redis介绍
redis作为一个开源的kv数据库在互联网公司被广泛应用。
作为nosql的一员redis有这几个优点:
- KV存储
- 支持多种数据结构
- 全内存存储
- 持久化
- 主从复制
- 集群模式
- 社区活跃,文档齐全
事物都不是完美的,redis也有不少缺点:
- 2.x时代原生的故障自动转移恢复功能比较弱(senteinel出现的还比较晚)
- 在线扩容,缩容麻烦
- 主从复制采用全量复制的方式(2.8x之前使用fsync,2.8x之后使用psync)
- 如果单实例数据量过大,遭遇雪崩,重启恢复数据很痛苦
redis代理介绍
为了解决上述的缺点,互联网公司主要提出了三种类型的技术
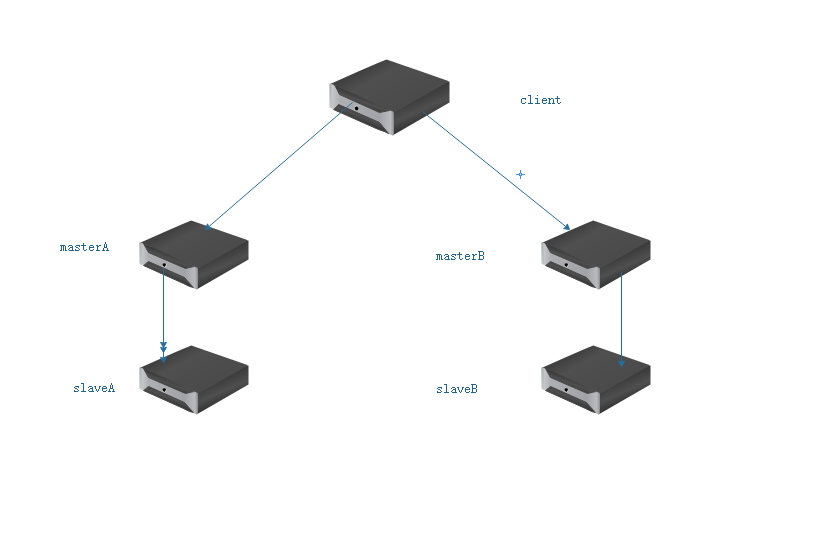
1.客户端分片
特点:
由客户端自己计算key在哪个机器上存储和查找,和后端服务器没有什么关系,降低了redis server集群的复杂度,增加了开发的难度。
缺点:
但是客户端要实时知道,集群节点的信息状态,新增节点的时候客户端要支持动态的sharding,但是多数客户端不支持,因此没有大规模使用。
客户端分片图例
2.代理分片
此方式是借助一个代理服务器实现数据分片,客户端直接与proxy联系,proxy计算集群节点信息,并把请求发送到对应的集群节点。
代表应用:
- twemproxy
- codis
twemproxy
twitter 开发。它主要通过事件驱动模型来达到高并发,每收到一个请求,通过解析请求,发送请求到后端服务,再等待回应,发送回请求方。有这几个特点:
- 事件驱动模型
- 三种分片算法
- C语言开发
- 支持大部分redis命令
- 配置简单
- 支持状态监控
架构图(来源于网络) 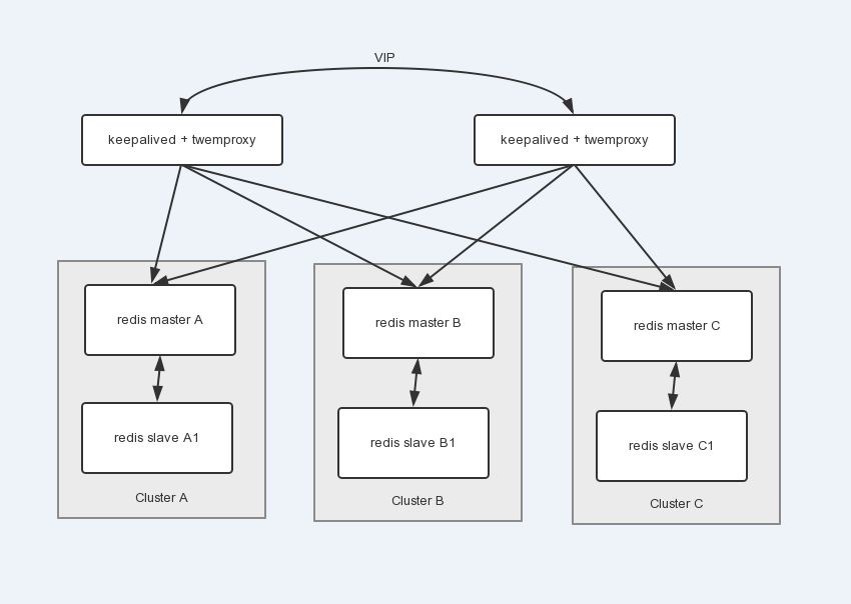
由于twemprox本身是单点的因此 经常和高可用软件搭配使用
配置示例:
xxxx:
listen: 127.0.0.1:4097
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
server_retry_timeout: 2000
server_failure_limit: 1
servers:
- 127.0.0.1:6378:1
distribution:为一致性哈希算法
servers:为后端缓存服务,twemproxy可以预先连接每个server或者不,根据接收到的请求具体分析出key,然后根据key来选择适当的server。
twemproxy使用要点:
- 合理设置twemproxy请求redis的timeout参数
- 对缓存和存储服务,分别设置redis eject策略
- 根据数据大小设置mbuf的大小
- pipeline请求不宜过大,过大导致twemproxy申请大量的内存空间
- 跨机房注意client-output-buffer-limit normal &&client-output-buffer-limit slave
codis
codis 由豌豆荚的团队编写,也是采用代理分片的技术。
- Go语言编写
- 相比twemproxy 限制少,支持动态扩容缩容。
- 有管理界面,对后期维护友好
