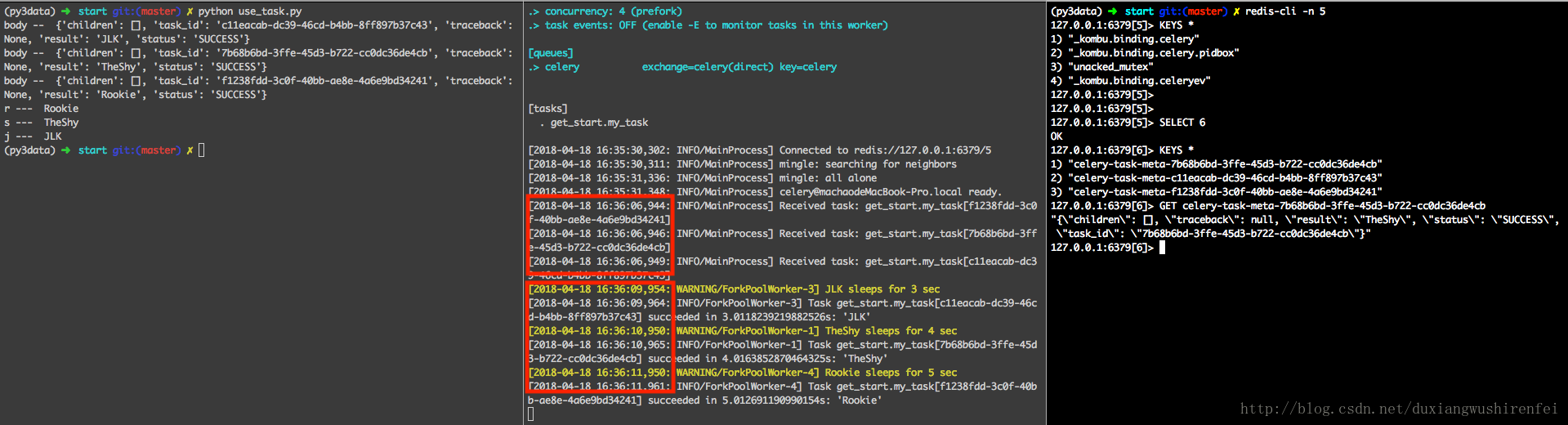
1,执行结果是显而易见worker是并发执行的,Celery官网上有说明,在没有指定并发数量的情况下, 默认最大并发数是机器的CPU核数。红框中 Worker是在16:36:06 收到 发布者发送的消息,并发执行,分别在3s, 4s, 5s后执行完各个人物,最终在 16:36:11 执行完所有任务。
2,任务Publisher调用发布消息后,在get结果时,on_message作为得到结果的回调函数时异步执行的,先得到返回结果的先执行。对于主程序通过get方法获取结果时同步执行的。
Celery – RabbitMQ
关于RabbitMQ的相关信息请参见之前的博文RabbitMQ 笔记一。
开启RabbitMQ服务后,修改Celery Worker的broker和backend如下:
broker = 'amqp://tester:[email protected]:5672'
backend = 'amqp://tester:[email protected]:5672'现要在不同结点上启动多个Worker做多个,分别修改Worker中注册的task功能,让其在其中一点上的Worker异常,另一结点上Worker正常运行
@app.task
def rabbit_task(self, name, seconds):
# 其中一个结点,解开注释,模拟出现异常
# raise Exception
time.sleep(int(seconds))
print('{} sleeps for {} sec'.format(name, seconds))
return name此时运行结果如下:
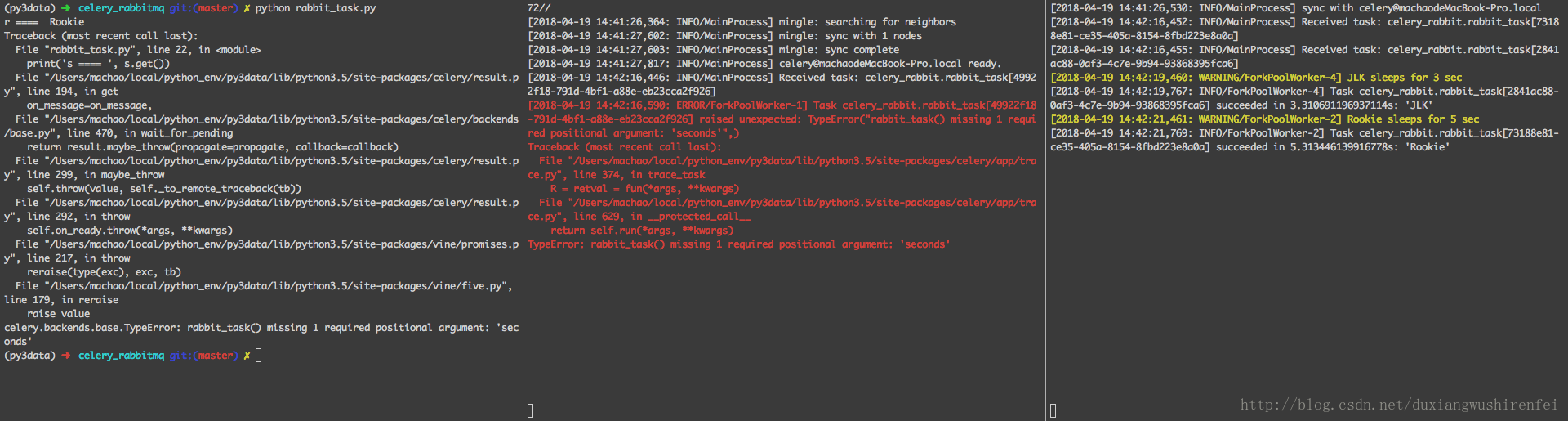
可以看出:
1,Celery 不同的Worker会被分发消息,然后并行执行。
2,在Worker执行Task过程中如果出现未捕获的异常,会直接影响主调Task的主程序。
3,对于出现异常的Worker,也同样会发送ack确认本条message已被消费。
以上是Celery运用RabbitMQ做broker的形式,值得注意的是Celery已经弃用了RabbitMQ做broker调用on_message方法,因为会持久化结果,此处如果get中回调on_message会报错。
