问题一:
怎么在海量数据中找出重复次数最多的一个
算法思想:
方案1:先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。
然后找出上一步求出的数据中重复次数最多的一个就是所求(如下)。
问题二:
网站日志中记录了用户的IP,找出访问次数最多的IP。
算法思想:
IP地址最多有2^32=4G种取值可能,所以不能完全加载到内存中。
可以考虑分而治之的策略;
map
按照IP地址的hash(IP)%1024值,将海量日志存储到1024个小文件中,每个小文件最多包含4M个IP地址。
reduce
对于每个小文件,可以构建一个IP作为key,出现次数作为value的hash_map,并记录当前出现次数最多的1个IP地址。
有了1024个小文件中的出现次数最多的IP,我们就可以轻松得到总体上出现次数最多的IP。
同样的问题:
假设有1kw个身份证号,以及他们对应的数据。身份证号可能重复,要求找出出现次数最多的身份证号。
补充问题:
如果是要找出前k个最大的呢?
类似问题:
有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
算法思想:
第一步、顺序读文件中,对于每个词x,取 ,然后按照该值存到5000个小文件(记为
,然后按照该值存到5000个小文件(记为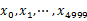 )中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
)中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
(第一步结束后,相同内容的词在同一个文件中,且文件比较小)
对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。
类似问题:
有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
算法思想:
顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为 )中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
找一台内存在2G左右的机器,依次对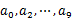 用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(b0,b1,b2,...,b9)。
用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(b0,b1,b2,...,b9)。
对(b0,b1,b2..,b9)这10个文件进行归并排序(内排序与外排序相结合)。