mysql 优化是一个很有意思的话题,可以从很多方面来说,大到服务器集群,应用体系架构等,小到字段类型选择,存储引擎的选择等,随着mysql的发展,到目前(最新版本是8.0,笔者5.7)Innodb 已是默认的存储引擎(mysql 5.5 已将InnoDB作为默认存储引擎),所以尽量选择使用InnoDB 作为默认的存储引擎,如果想要使用myisam 存储引擎的全文索引特性 ,建议使用InnoDB + Sphinx 组合,而不是使用支持全文索引的MyISAM,这里借用mysql 高性能第三版书中一句话,"除非需要用到某些InnoDB不具备的特性,并且没有其他办法可以替代,否则都应该优先选择InnoDB引擎",来结束对存储引擎选择问题的概述。下面就说下字段类型的选择问题。
主要有以下几个原则可作为参考:
-
1. 选择的列尽可能的占用少的存储空间
更小的数据类型通常更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期也更少。当我们在需要存储年龄,性别这些类似的应用场景中,应该选择tinyint 来存储,而不是int 。在处理日期的时候,也应该遵循这一原则,比如需要存储用户出生日期,应该选择date类型。
这里说下存储日期时间数据的注意事项:
不要使用字符串类型来存储日期时间数据
日期时间类型通常比字符串占用的存储空间小
日期时间类型在进行查找过滤时可以利用日期来进行对比
日期时间类型还有着丰富的处理函数,可以方便的对日期时间类型进行计算
使用int存储日期时间不如使用Timestamp类型
-
2. 数据类型的整合最好固定长度
除此之外,需要存储用户密码等长度值近似的字符时,应该优先考虑char 数据类型,因为char 是定长,varchar 是变长,mysql 处理char 比 varchar 要快一点。char类型的最大宽度为255 字节,varchar 最大宽度为 65535 个字节 。varchar列的最大长度小于255则只占用一个额外字节用于记录字符串长度,列的最大长度大于255则只占用两个额外字节用于记录字符串长度。当在项目中能确定用户某个字段长度不会超过varchar 所能存储的最大长度,单位了以防万一而不得不使用更大的数据类型的是时候,也应该遵循这一原则,比如我能确定用户所填数据不会超过varchar 所能存储的最大长度,但为了防止用户瞎操作,出现异常,而采用了text 类型来存储,后来还是采用了medium text 来存储。
-
3. 选择的列尽可能的使用整数
在生活中我们用到小数的应用场景很常见,比如:15.8元,100.2kg等等。在项目中,诸如入此类需要存储小数的问题,应优先考虑用整数来存储,而不是小数。下面 ,先来看一下,在mysql 中,浮点数数据类型特点:
| 列类型 | 存储空间 | 是否精确类型 |
| float | 4 个字节 | 否 |
| double | 8个字节 | 否 |
| decimal | 每4个字节存9个数字,小数点占一个字节 | 是 |
首先存整数和存小数,所占据空间是一样的(这是只拿int 和float 来说),甚至更小。
