1、面向接口编程的好处?
①、 降低程序的耦合性;
②、易于程序的扩展,遵循OOP的开放关闭原则。
2、使用枚举有什么好处?
枚举表示含义会比较明确,而且是单例的形式的静态的final变量,所以还是线程安全的。
3、Mybaitis如何执行批量插入?
批量插入SQL时都是用的<foreach>标签,但有时需要插入成千上万条语句,此时用<foreach>标签拼接的SQL就会非常大,有时数据库识别不了。
所以此时就得使用另一种方式:
默认情况下,mybatis执行SQL的sqlSession的defaultExecutorType的值为ExecutorType.SIMPLE,这种情况下的批量执行其实就是利用拼接SQL语句,也就是上述的foreach形式,显然当批量数据过大的时候是不合适的。所以当我们在使用大批量的操作时,获取sqlSession时就要定义其执行器的类型为ExecutorType.BATCH。这样可以利用BATCH执行器重用语句和批量更新。
当然也可以把BATCH执行器整合到Spring中一起使用。整合如下:
<!--配置一个可以进行批量执行的sqlSession -->
<bean id="sqlSession" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg name="sqlSessionFactory" ref="sqlSessionFactoryBean"></constructor-arg>
<constructor-arg name="executorType" value="BATCH"></constructor-arg>
</bean>
@Autowired
private SqlSession sqlSession;
public List<User> batchUsers(){
UserDao userDao= sqlSession.getMapper(UserDao .class);
return userDao.batchUsers();
}
4、是否可以在foreach中新增删除集合内元素,如果不行如何操作?
不可以,会出现异常java.util.ConcurrentModificationException。
如果看源码的时候会发现,foreach循环其实就是根据集合对象创建一个iterator迭代对象,用这个迭代对象来遍历集合。
其循环基本都会有两个操作:①、iterator.hasNext();//判读是否有下个元素; ②、item = iterator.next();//下个元素是什么,并把它赋给item。
在生成iterator的时候,会保存一个expectedModCount参数,这个是生成iterator的时候集合中元素修改的次数。如果你在遍历过程中删除元素,集合中的modCount(表示集合元素的修改次数)就会变化,如果这个modCount和exceptedModCount不一致,就会抛出异常,这个是为了安全的考虑。
如果非要再循环中做删除操作,需要使用迭代器进行循环集合,然后使用迭代器的remove方法,如下:
Iterator it=list.iterator();
while(it.hasNext()){
Object e=it.next();
if("b".equals(e)){
it.remove();
}
}
5、创建线程池的方式有哪些?
略。
6、volatile的作用?
保持内存可见性和防止指令重排序。(记住其本质并不是线程安全的,更详细的内容到博客中获取。)
7、对sleep、wait、join、yield各个方法的理解?
sleep:在指定的毫秒数内让当前正在执行的线程休眠(暂停执行),此操作受到系统计时器和调度程序精度和准确性的影响。该线程不丢失任何监视器的所属权。也就是说不会释放锁。
wait:属于Object的方法,执行后线程会处于等待状态,需要notify/notifyAll方法唤醒后才会继续执行。
join: join方法则是用于等待其他线程结束,当前运行的线程可以调用另外一个线程的join()方法,当前的进程将变为挂起状态,直到另外一线程运行结束,该线程才继续运行。(如果任何线程中断了当前线程。当抛出该异常时,当前线程的 中断状态 被清除。)
yield:暂停当前正在执行的线程对象,并执行其他线程,当前线程进入就绪的状态。
8、linux如何查看服务器负载?
使用top命令查看负载,在top下按“1”查看CPU核心数量,shift+"c"按cpu使用率大小排序,shif+"p"按内存使用率高低排序;
9、linux如何查看所有Tomcat的进程?
ps -ef |grep tomcat
10、linux如何查看端口的使用情况?
netstat -nultp:该命令是查看当前所有已经使用的端口情况。
netstat -anp |grep 端口号:用于查询某端口使用情况。

12、在千万级别数量的表中,SQL中的分页查询如何优化?
①、首先应考虑在 where 及 order by 涉及的列上建立索引。
②、避免在 where 子句中使用!=或> <操作符,否则将引擎放弃使用索引而进行全表扫描。
③、首次查询的时候缓存结果。
④、不显示总共有多少条目。(Google搜索结果的分页显示就用了这个特性。很多时候你可能看了前几页,就够了。)
⑤、不显示总页面数。只给出“下一页”的链接。
13、简述tomcat的connector中线程创建的几种模式, 并分析优缺点?