Celery 消息确认 acknowledge
对于上述和RabbitMQ结合的示例中,特意模拟了任务执行出现异常的情况,此时Celery中是可以在绑定Task时给出了Retry的设定, 可以让该任务在指定的时间后再次尝试,具体请参见官网Celery – Tasks。
但是此种方式,仍然是在该节点的worker上执行的,如果想要一个worker执行失败后,换节点执行就无法满足了。因为在之前的RabbitMQ的介绍中给出了,消费消息时是可以设定确认信息的模式,此时如果没有确认,RabbitMQ会认为该消息没有被消费,仍然继续分发。此处在大家参阅上面的Tasks文档时,多处指出即便设定了 acks_late 的参数,worker 仍然会发送 acknowledge的,只不过是等tasks返回后。即便执行出现异常,仍旧算是该消息被正常消费。如果希望达到的效果就是执行失败后,换节点执行,可以如下改写Task:
from celery.exceptions import Reject
@app.task(acks_late=True)
def rabbit_task(name, seconds):
try:
time.sleep(int(seconds))
print('{} sleeps for {}
raise Exceptionsec'.format(name, seconds))
return name
except Exception as err:
raise Reject(err, requeue=True)此时再次在不同机器节点上启动两个 Worker,一个带有异常,一个正常执行,查看结果如下:
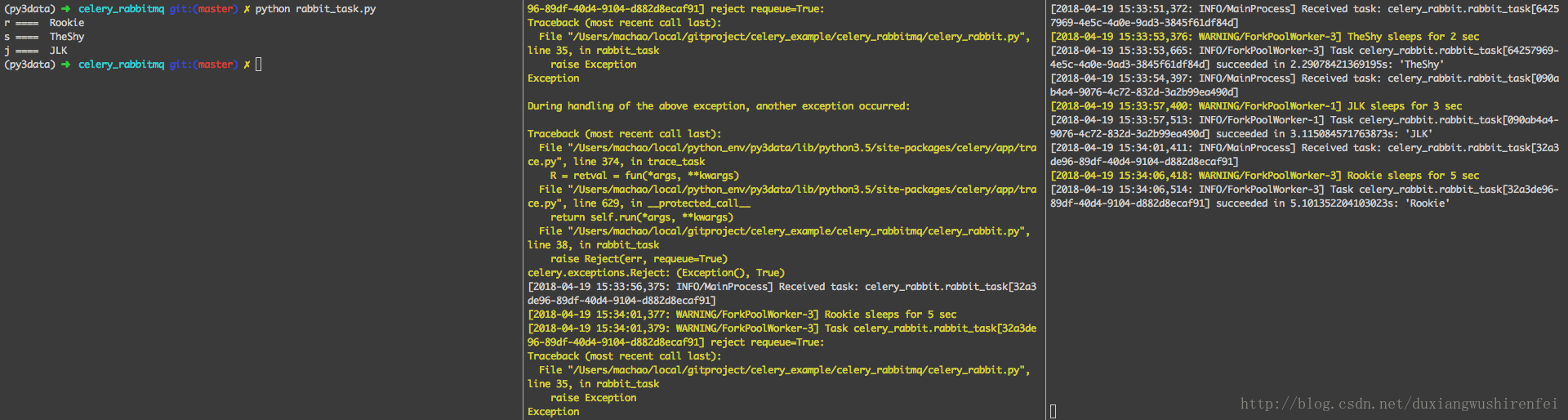
可以看出:
1,中间Worker 收到两条任务,并且均未能正常执行。
2,该节点异常后,直接调用了Reject方法,拒绝该任务,默认requeue是false,表示该message是不回被重新放回队列,就当是正常消费了,置为True后会重回队列。
3,而后由于Worker 2尚在执行一个任务,Worker 1又被分配执行了一次队列中任务,仍然异常将message 重放回队列。
4,最终由worker2 完成3个任务的执行,调用者得到正常结果。
5,此处,如果worker捕获异常,未上抛,那么调用端会得到None值的返回。
由此Reject的异常,达到了message未正常消费的不发送acknowledge功能。
