多线程下载介绍
多线程下载技术是很常见的一种下载方案,这种方式充分利用了多线程的优势,在同一时间段内通过多个线程发起下载请求,将需要下载的数据分割成多个部分,每一个线程只负责下载其中一个部分,然后将下载后的数据组装成完整的数据文件,这样便大大加快了下载效率。常见的下载器,迅雷,QQ旋风等都采用了这种技术。
实现方案
原理很清楚,但是其中涉及到两个关键问题:
需要请求的数据如何分段。
分段下载的数据如何组装成完整的数据文件。
要解决这两个问题,需要掌握下面两个知识点。
Range范围请求
Range,是在 HTTP/1.1里新增的一个 header field,它允许客户端实际上只请求文档的一部分,或者说某个范围。
有了范围请求,HTTP 客户端可以通过请求曾获取失败的实体的一个范围(或者说一部分),来恢复下载该实体。当然这有一个前提,那就是从客户端上一次请求该实体到这次发出范围请求的时段内,该对象没有改变过。例如:
GET /bigfile.html HTTP/1.1
Host: www.joes-hardware.com
Range: bytes=4000-
User-Agent: Mozilla/4.61 [en] (WinNT; I)上述请求中,客户端请求的是文档开头 4000 字节之后的部分(不必给出结尾字节数,因为请求方可能不知道文档的大小)。在客户端收到了开头的 4000 字节之后就失败的情况下,可以使用这种形式的范围请求。还可以用 Range 首部来请求多个范围(这些范围可以按任意顺序给出,也可以相互重叠)。例如,假设客户端同时连接到多个服务器,为了加速下载文档而从不同的服务器下载同一个文档的不同部分。对于客户端在一个请求内请求多个不同范围的情况,返回的响应也是单个实体,它有一个多部分主体及 Content-Type: multipart/byteranges 首部。
Range头域使用形式如下。例如:
表示头500个字节:bytes=0-499
表示第二个500字节:bytes=500-999
表示最后500个字节:bytes=-500
表示500字节以后的范围:bytes=500-
第一个和最后一个字节:bytes=0-0,-1 如果客户端发送的请求中Range这个值存在而且有效,则服务端只发回请求的那部分文件内容,响应的状态码变成206,表示Partial Content,并设置Content-Range。如果无效,则返回416状态码,表明Request Range Not Satisfiable如果不包含Range的请求头,则继续通过常规的方式响应。
比如某文件的大小是 1000 字节,client 请求这个文件时用了 Range: bytes=0-500,那么 server 应该把这个文件开头的 501 个字节发回给 client,同时回应头要有如下内容:Content-Range: bytes 0-500/1000,并返回206状态码。
并不是所有服务器都接受范围请求,但很多服务器可以。服务器可以通过在响应中包含 Accept-Ranges 首部的形式向客户端说明可以接受的范围请求。这个首部的值是计算范围的单位,通常是以字节计算的。
随机访问文件RandomAccessFile类
RandomAccessFile适用于由大小已知的记录组成的文件,所以我们可以使用seek()将记录从一处转移到另一处,然后读取或修改记录。
随机访问文件的行为类似存储在文件系统中的一个大型 byte 数组。存在指向该隐含数组的光标或索引,称为文件指针;输入操作从文件指针开始读取字节,并随着对字节的读取而前移此文件指针。如果随机访问文件以读取/写入模式创建,则输出操作也可用;输出操作从文件指针开始写入字节,并随着对字节的写入而前移此文件指针。写入隐含数组的当前末尾之后的输出操作导致该数组扩展。该文件指针可以通过 getFilePointer 方法读取,并通过 seek 方法设置。
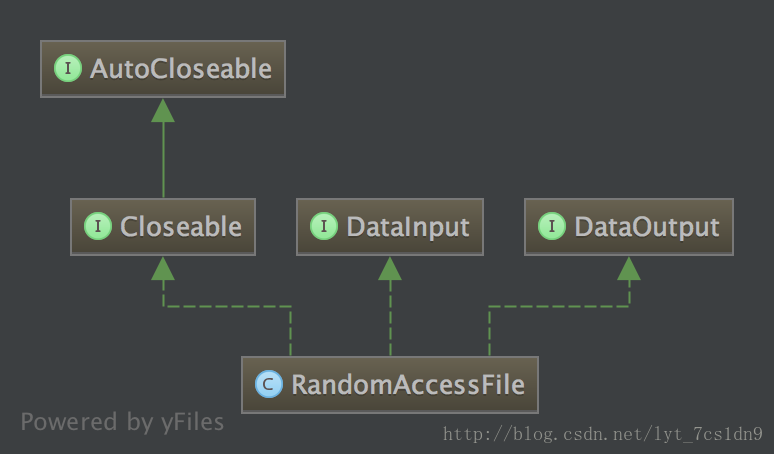
RandomAccessFile虽然位于Java.io包中,但从RandomAccessFile类的层级结构来看,它并不是InputStream或者OutputStream继承层次结构中的一部分。除了实现了DataInput和DataOutput接口(DataInputStream和DataOutputStream也实现了这两个接口),它和这个两个继承层次结构没有任何关联。它甚至不适用InputStream和OutputStream类中已有的任何功能。它是一个完全独立的类,从头开始编写其所有的方法(大多数都是native的)。这么做是因为RandomAccessFile拥有和别的I/O类型本质不同的行为,我们可以通过它在一个文件内向前和向后移动。在任何情况下,它都是自我独立的,直接派生自Object类。