(1)、BIO:
bio(blocking I/O)是指阻塞式I/O操作,Tomcat在默认情况下就是以bio模式运行的。每个客户端连接过来后,服务端都会启动一个线程去处理该客户端的请求。
缺点:1、当客户端多时,会创建大量的处理线程。每个线程都要占用栈空间和一些CPU时间。
2、阻塞可能带来频繁的上下文切换,而大部分的上下文切换是无意义的。
(2)、NIO:
nio(non-blocking I/O)是非阻塞I/O操作。nio是一个基于缓冲区并能提供非阻塞I/O操作的Java API,它拥有比bio更好的并发运行性能。要让Tomcat以nio模式来运行也比较简单,我们只需要修改下server.xml文件即可。
优点:
NIO的工作原理包括:
1.由一个专门的线程来处理所有的 I/O 事件、并负责分发。
2.事件驱动机制,而不再同步地去监视事件。
3.线程之间通过 wait,notify 等方式通讯。保证每次上下文切换都是有意义的,减少无谓的线程切换。
(3)、APR:
apr(Apache portable Run-time libraries/Apache可移植运行库)是Apache HTTP服务器的支持库。其是在Tomcat上运行高并发应用的首选模式。
14、编程实现输入一个文件名和字符串,并返回该字符串在文件中出现的次数?
public final class MyUtil {
// 工具类中的方法都是静态方式访问的,因此将构造器私有,不允许创建对象(绝对好习惯)
private MyUtil() {
throw new AssertionError();
}
/**
* 统计给定文件中给定字符串的出现次数
*
* @param filename 文件名
* @param word 字符串
* @return 字符串在文件中出现的次数
*/
public static int countWordInFile(String filename, String word) {
int counter = 0;
try (FileReader fr = new FileReader(filename)) {
try (BufferedReader br = new BufferedReader(fr)) {
String line = null;
while ((line = br.readLine()) != null) {
int index = -1;
while (line.length() >= word.length() && (index = line.indexOf(word)) >= 0) {
counter++;
line = line.substring(index + word.length());
}
}
}
} catch (Exception ex) {
ex.printStackTrace();
}
return counter;
}
}
15、简述常见的缓存技术,并描述使用场景?
Ehcache:Ehcache是一个外部jar包,是java领域常用的缓存框架,鼎鼎大名的hibernate都是用Ehcache。
Memcached:Memcached是分布式缓存技术,需要独立部署,使多台机器可以使用同一个缓存服务器,实现集群的缓存共享。
Redis:Redis同样是分布式缓存技术,比Memcached更新,支持的数据类型更多,使用更方便,最重要的是:Memcached的数据只能存在内存中,重启后即消失,而Redis可以持久化,因此Redis可以作为一个NoSql数据库使用。
16、对比RDBMS和NoSQL?
(1)、关系数据库管理系统(RDBMS):
优点:高度组织化结构化数据 、数据和关系都存储在单独的表中、存在基础事务
缺点:复杂性、成本高、吞吐量低
(2)NoSQL:
优点:小服务器成本和开源、没有模式或固定数据模型、支持集成缓存
缺点:大多都是初创产品,不够成熟、大多数nosql都不支持事务(redis支持,MongoDB不支持)
17、分布式如何保证数据库的一致性?
分布式环境下(数据分布)要任何时刻保证数据一致性(强一致性)是不可能的,只能采取妥协的方案来保证数据最终一致性(既数据最终会保持一致,但不是时刻)。
一般要保证数据的一致性时,最重要的是考虑数据的顺序性的问题(一般代价都会比较大,可能需要摒弃一些异步操作,当保证前一步操作执行成功才执行后续操作)。
在不需要保证顺序性的前提下,可以利用请求/应答的模式来完成数据的一致性,既需要保证消息都成功发送和被处理,并且对于同一批数据要嘛全部执行,如果出现失败需要保证全部回滚。
A->B : 你收到我的一条消息没有,消息的ID是12345
B->A: 我收到了你的一条消息数据,消息数据是ID;12345
这样就一个请求,一个应答,就完成了一次可靠性的传输。如果A一致没有收到B的应答,就不断的重试。这个时候B就必须保证幂等性(相同的请求必须有一致的结果)。不能重复的处理消息。
18、分布式多台的日志如何处理?
系统一大,就会拆分成多个独立的进程。要看一个请求怎么从头到尾走的,就有些困难了,要是进行DEBUG、跟踪,就更加麻烦了,困难程度要视进程多少而定,越多越复杂。
一般分布式时对于日志会采用日志收集系统处理,目前较主流的处理方式是利用ELK(Elasticsearch , Logstash, Kibana , 它们都是开源软件)架构做日志收集和搜索。
详细可以参考博客【https://blog.csdn.net/qq_33404395/article/details/82320976】
19、什么情况会导致SQL放弃索引进行全表扫描?