- 依赖ZK
- Codis-proxy不支持热重启
架构图(来源于网络) 
Codis组件:
- Codis Server: 就是后端的redis
- Codis Proxy: 客户端链接reids的代理组件,实现redis协议
- Dashboard 集群的管理工具
- Admin: 集群管理的命令行工具。
- FE: 集群管理界面。
- ZooKeeper : 存放数据路由表和codis-proxy节点的元信息
Codis怎么分片?
Codis 采用 Pre-sharding 的技术来实现数据的分片, 默认分成 1024 个 哈希槽。其实就是预分片,将这些分布式状态保存在ZK中,最大后端支持1024个redis server。另外每个哈希槽必须有个对应的组id,数据迁移和redis cluster 一样由哈希槽为单位。
3.服务端分片
客户端随意与集群中的任何节点通信,服务器端负责计算某个key在哪个机器上,当客户端访问某台机器时,服务器计算对应的key应该存储在哪个机器,然后把结果返回给客户端,客户端再去对应的节点操作key,是一个重定向的过程,目前官方的Redis Cluster 集群支持
特点:
- 无中心架构
- 数据按照s哈希槽存储分布在多个redis实例上
- 实现故障自动转移
- 集群内部增加slave做数据副本,用于集群快速恢复
- 可手动踢出节点,为升级和迁移提供可操作方案
Redis Cluster 如何分片?
采用CRC16(key) % 16384 来计算键 key 属于哪个槽,其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和。
如何进行故障转移?
当主节点down掉之后,选举出一个从成为新的主
被选中的从执行slave no one 成为新的主
新主撤销down掉主的哈希槽指派,把这些哈希槽指派给自己
新主和集群其他节点进行通信,广播自己是主了
新主开始接收请求和哈希槽指派
如何选举?
从在集群中属于冷备,读写请求都不会发往从节点。
从发现自己的主down掉之后,会广播一条 cluster_type_fallover_auth_reqeust的消息,要求其他的主节点给自己投票
其他收到主节点并且还没投票的情况下会把票投给他,返回一个cluster_type_fallover_auth_ack的消息,就是钦定他
当集群中n/2+1的数量的投票从就成为主。
这个选举周期没选成,就下一个周期重新开始
对比

安装redis 需要注意的几个参数
系统参数
vm.overcommit_memory = 1
net.core.somaxconn = 8192 同配置的backlog
echo never > /sys/kernel/mm/transparent_hugepage/enabled
配置参数
Maxmemory 102400mb/10gb
timeout 180
tcp-keepalive 300
repl-backlog-size 32M #psync初始大小
client-output-buffer-limit normal 512mb 256mb 60
client-output-buffer-limit slave 1024mb 256mb 120