本质上来说,RandomAccessFile的工作方式类似于把DataInputStream和DataOutStream组合起来使用,还添加了一些方法。
以下是一些比较重要的方法。
构造方法RandomAccessFile
public RandomAccessFile(File file, String mode) throws FileNotFoundException创建从中读取和向其中写入(可选)的随机访问文件流,该文件由 File 参数指定。将创建一个新的 FileDescriptor 对象来表示此文件的连接。
mode 参数指定用以打开文件的访问模式。允许的值及其含意为:
“r“——以只读方式打开。调用结果对象的任何 write 方法都将导致抛出 IOException。
“rw“——打开以便读取和写入。如果该文件尚不存在,则尝试创建该文件。
“rws“—— 打开以便读取和写入,对于 “rw”,还要求对文件的内容或元数据的每个更新都同步写入到底层存储设备。
“rwd“——打开以便读取和写入,对于 “rw”,还要求对文件内容的每个更新都同步写入到底层存储设备。
getFilePointer
public native long getFilePointer() throws IOException;返回此文件中的当前偏移量,以字节为单位。
length
public native long length() throws IOException;返回此文件的长度。
setLength
public native void setLength(long newLength)
throws IOException设置此文件的长度。
seek
public native void seek(long pos)
throws IOException设置到此文件开头测量到的文件指针偏移量,在该位置发生下一个读取或写入操作。
write
public void write(byte[] b,int off,int len) throws IOException将 len 个字节从指定 byte 数组写入到此文件,并从偏移量 off 处开始。
RandomAccessFile类特殊之处在于支持搜寻方法,并且只适用于文件,这种随机访问特性,为多线程下载提供了文件分段写的支持。
需要注意的是,在RandomAccessFile的大多函数均是native的,在JDK1.4之后,RandomAccessFile大多数功能由nio存储映射文件所取代。所谓存储映射文件,简单来说 是由一个文件到一块内存的映射。内存映射文件与虚拟内存有些类似,通过内存映射文件可以保留一个地址空间的区域,同时将物理存储器提交给此区域,内存文件映射的物理存储器来自一个已经存在于磁盘上的文件,而且在对该文件进行操作之前必须首先对文件进行映射。使用内存映射文件处理存储于磁盘上的文件时,将不必再对文件执行I/O操作,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。有了内存映射文件,我们就可以假定整个文件都放在内存中,而且可以完全把它当做非常大的数组来访问。
了解了上面两个知识点,下面看一下多线程下载的具体实现。
多线程下载代码实现
MutiThreadDownLoad.java
import java.io.InputStream;
import java.io.RandomAccessFile;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.concurrent.CountDownLatch;
/**
* 多线程下载模型
*
* @author bridge
*/
public class MutiThreadDownLoad {
/**
* 同时下载的线程数
*/
private int threadCount;
/**
* 服务器请求路径
*/
private String serverPath;
/**
* 本地路径
*/