避免在 where 子句中使用!=或> <操作符,否则将引擎放弃使用索引而进行全表扫描。
like '%liu'百分号在前
not in ,not exist
索引列上存在null值,导致COUNT(*)不能走索引。
索引列上有函数运算,导致不走索引。
select *,可能会导致不走索引。
19、ThreadLocal作用和原理分析?
ThreadLocal主要为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。要理解ThreadLocal需要理解下面三个问题:
①、每个线程的变量副本是存储在哪里的?(参考ThreadLocal的get()源码)
每个线程都有一个threadLocals成员,引用类型是ThreadLocalMap,以ThreadLocal和ThreadLocal对象声明的变量类型作为参数。这样,我们所使用的ThreadLocal变量的实际数据,通过get函数取值的时候,就是通过取出Thread中threadLocals引用的map,然后从这个map中根据当前threadLocal作为参数,取出数据。也就是说其实不同线程取到的变量副本都是由线程本身的提供的,存储在线程本身,只是借助ThreadLocal去获取,不是存放于 ThreadLocal。
②、变量副本【每个线程中保存的那个map中的变量】是怎么声明和初始化的?
当线程中的threadLocals成员是null的时候,会调用ThreadLocal.createMap(Thread t, T firstValue)创建一个map。同时根据函数参数设置上初始值。也就是说,当前线程的threadlocalmap是在第一次调用set的时候创建map并且设置上相应的值的。
在每个线程中,都维护了一个threadlocals对象,在没有ThreadLocal变量的时候是null的。一旦在ThreadLocal的createMap函数中初始化之后,这个threadlocals就初始化了。以后每次ThreadLocal对象想要访问变量的时候,比如set函数和get函数,都是先通过getMap(Thread t)函数,先将线程的map取出,然后再从这个在线程(Thread)中维护的map中取出数据或者存入对应数据。
③、不同的线程局部变量,比如说声明了n个(n>=2)这样的线程局部变量threadlocal,那么在Thread中的threadlocals中是怎么存储的呢?threadlocalmap中是怎么操作的?
在ThreadLocal的set函数中,可以看到,其中的map.set(this, value)把当前的threadlocal传入到map中作为键,也就是说,在不同的线程的threadlocals变量中,都会有一个以你所声明的那个线程局部变量threadlocal作为键的key-value。假设说声明了N个这样的线程局部变量变量,那么在线程的ThreadLocalMap中就会有n个分别以你的线程局部变量作为key的键值对。
20、ThreadLocal为什么会内存泄漏?
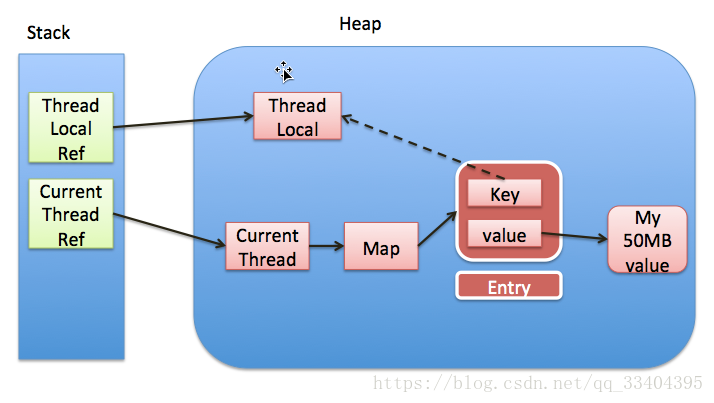
ThreadLocal的实现是这样的:每个Thread 维护一个 ThreadLocalMap 映射表,这个映射表的 key 是 ThreadLocal实例本身,value 是真正需要存储的 Object。
也就是说 ThreadLocal 本身并不存储值,它只是作为一个 key 来让线程从 ThreadLocalMap 获取 value。值得注意的是图中的虚线,表示 ThreadLocalMap 是使用 ThreadLocal 的弱引用作为 Key 的,弱引用的对象在 GC 时会被回收。
ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用来引用它,那么系统 GC 的时候,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value永远无法回收,造成内存泄漏。
21、ThreadLocal如何防止内存泄漏?
每次使用完ThreadLocal,都调用它的remove()方法,清除数据。
在使用线程池的情况下,没有及时清理ThreadLocal,不仅是内存泄漏的问题,更严重的是可能导致业务逻辑出现问题。所以,使用ThreadLocal就跟加锁完要解锁一样,用完就清理。