JDK5.0以后提供了多种并发类容器来替代同步容器类从而改善性能。同步类容器状态都是串行化的。他们虽然实现了线程安全,但是严重降低了并发性,在多线程环境时,严重降低了应用程序的吞吐量。
ConcurrentMap接口
ConcurrentMap接口有两个重要的实现类:ConcurentHashMap、ConcurrentSkipListMap(支持并发排序功能)。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的HashTable,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。把一个整体分成16个段(Segment),也就是最高支持16个线程的并发修改操作。这是在多线程场景时减小锁粒度从而降低锁竞争的一种方案。
同样的,为了对比HashMap和ConcurrentMap,我们照上一节的例子来写测试用例:
public class UseHashMap {
public static void main(String[] args) {
Map<String, Object> map = new HashMap<String, Object>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
map.put("4", "value4");
map.put("5", "value5");
map.put("6", "value6");
map.put("7", "value7");
map.put("8", "value8");
map.put("9", "value9");
map.put("10", "value10");
System.out.println(map);
Iterator<String> it = map.keySet().iterator();
while(it.hasNext()) {
String key = it.next();
if("3".equals(key)) {
// map.put(key, "Hello Me.");
map.put("three", "three");
}
}
System.out.println(map);
}
}
上述代码的在HashMap中放入了10个key和与之对应的value。循环迭代时当key等于3的时候,就想map中放入键值对three/three。不出意外,该代码同样会抛出:
Exception in thread "main" java.util.ConcurrentModificationException
换成并非容器类ConcurrentHashMap之后的解决了线程安全的问题。
public class UseConcurrentHashMap {
public static void main(String[] args) {
Map<String, Object> map = new ConcurrentHashMap<String, Object>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
map.put("4", "value4");
map.put("5", "value5");
map.put("6", "value6");
map.put("7", "value7");
map.put("8", "value8");
map.put("9", "value9");
map.put("10", "value10");
System.out.println(map);
Iterator<String> it = map.keySet().iterator();
while(it.hasNext()) {
String key = it.next();
if("3".equals(key)) {
map.put(key+"new", "Hello Me.");
}
}
System.out.println(map);
}
}
控制台输出:
{1=value1, 2=value2, 3=value3, 4=value4, 5=value5, 6=value6, 7=value7, 8=value8, 9=value9, 10=value10}
{1=value1, 2=value2, 3=value3, 4=value4, 5=value5, 3new=Hello Me., 6=value6, 7=value7, 8=value8, 9=value9, 10=value10}
我们发现,已经成功的将key/value放进了map中。
CopyOnWrite类
