版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_38230811/article/details/83042260
K-means
1The centroids of the K clusters, which can be used to label new data
2labels for the training data (each data point is assigned to single cluster)
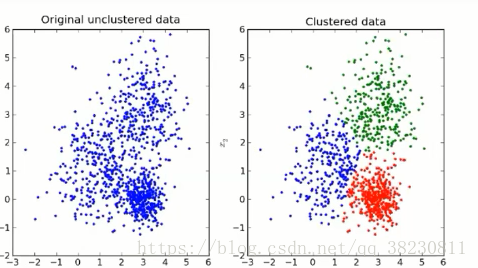

- 选择要使用的中心数k
- 随机选择k个中心
- 计算每个点到每个中心的距离
- 每个点都与它最接近的中心相关联
- 这些中心点被重新定位,以便位于所有点的中心
- 前两个步骤重复进行,直到实现收敛
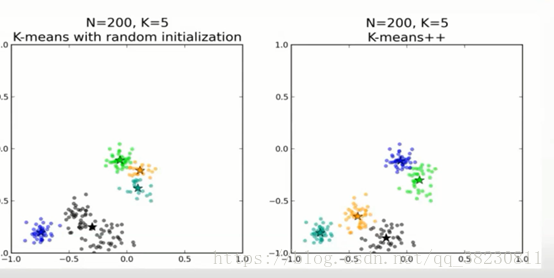
K-means++
离所有选过点越远的点被选为下个中心点的概率越大(提高找中心点的效率)
K-NN
K- nearest neighbors (k最近邻)


这个方法 由于划分不同 可能会出现不同的结果