VGG-16
Karen Simonyan 在《Very Deep Convolutional Networks for Large-scale Image Recognition》中讨论了卷积网络的深度对其在大规模图像识别的准确性的影响。作者比较了5中不同深度的卷积网络,其中深度为16的网络——VGG-16成为一种经典的网络架构。许多网络都是在VGG-16的基础上删除和添加其他层。
VGG-16 Architecture
这里只介绍VGG-16的架构,这是用的最多的一种网络,论文中的其它4个就不介绍了。
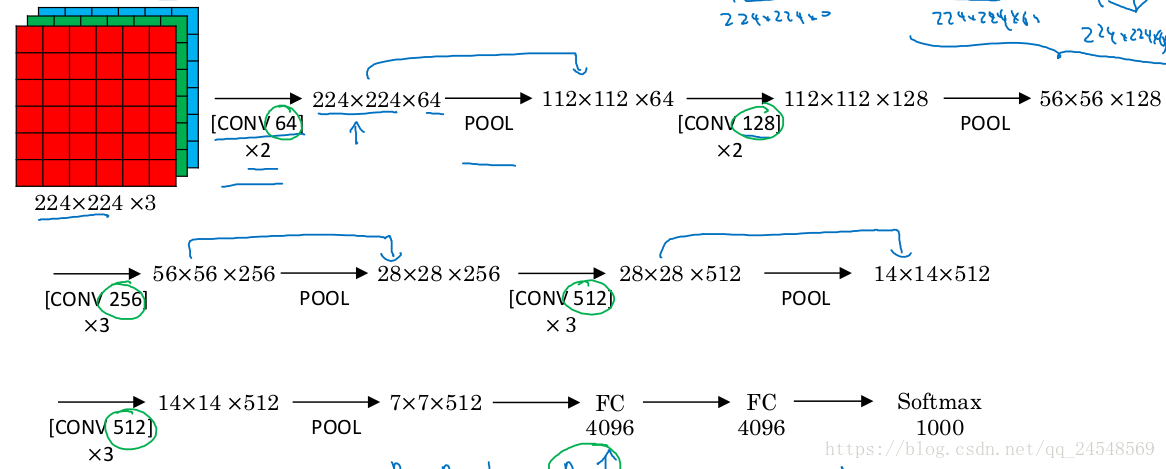
VGG-16的网络很简单,有13个卷积层(被5个max-pooling层分割)和3个全连接层。所有卷积层的过滤器大小都是 ,步长为1,进行padding。作者设置所有卷积层的过滤器大小都为 是有原因的,因为过滤器尺度更大的卷积层可以使用多个 卷积层来达到同样的效果,比如2个连在一起的 卷积层(步长为1)的接收域与 的卷积层的接收域一样。作者还给出了更多的解释,首先,使用多个 卷积层而不是相同接收域的一层卷积层,可以提高网络的分类能力(相当于添加了隐式的正则化)。第二,可以减少参数数量。这里举个例子,3个 卷积层的接收域相当于1个 卷积层的接收域,假设卷积前后feature map的channel都是C,那么 卷积层的参数为 ,而 卷积层的参数为 ,多了81%。
5个max-pooling分别在第2、4、7、10、13卷积层后面,池化效果是feature map长宽减少一半(filter ,步长2)。作者并没有使用local response normalisation (LRN),因为通过对比实验发现LRN并没有提高网络的表现,反而增加的网络的参数。
每次max-pooling之后,feature map的channel都会 ,从64开始,直到512,之后保持不变。
之后的全连接层的大小分别为4096、4096、1000,因为改网络的目的是对ILSVRC的1000个类分类,所以网络最后使用softmax层。
其他基于VGG-16的网络或者修改最后一层全连接层的大小(不同的分类数量),或者删除最后一层全连接层或删除所有全连接层,后面接上自己设计的网络,把VGG-16作为图片的特征提取器。
图片处理
网络的输入大小为 ,而数据集大图片有各种尺寸,需要统一数据集图片的大小。令图片最短边的长度的S, 。S稍微大于224效果最好,因为训练时从图片取出 的区域进行训练,如果S远大于224,提取的区域只包含目标对象的部分位置,降低网络的分类表现。作者使用两种方法设置S的大小。第一种方法是固定S大小,作者尝试两个值,256和384。第二种方法是令 ,每张训练图片都会从 和 中随机选取一个S。因为数据的图片是不同尺度的,随机S增加网络的鲁棒性,实验结果也证明了这一点。
训练图片还应用了其他数据归一化技巧,数据合成技巧等,这里就不多说了。
Testing
令测试图片的最短边长度为Q,Q可以和S不同。作者把全连接层改成卷积层,使得整个网络成为全卷积网络,在测试时,直接把整个图片传入网络,最后得到channel为1000的feature map,而每个feature map是图片上不同区域的类别的分数,有feature map的大小取决于缩放后图片的尺度。作者对整个feature map取平均值作为对应类别的分数。
相比于从图片中取多个区域,对每个区域求各类的分数,最后取平均值,全图片卷积能够加快运算时间,而且可以增加整个网络的接收域,接收到更多的内容,因为第一层卷积padding不是填充0,而是图片卷积区域外的像素值。
多GPU训练
作者使用Caffe训练网络。训练过程并行化处理,具体是,把每个batch的训练图片分成几个GPU batch,每个GPU处理一个GPU batch。当算出GPU batch 梯度后,集合所有GPU batch梯度并取平均值作为整个batch的梯度。