解释分布式事物之前,我们先来说说什么是"事物”;
一、我们先简单了解下”事物“的四大特性:
事物的4大特性(这里我主要以简单通俗的例子解释这4个特性),也叫acid特性:
原子性(atomicity):就是一个方法中的操作,要么全做,要么全不做,不存在做一半的情况,以经典的转账为例:张三向李四转账1000元,那么转账的操作可以分为2步,第一步:张三账户扣1000元,第二步:李四账户加1000元;这里的原子性就是以上的2步转账操作要么全部执行,要么全部不执行;
一致性(Consistency):一致性和原子性其实是相辅相成的,还是以上面的转账为例,一致性是指:如果张三账户扣了1000元,那么李四的账户必须加1000元,如果张三账户扣1000失败,那么李四账户必须不能加1000元,这2个账户之间必须保证一致性;
隔离性:就是多个用户操作同一数据库的同一张表时,要彼此独立,不能相互干扰,这里又涉及到了数据库的隔离级别,这里可以看我的另一篇博文(https://blog.csdn.net/chengkui1990/article/details/81035358):;
持久性:数据库操作一旦执行成功,就必须永久保存下来,不能丢失;
在之前的单体应用中,利用数据库的回滚机制,能很好的支持”事物“,还是以A像B转账1000元为例子,第一步:从A的账户扣除1000元(减少数据库A账户的金额1000元),第二步:往B的账户增加1000元(增加数据库B账户的金额1000元),上面2次操作是在同一个应用中完成的,使用的是同一个数据库,所以利用数据库的回滚机制是很容易实现”事物“的;
但是如果是微服务架构的系统呢,例如此时是一个跨行转账,A账户和B账户不是同一家银行,那么肯定也不是一个数据库,那么转账的步骤就是下面这样的步骤:先从A账户扣除1000元,然后发一条请求给B银行请求增加B账户1000元的请求,因为A账户和B账户不是一个数据库,所以不能用数据库事物机制去保证这2步的事物特性,分布式事物就能解决上面遇见的这个难题;
”分布式事物“:个人理解就是为了解决分布式系统之间相互调用无法保证”事物“特性而产生的;
二、分布式事物的几种解决方案:
1、补偿事物:补偿事物就是当需要事物执行的某一步发生错误时,业务添加补偿(回滚)机制,以A像B转账为例子,如果第一步:A账户扣除1000元成功,第二步:B账户增加1000元失败,那么需要增加补偿机制的一步:往A账户增加1000元,下面以伪代码实现;
public void transfer(){
//A账户扣除100元
A.del(100);
//B账户增加100元
boolean result = B.add(100);
//如果B账户增加失败,那么A账户必须增加100元,
if(result != "success"){
A.add(100)
}
}但是上面的补偿机制有几个缺陷,第一:只有明确B账户增加失败才能执行补偿机制,如果由于网络原因或者其它原因没有收到B账户的返回信息呢,那么此时我们就不知道B账户执行到底是失败还是成功,那我们就不能贸然的执行补偿事物,这会可能会导致转账的不一致性;第二:如果有多个外部调用,那么就要写多个补偿机制,这会导致代码非常繁琐,容易出错且难以维护;
2、本地消息表:本地消息表一般是保证事物的最终一致性,是异步执行的,以转账为例,将A账户扣除1000元后就必须像数据库里插入一条B账户增加1000元的消息通知,这2步骤是在本地事物中进行的,是能保证事物的,然后异步的执行插入的事物通知,直到B账户增加了1000元并返回成功后,这条消息通知才能置为成功,本地消息表实现分布式事物会导致消息表耦合到业务代码中去,会有很多的繁琐的后续处理操作;
3、两阶段提交:
两阶段提交顾名思义就是提交分为2个阶段,第一个阶段成为准备阶段,第二阶段称为提交阶段,两阶段提交的执行原理:
两阶段提交的执行需要2个角色支持:事物的协调者和参与者两部分组成,第一阶段,协调者像所有的参与者发送提交的请求,等待参与者的回应;第二阶段:如果所有的参与者都返回成功,则协调者发送真正的提交的请求,所有参与者返回成功则事物完成,如果任何一个参与者返回失败,则协调者发送回滚请求,所有参与者返回成功则回滚完成;
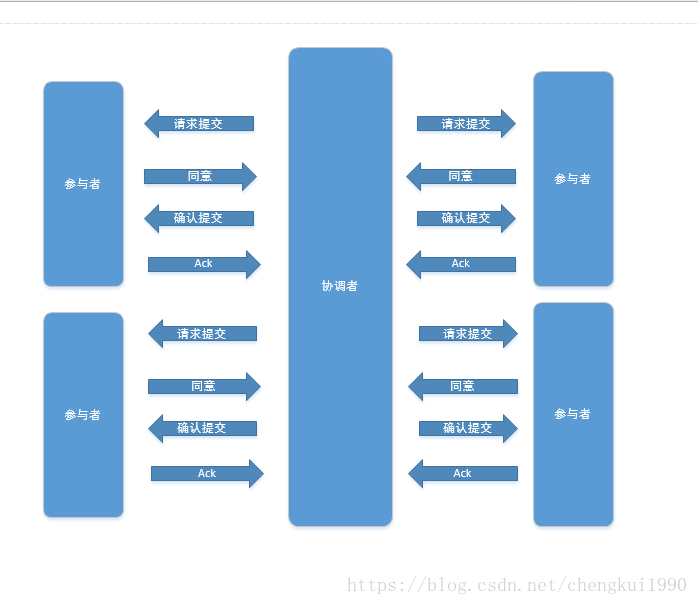
当所有参与者全部同意提交时的;
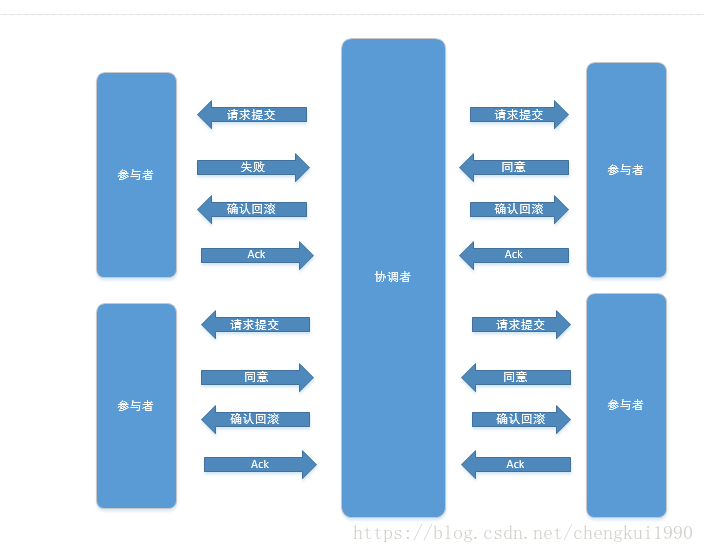
当有一个参与者或者以上不同意(失败时);
其实在请求提交的阶段,各个参与者已经执行了事物操作,包括锁住必须的资源,只是事物还没有提交,”万事具备,只欠协调者的一个确认“,如果此时接收到的是来自协调者的确认提交操作,则进行最后的事物提交,如果接收的是回滚操作,则进行事物的回滚;
二阶段提交的几个缺点:
1、同步阻塞问题。执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
2、单点故障。由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
3、数据不一致。在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据部一致性的现象。
4、二阶段无法解决的问题:协调者再发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。