Celery – 指定 worker
在做任务分发响应时,可能会有需要指定节点响应某一任务。可以在不同节点上均启动worker,且为不同worker配置不同队列,而后为不同任务绑定特有的队列,由此完成了指定节点
在 celery_example 的specify_queue工程中,以config形式,配置Celery 的task路由CELERY_ROUTES,以及所需要注册的task文件CELERY_IMPORTS。详细的请参见Celery – config 配置。
注意:
一定要CELERY_IMPORTS指定需要获取注册Task的文件,否则Celery Worker启动时不会将定义在其他文件中的Task加载进来。
对于Worker的启动命令,可以通过help进行详细查阅
# 启动worker
celery -A celery_rabbit worker -l info
# 启动worker 并且指定该worker监听的队列
celery -A main_celery worker -l info -Q task_worker_1celery -A 指定启动的app是celery_rabbit文件
worker表示启动worker
-l 表示指定log级别为 info
-Q 表示监听队列为 task_worker_1
仍旧是在两台机器上启动不同worker并指定队列task_worker_1, task_worker_2,执行任务调用结果如下:

可以看出节点1只响应task_worker_1的任务,节点2只响应task_worker_2。
最初的需求场景是需要统计一个时间跨度对应数据,指定不同的客户,可能一次性要导出几百个客户一个月的账目。需要统计的数据在10w条左右,峰值时占用内存约2.5GB,一次统计可能耗时5min以上,单台服务器做这种响应太吃力,因此可以利用celery在不同节点上起多个worker,分片统计。假设每次统计的步长为50个客户,因此对于200个客户数据可以分为4个message,指定给对应两个不同节点上的worker统计后汇总,由此即便往后客户数量增加,可以拓展worker以加快响应速度。
不仅如此Celery还可以设定CELERYBEAT_SCHEDULE以执行定时任务。Celery官方文档中给出很多很详细的使用手册,特别是参数设定,能够基本满足一些日常使用需求。