CopyOnWrite从字面的意思来理解便是写时复制,意思是当有线程对容器内容进行写的操作的时候,并不是直接在该容器里进行写操作,而是先将容器复制一份,再在这份复制出来的容器里面进行数据的修改,修改结束之后再将原容器的引用指向这个修改过后的新容器,这是一种典型的读写分离思想。
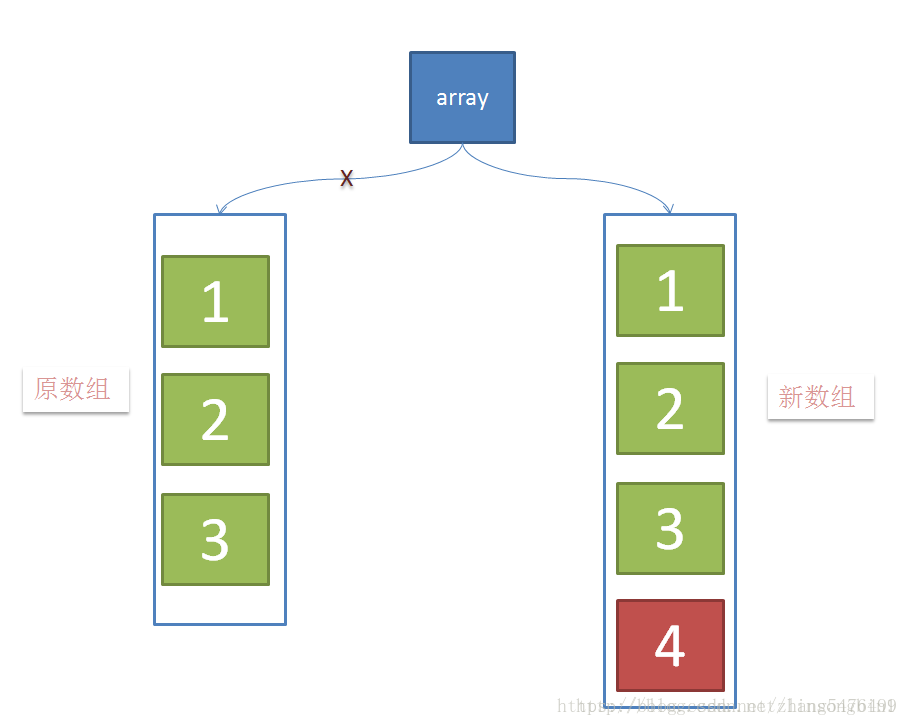
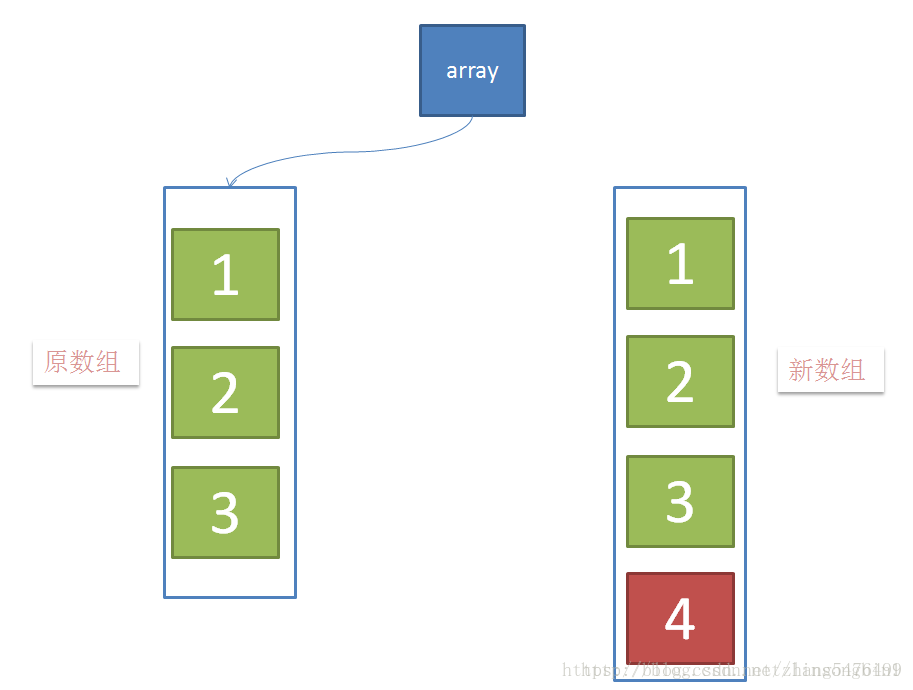
借用其他博主的示意图如下:
当有新元素加入的时候,创建新数组,并往新数组中加入一个新元素,这个时候,array这个引用仍然是指向原数组的。
当元素在新数组添加成功后,将array这个引用指向新数组。
这样做是为了避免在多线程并发add的时候,复制出多个副本出来,把数据搞乱了,导致最终的数组数据不是我们期望的。我们以CopyOnWrite具体实现类CopyOnWriteArrayList为例子来看看
public class UseCopyOnWriteArrayList {
public static void main(String[] args) throws InterruptedException {
List<String> a = new ArrayList<String>();
a.add("a");
a.add("b");
a.add("c");
final CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<String>(a);
Thread t = new Thread(new Runnable() {
int count = 1;
@Override
public void run() {
while(true) {
list.add(count++ + "");
}
}
});
t.setDaemon(true);
t.start();
Thread.currentThread().sleep(3);
for(String s : list) {
System.out.println(list.hashCode());
System.out.println(s);
}
}
}
同样的这里给出非并发容器ArrayList来作为对比。
public class UseArrayList {
public static void main(String[] args) throws InterruptedException {
List<String> a = new ArrayList<String>();
a.add("a");
a.add("b");
a.add("c");
final ArrayList<String> list = new ArrayList<String>(a);
Thread t = new Thread(new Runnable() {
int count = -1;
@Override
public void run() {
while (true) {
list.add(count++ + "");
}
}
});
t.setDaemon(true);
t.start();
Thread.currentThread().sleep(3);
for (String s : list) {
System.out.println(s);
}
}
}
明显的ArrayList抛出了经典的ConcurrentModificationException异常,这点无需赘述,重点是来看一下ConcurrentHashMap的控制台输出:
913471290
a
-1547941244
b
-1175691689
c
265472996
1
1516781777
2
-297067907
3
367817044
4
1723169514
5
-1090557824
6
1451129615
7
-298489538
8
-24239701
9
1150538634
10
1356089445
11
488770731
这里有两个线程,第一个线程是main函数所在的主线程,用来循环遍历该map的内容,另一个线程是不断的向容器中新增自增变量count,从循环遍历输出的hashcode值可以看到:主线程不断的循环遍历的list并不是同一个list,因为它们的hash值不相同。
需要注意的是:
- 读的操作是不需要加锁,但是写的时候是需要加锁,当多个线程同时进行写的操作时,只有当当前线程写操作结束之后才能释放锁给其他线程使用,所以COW使用于读多写少的操作。
- COW只能保证结果的一致性,不能保证操作过程中数据的一致性。
- COW很好的解决并发性能的同时,可能耗费了一定的内存,因为在add操作中开辟了一段空间和存储原来的副本。