版权声明:https://blog.csdn.net/qq_40025218 https://blog.csdn.net/qq_40025218/article/details/82286967
#linux统计文档中字符串出现次数并排序
免费领取满减阿里云红包
文件内容:
统计命令示例(统计字符串1 和78得出现次数并排序)

cat 1.txt |grep -o '1\|78'|sort |uniq -c|sort -nr

参数解释:
- cat 查看这个1.txt文件
- grep -o ‘1/|78’ 筛选7和78
-o 只输出符合 的字符串 中间用/\|隔开,如要筛选多个可以这样写
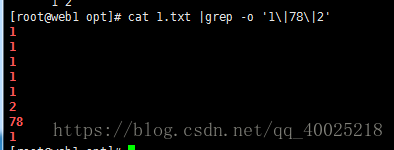
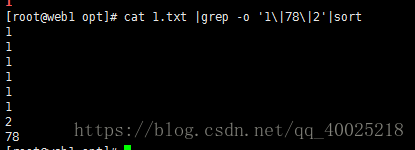
cat 1.txt |grep -o '1\|78\|2'
3. 对行进行排序
先排序是因为去重与统计的 ‘unip’命令只能处理相邻行
4. 统计数量与去重
uniq -c 中的-c 代表在每列旁边显示该行重复出现的次数
5. 按重复次数排序
sort 的 -n:依照数值的大小排序;-r 按照相反顺序排列


其他shell命令可以看:https://blog.csdn.net/qq_40025218/article/category/7889830