1、以下js 表达式返回false 的是
A 1==true
B “”==false
C false==null
D null==undefined
E NaN==NaN
F typeof NaN==="number"
解析:考察js中的隐式转换,js中==运算会自动进行类型转换。null,undefined,"".
有一个规则:布尔值true 和false 在==运算中会被转化为数值1和0 再进行比较。B中“”空字符串转化为数字为0,所以为true 。
typeof NaN 其中typeof 操作符返回字符串,且为“number”。所以F为true
选C、E
2、关于const说法错误的是
A 用于声明变量,声明后不可修改
B 不会发生变量提升线下
C可以先声明后赋值
D 同一作用域下不可以重复声明同一个变量
解析:const声明的变量只可以在声明时赋值,不可随意修改,否则会导致SyntaxError(语法错误)。
3、CSS3伪类的考察:
CSS3中的伪类如下:
| 新增伪类 | 作用 |
| p:first-of-type | 选择属于其父元素的首个<p>元素的每个<p>元素。 |
| p:last-of-type | 选择属于其父元素的最后<p>元素的每个<p>元素。 |
| p:only-of-type | 选择属于其父元素唯一的<p>元素的每个<p>元素。 |
| p:only-child | 选择属于其父元素唯一的子元素的每个<p>元素。 |
| p:nth-child(n) | 选择属于其父元素的第n个子元素的每个<p>元素。 |
| p:nth-last-child(n) | 选择属于其父元素的倒数第n个子元素的每个<p>元素。 |
| p:nth-of-type(n) | 选择属于其父元素第n个<p>元素的每个<p>元素。 |
| p:nth-last-of-type(n) | 选择属于其父元素倒数第n个<p>元素的每个<p>元素。 |
| p:last-child | 选择属于其父元素最后一个子元素的每个<p>元素。 |
| p:empty | 选择没有子元素的每个<p>元素(包括文本节点)。 |
| p:target | 选择当前活动的<p>元素。 |
| :not(p) | 选择非<p>元素的每个元素。 |
| :enabled | 控制表单控件的可用状态。 |
| :disabled | 控制表单控件的禁用状态。 |
| :checked | 单选框或复选框被选中。 |
4、 var[a,b,c]=[1,2]结果中a,b,c,的值分别是1,2,undefined
5、typeof [] 结果为object而不是array
使用typeof检测数据类型,首先,返回的是一个字符串。其次这个字符串包含了对应的类型,“number”、“string”、“boolean”、“undefined”、“function”、“object”共6类
6、以下代码输出结果为
var a=10;
var ary =new Array();
var tmp=new Date();
function f(){
console.log(ary);
console.log(tmp);
console.log(a);
if(false){
var tmp="hello world";
}
}f();
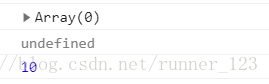
解析:变量a,用构造函数生成的数组都可以在函数内部访问到。获取时间new Date()时间的一个实例在函数 内部无法访问。
7、以下程序输出结果为
var foo="global";
var test={
foo:"inner",
get:function(){
var self=this;
console.log(this.foo);
console.log(self.foo);
(function(){
console.log(this.foo);
console.log(self.foo);
})();
}
};
test.get();
解析:前两个是局部变量,分别在函数内部取到foo 的值为inner。第三个是自执行函数,自身没有this指向,所以在window下找的全局变量,指的是global,第四个是因为get中把this存在了self变量里面,所以第四个指的是inner
8、某二叉树的中序遍历结点访问顺序是EDFBAGC,后序遍历的结点访问吮吸是EFDBCGA.则其前序遍历的结点访问顺序是 B
A ADBEFCG
B ABDEFGC
解析:前序遍历的规则是:根结点→左子结点→右子结点
中序遍历是:左子结点→根结点→右子结点
后序遍历是:左子结点→右子结点→根结点
后序遍历中最后一个结点是A,所以确定A为根节点,前序遍历第一个肯定是根节点。所以第一个为A。
中序:以A(根结点)为中点,左边是EDFB,右边是GC
对于左子树,EDFB来说,后序遍历的左子树为EFDB,可以确定这个左子树的根节点为B。左子结点为EDF,后序遍历为EFD,所以D为根节点,E为左子结点,F为右子节点。
对于右子树,中序遍历是GC,后序遍历为CG.所以根节点为G,C为G的右子结点。

所以前序遍历为:ABDEFGC
9 下面哪种方法属于不稳定排序?
A 冒泡排序
B 选择排序
C 插入排序
D 归并排序
解析:选择B
稳定的
冒泡排序(bubble sort) — O(n2)
鸡尾酒排序 (Cocktail sort, 双向的冒泡排序) — O(n2)
插入排序 (insertion sort)— O(n2)
桶排序 (bucket sort)— O(n); 需要 O(k) 额外 记忆体
计数排序 (counting sort) — O(n+k); 需要 O(n+k) 额外 记忆体
归并排序 (merge sort)— O(n log n); 需要 O(n) 额外记忆体
原地归并排序 — O(n2)
二叉树排序 (Binary tree sort) — O(n log n); 需要 O(n) 额外记忆体
鸽巢排序 (Pigeonhole sort) — O(n+k); 需要 O(k) 额外记忆体
基数排序 (radix sort)— O(n·k); 需要 O(n) 额外记忆体 Gnome sort — O(n2) Library sort — O(n log n) with high probability, 需要 (1+ε)n 额外记忆体
不稳定
选择排序 (selection sort)— O(n2)
希尔排序 (shell sort)— O(n log n) 如果使用最佳的现在版本 Comb sort — O(n log n)
堆排序 (heapsort)— O(n log n) Smoothsort — O(n log n)
快速排序 (quicksort)— O(n log n) 期望时间, O(n2) 最坏情况; 对於大的、乱数串列一般相信是最快的已知排序 Introsort — O(n log n) Patience sorting — O(n log n + k) 最外情况时间, 需要 额外的 O(n + k) 空间, 也需要找到最长的递增子序列(longest increasing subsequence)
10 在请求分页系统中,LRU算法是指(A)
A 近期最长时间以来没被访问的页先淘汰
B 最早进入内存的页先淘汰、
C 近期访问次数最少的页先淘汰
D 以后再也不用的页先淘汰
解析:LRU是操作系统页面调度算法中最近最久没有使用调度算法的缩写。也就是在最近最长时间没有被使用的页面将首先被淘汰,调度出内存。
11 、编程题
给定一个长度为n的不下降数组,判断是否存在两个不同元素和为m,输出true 和false
测试用例:输入两个正整数n,m。然后输入n个元素表示长度为n 的数组
input 10 10
0 1 2 3 4 5 6 7 8 9
output true
input 10 19
0 1 2 3 4 5 6 7 8 9 (加起来没有19)
output false
编程如下:
var btn=document.getElementById("btn");
btn.onclick=function(){
var ary=document.getElementById("ary").value.split(",");
var m=document.getElementById("m").value;
var result=parseInt(m);
var flag;
for(var i=0;i<ary.length;i++){
for(var j=ary.length-1;j>0;j--){
if(i>=j){
break;
}else{
var sum=parseInt(ary[i])+parseInt(ary[j]);
console.log(sum);
if(sum===result){
alert(true);
break;}
else{ alert(false);
break;}
}
}
}
}