其次浮点数运算会有精度丢失问题(decimal暂不考虑)。
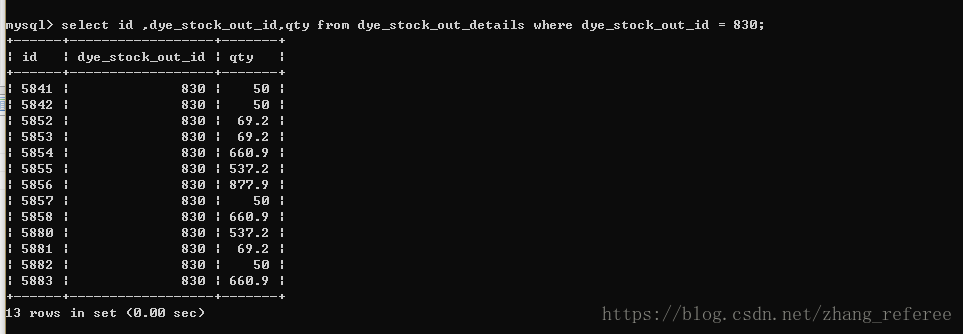
当我们需要对该表的qty这个字段做运算的时候有时会出现浮点数精度丢失问题。

由于上表的qty 这个字段数据类型是doublel 型的,所以在做运算时会产生精度问题,从而在业务层做处理时造成不必要的麻烦(比如需要对计算结果取整或保留两位小数)。当然你可能会说为什么不用decimal 来存储呢?是的,用decimal 来存储确实能规避浮点数精度丢失问题,但是有一个问题用decimal 会比较慢,而且decimal 也不是必须的,比如上面提到的应用场景,在存储钱的问题的时候,我们可以精确到分,比如:15.8元,在数据库中存储可以存储为1580分,重量kg可以精确到克(g),这样就能很好的规避浮点数精度问题,还能减少存储空间的浪费。
因为需要额外的空间和计算开销,所以应该尽量只在对小数进行精确计算时才使用DECIMAL-例如存储财务数据。但在数据量比较大的时候,可以考虑使用 BIGIN代替DECIMAL,将需要存储的货币单位根据小数的位数乘以相应的倍数即可。假设要存储财务数据精确到万分之一分,则可以把所有金额乘以一百万,然后将结果存储在 BIGINT里,这样可以同时避免浮点存储计算不精确和 DECIMAL精确计算代价高的问题。
还有一个应用场景就是ip地址的存储,整型比字符串操作代价更低,因为字符集和校对规则(排序规则)使字符比较比整型更复杂。在mysql 中有两个函数,inet_aton() 和 inet_ntoa() ,这两个函数可以实现IP和数字间的转换,所以在存储ip地址的适用应考虑适用整数。
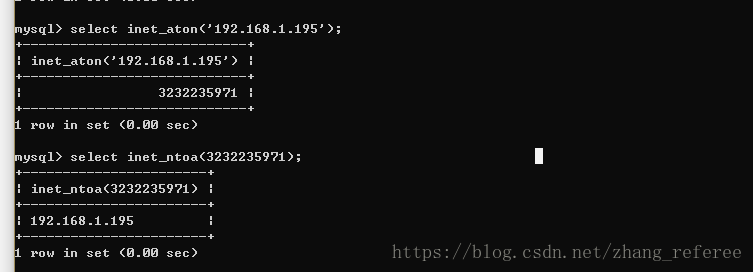
在PHP中可以使用,ip2long() 和 long2ip() 完成类似的操作。
-
4.尽量避免NULL
很多表都包含可为NULL(空值)的列,即使应用程序并不需要保存NUL也是如此,这是因为可为NULL是列的默认属性。通常情况下最好指定列为 NOT NULL,除非真的需要存储NULL值。
如果查询中包含可为NUL的列,对MYSQL来说更难优化,因为可为NULL的列使得索引、索引统计和值比较都更复杂。可为NUL的列会使用更多的存储空间,在MYSQL里也需要特殊处理。当可为NULL的列被索引时,每个索引记录需要一个额外的字节,在 MYISAM里甚至还可能导致固定大小的索引(例如只有一个整数列的索引)变成可变大小的索引。
通常把可为NUL的列改为 NOT NULL带来的性能提升比较小,所以(调优时)没有必要首先在现有 schema中査找并修改掉这种情况,除非确定这会导致问题。但是,如果计划在列上建索引,就应该尽量避免设计成可为NUL的列。
当然也有例外,例如值得一提的是, INNODB使用单独的位(bit)存储NUL值,所以对于稀疏数据(很多值为NULL,只有少数行的列有非NULL值)有很好的空间效率。但这一点不适用于 MYISAM。
当然以上原则只是一个参考 ,最主要还是根据业务来做相应的调整。