private String localPath;
/**
* 线程计数同步辅助
*/
private CountDownLatch latch;
public MutiThreadDownLoad(int threadCount, String serverPath, String localPath, CountDownLatch latch) {
this.threadCount = threadCount;
this.serverPath = serverPath;
this.localPath = localPath;
this.latch = latch;
}
public void executeDownLoad() {
try {
URL url = new URL(serverPath);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setRequestMethod("GET");
int code = conn.getResponseCode();
if (code == 200) {
//服务器返回的数据的长度,实际上就是文件的长度,单位是字节
int length = conn.getContentLength();
System.out.println("文件总长度:" + length + "字节(B)");
RandomAccessFile raf = new RandomAccessFile(localPath, "rwd");
//指定创建的文件的长度
raf.setLength(length);
raf.close();
//分割文件
int blockSize = length / threadCount;
for (int threadId = 1; threadId <= threadCount; threadId++) {
//第一个线程下载的开始位置
int startIndex = (threadId - 1) * blockSize;
int endIndex = startIndex + blockSize - 1;
if (threadId == threadCount) {
//最后一个线程下载的长度稍微长一点
endIndex = length;
}
System.out.println("线程" + threadId + "下载:" + startIndex + "字节~" + endIndex + "字节");
new DownLoadThread(threadId, startIndex, endIndex).start();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 内部类用于实现下载
*/
public class DownLoadThread extends Thread {
/**
* 线程ID
*/
private int threadId;
/**
* 下载起始位置
*/
private int startIndex;
/**
* 下载结束位置
*/
private int endIndex;
public DownLoadThread(int threadId, int startIndex, int endIndex) {
this.threadId = threadId;
this.startIndex = startIndex;
this.endIndex = endIndex;
}
@Override
public void run() {
try {
System.out.println("线程" + threadId + "正在下载...");
URL url = new URL(serverPath);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
//请求服务器下载部分的文件的指定位置
conn.setRequestProperty("Range", "bytes=" + startIndex + "-" + endIndex);
conn.setConnectTimeout(5000);
int code = conn.getResponseCode();
System.out.println("线程" + threadId + "请求返回code=" + code);
InputStream is = conn.getInputStream();//返回资源
RandomAccessFile raf = new RandomAccessFile(localPath, "rwd");
//随机写文件的时候从哪个位置开始写
raf.seek(startIndex);//定位文件
int len = 0;
byte[] buffer = new byte[1024];
while ((len = is.read(buffer)) != -1) {
raf.write(buffer, 0, len);
}
is.close();
raf.close();
System.out.println("线程" + threadId + "下载完毕");
//计数值减一
latch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}测试类
package MutiThreadDown;
import java.util.concurrent.CountDownLatch;
/**
* @author bridge
*/
public class Client {
public static void main(String[] args) {
int threadSize = 4;
String serverPath = "http://file.ws.126.net/3g/client/netease_newsreader_android.apk";
String localPath = "NewsReader.apk";
CountDownLatch latch = new CountDownLatch(threadSize);
MutiThreadDownLoad m = new MutiThreadDownLoad(threadSize, serverPath, localPath, latch);
long startTime = System.currentTimeMillis();
try {
m.executeDownLoad();
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println("全部下载结束,共耗时" + (endTime - startTime) / 1000 + "s");
}
}运行结果
文件总长度:22848007字节(B)
线程1下载:0字节~5712000字节
线程1正在下载...
线程2下载:5712001字节~11424001字节
线程2正在下载...
线程3下载:11424002字节~17136002字节
线程3正在下载...
线程4下载:17136003字节~22848007字节
线程4正在下载...
线程2请求返回code=206
线程1请求返回code=206
线程4请求返回code=206
线程3请求返回code=206
线程3下载完毕
线程2下载完毕
线程4下载完毕
线程1下载完毕
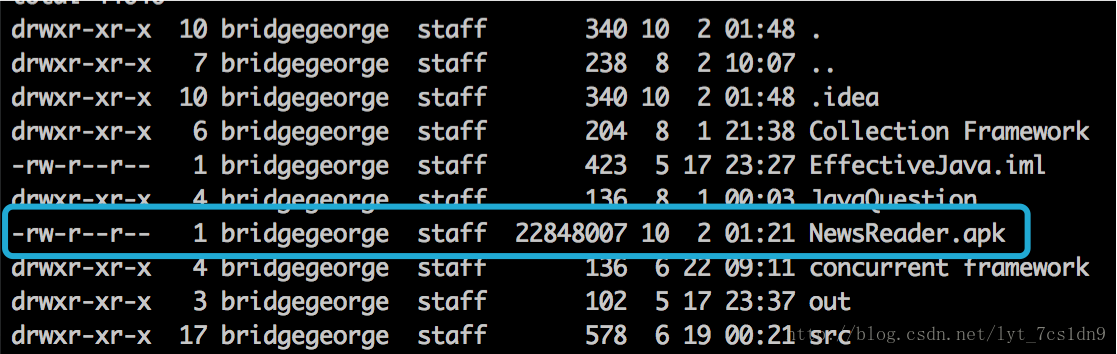
全部下载结束,共耗时5s上面的例子,采取4个线程同时下载了网易新闻Android客户端安装包,可以看到成功获取到了文件。
抓包分析验证
采用抓包工具对上述多线程下载过程进行分析,windows上可以采用wireShark,Mac 上可以用Charles,以下是对一次多线程下载的抓包过程。

可以看到本次多线程下载共发起了5次请求,其中第一次请求用于取得文件大小,其余4次用于用于多线程下载文件。可以看到4个线程同时发起请求,
线程1的请求报文如下
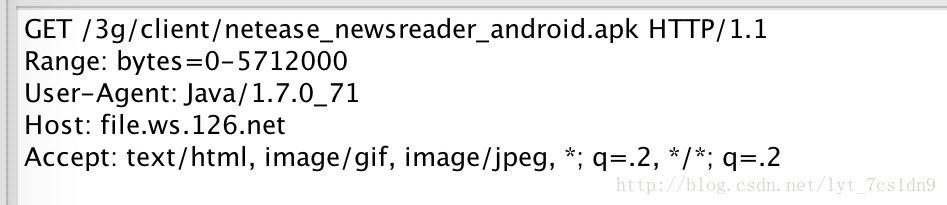
可以看到Range字段标识了此次请求只获取0-5712000的文档数据。
服务器的响应报文如下
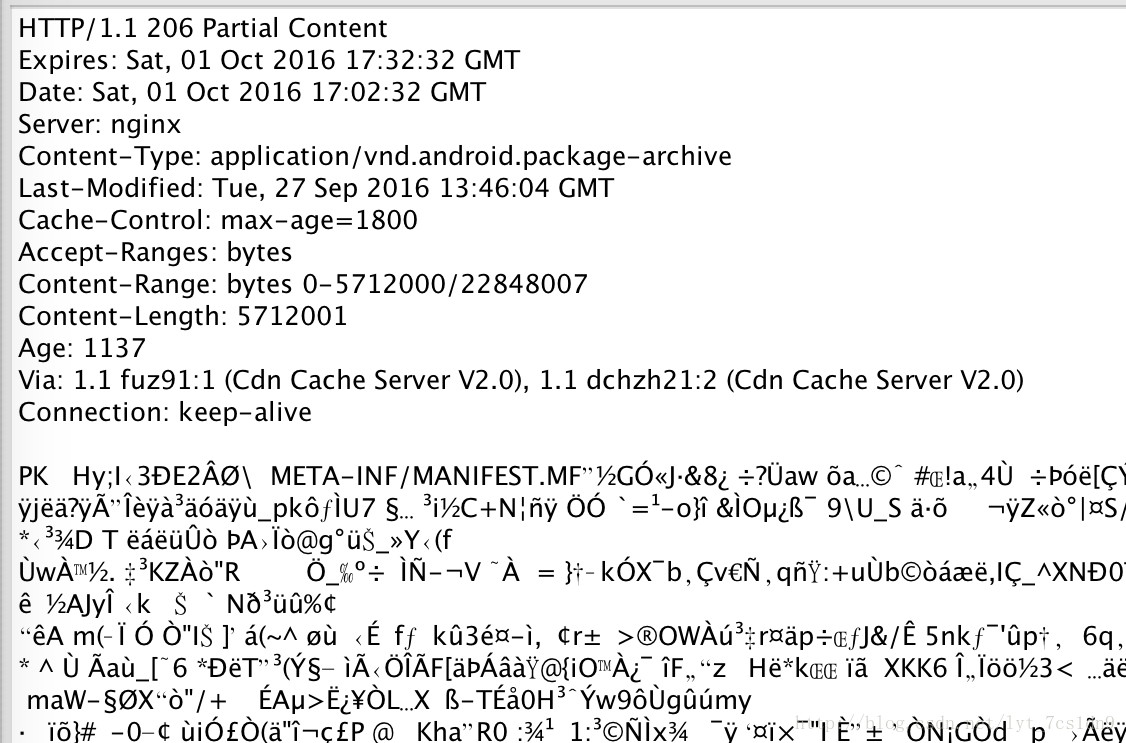
可以看到服务器响应报文的内容中,状态行Partial Content 标识了此次请求为范围请求,响应内容为部分内容。
Content-Length:5712001标识此次返回的内容长度,
Content-Range:bytes 0-5712000/22848007标识了它提供了请求实体所在的原始实体内的位置(范围),还给出了整个实体的长度。
参考资料
《Java 编程思想》
《HTTP 权威指南》